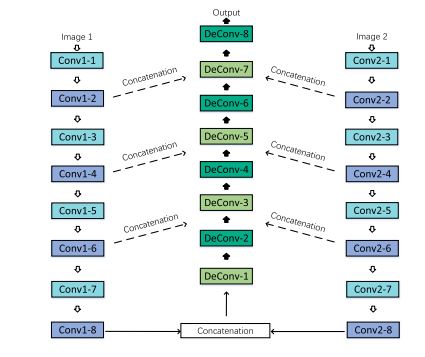
HI, when I test this code this message is displayed:
import torch
import torch.nn as nn
import torch.nn.functional as functional
from configure import Config
import pdb
from Ncuts import NCutsLoss
config = Config()
class WNet(torch.nn.Module):
def __init__(self):
super(WNet, self).__init__()
self.feature1 = []
self.feature2 = []
bias = True
#U-Net1
#module1
self.module = []
self.maxpool1 = []
self.uconv1 = []
self.module.append(
self.add_conv_stage(config.ChNum[0],config.ChNum[1],config.ConvSize,padding=config.pad,seperable=False)
)
#module2-5
for i in range(2,config.MaxLv+1):
self.module.append(self.add_conv_stage(config.ChNum[i-1],config.ChNum[i],config.ConvSize,padding=config.pad))
#module6-8
for i in range(config.MaxLv-1,1,-1):
self.module.append(self.add_conv_stage(2*config.ChNum[i],config.ChNum[i],config.ConvSize,padding=config.pad))
#module9
self.module.append(
self.add_conv_stage(2*config.ChNum[1],config.ChNum[1],config.ConvSize,padding=config.pad,seperable=False)
)
#module1-4
for i in range(config.MaxLv-1):
self.maxpool1.append(nn.MaxPool2d(config.ScaleRatio))
#module5-8
for i in range(config.MaxLv,1,-1):
self.uconv1.append(nn.ConvTranspose2d(config.ChNum[i],config.ChNum[i-1],config.ScaleRatio,config.ScaleRatio,bias = True))
self.predconv = nn.Conv2d(config.ChNum[1],config.K,1,bias = bias)
self.pad = nn.ConstantPad2d(config.radius-1,0)
self.softmax = nn.Softmax2d()
self.module = torch.nn.ModuleList(self.module)
self.maxpool1 = torch.nn.ModuleList(self.maxpool1)
self.uconv1 = torch.nn.ModuleList(self.uconv1)
#self.loss = NcutsLoss()
def add_conv_stage(self,dim_in, dim_out, kernel_size=3, stride=1, padding=1, bias=True, seperable=True):
if seperable:
return nn.Sequential(
nn.Conv2d(dim_in,dim_out,1,bias = bias),
nn.Conv2d(dim_out,dim_out,kernel_size,padding = padding,groups = dim_out,bias = bias),
nn.ReLU(),
nn.BatchNorm2d(dim_out),
nn.Conv2d(dim_out,dim_out,1,bias = bias),
nn.Conv2d(dim_out,dim_out,kernel_size,padding = padding,groups = dim_out,bias = bias),
nn.ReLU(),
nn.BatchNorm2d(dim_out),
)
else:
return nn.Sequential(
nn.Conv2d(dim_in,dim_out,kernel_size,padding = padding,bias = bias),
nn.ReLU(),
nn.BatchNorm2d(dim_out),
nn.Conv2d(dim_out,dim_out,kernel_size,padding = padding,bias = bias),
nn.ReLU(),
nn.BatchNorm2d(dim_out),
)
def forward(self,x):
self.feature1 = [x]
#U-Net1
self.feature1.append(self.module[0](x))
for i in range(1,config.MaxLv):
tempf = self.maxpool1[i-1](self.feature1[-1])
self.feature1.append(self.module[i](tempf))
for i in range(config.MaxLv,2*config.MaxLv-2):
tempf = self.uconv1[i-config.MaxLv](self.feature1[-1])
tempf = torch.cat((self.feature1[2*config.MaxLv-i-1],tempf),dim=1)
self.feature1.append(self.module[i](tempf))
tempf = self.uconv1[-1](self.feature1[-1])
tempf = torch.cat((self.feature1[1],tempf),dim=1)
tempf = self.module[-1](tempf)
tempf = self.predconv(tempf)
self.feature2 = [self.softmax(tempf)]
return [self.feature2[0],self.pad(self.feature2[0])]
#self.feature2.append(self.loss(self.feature2[0],self.feature2[1],w,sw))
#U-Net2
'''tempf = self.conv2[0](self.feature2[-1])
tempf = self.ReLU2[0](tempf)
tempf = self.bn2[0](tempf)
tempf = self.conv2[1](tempf)
tempf = self.ReLU2[1](tempf)
self.feature2.append(self.bn2[1](tempf))
for i in range(1,config.MaxLv):
tempf = self.maxpool2[i-1](self.feature2[-1])
tempf = self.conv2[4*i-2](tempf)
tempf = self.conv2[4*i-1](tempf)
tempf = self.ReLU2[2*i](tempf)
tempf = self.bn2[2*i](tempf)
tempf = self.conv2[4*i](tempf)
tempf = self.conv2[4*i+1](tempf)
tempf = self.ReLU2[2*i+1](tempf)
self.feature2.append(self.bn2[2*i+1](tempf))
for i in range(config.MaxLv,2*config.MaxLv-2):
tempf = self.uconv2[i-config.MaxLv](self.feature2[-1])
tempf = torch.cat((self.feature2[2*config.MaxLv-i-1],tempf),dim=1)
tempf = self.conv2[4*i-2](tempf)
tempf = self.conv2[4*i-1](tempf)
tempf = self.ReLU2[2*i](tempf)
tempf = self.bn2[2*i](tempf)
tempf = self.conv2[4*i](tempf)
tempf = self.conv2[4*i+1](tempf)
tempf = self.ReLU2[2*i+1](tempf)
tempf = self.bn2[2*i+1](tempf)
self.feature2.append(tempf)
tempf = self.uconv2[config.MaxLv-2](self.feature2[-1])
tempf = torch.cat((self.feature2[1],tempf),dim=1)
tempf = self.conv2[-2](tempf)
tempf = self.ReLU2[4*config.MaxLv-4](tempf)
tempf = self.bn2[4*config.MaxLv-4](tempf)
tempf = self.conv2[-1](tempf)
tempf = self.ReLU2[4*config.MaxLv-3](tempf)
tempf = self.bn2[4*config.MaxLv-3](tempf)
self.feature2.append(tempf)
tempf = self.reconsconv(self.feature2[-1])
tempf = self.ReLU2[-1](tempf)
self.feature2[-1] = self.bn2[-1](tempf)
'''
config = Config()
def add_conv_stage(dim_in, dim_out, kernel_size=3, stride=1, padding=1, bias=True, useBN=False):
if useBN:
return nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias),
nn.BatchNorm2d(dim_out),
nn.LeakyReLU(0.1),
nn.Conv2d(dim_out, dim_out, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias),
nn.BatchNorm2d(dim_out),
nn.LeakyReLU(0.1)
)
else:
return nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias),
nn.ReLU(),
nn.Conv2d(dim_out, dim_out, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias),
nn.ReLU()
)
def add_merge_stage(ch_coarse, ch_fine, in_coarse, in_fine, upsample):
conv = nn.ConvTranspose2d(ch_coarse, ch_fine, 4, 2, 1, bias=False)
torch.cat(conv, in_fine)
return nn.Sequential(
nn.ConvTranspose2d(ch_coarse, ch_fine, 4, 2, 1, bias=False)
)
upsample(in_coarse)
def upsample(ch_coarse, ch_fine):
return nn.Sequential(
nn.ConvTranspose2d(ch_coarse, ch_fine, 4, 2, 1, bias=False),
nn.ReLU()
)
class Net(nn.Module):
def __init__(self, useBN=False):
super(Net, self).__init__()
self.conv1 = add_conv_stage(config.InputCh, 32, useBN=useBN)
self.conv2 = add_conv_stage(32, 64, useBN=useBN)
self.conv3 = add_conv_stage(64, 128, useBN=useBN)
self.conv4 = add_conv_stage(128, 256, useBN=useBN)
self.conv5 = add_conv_stage(256, 512, useBN=useBN)
self.conv4m = add_conv_stage(512, 256, useBN=useBN)
self.conv3m = add_conv_stage(256, 128, useBN=useBN)
self.conv2m = add_conv_stage(128, 64, useBN=useBN)
self.conv1m = add_conv_stage( 64, 32, useBN=useBN)
self.conv0 = nn.Sequential(
nn.Conv2d(32, config.K, 3, 1, 1),
nn.Sigmoid(),
nn.Softmax2d()
)
self.pad = nn.ConstantPad2d(config.radius-1,0)
self.max_pool = nn.MaxPool2d(2)
self.upsample54 = upsample(512, 256)
self.upsample43 = upsample(256, 128)
self.upsample32 = upsample(128, 64)
self.upsample21 = upsample(64 , 32)
## weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
if m.bias is not None:
m.bias.data.zero_()
#self.Kconst = torch.tensor(config.K).float()
#self.cropped_seg = torch.zeros(config.BatchSize,config.K,config.inputsize[0],config.inputsize[1],(config.radius-1)*2+1,(config.radius-1)*2+1)
#self.loss = NCutsLoss()
def forward(self, x):#, weight):
#sw = weight.sum(-1).sum(-1)
conv1_out = self.conv1(x)
#return self.upsample21(conv1_out)
conv2_out = self.conv2(self.max_pool(conv1_out))
conv3_out = self.conv3(self.max_pool(conv2_out))
conv4_out = self.conv4(self.max_pool(conv3_out))
conv5_out = self.conv5(self.max_pool(conv4_out))
conv5m_out = torch.cat((self.upsample54(conv5_out), conv4_out), 1)
conv4m_out = self.conv4m(conv5m_out)
conv4m_out_ = torch.cat((self.upsample43(conv4m_out), conv3_out), 1)
conv3m_out = self.conv3m(conv4m_out_)
conv3m_out_ = torch.cat((self.upsample32(conv3m_out), conv2_out), 1)
conv2m_out = self.conv2m(conv3m_out_)
conv2m_out_ = torch.cat((self.upsample21(conv2m_out), conv1_out), 1)
conv1m_out = self.conv1m(conv2m_out_)
conv0_out = self.conv0(conv1m_out)
padded_seg = self.pad(conv0_out)
'''for m in torch.arange((config.radius-1)*2+1,dtype=torch.long):
for n in torch.arange((config.radius-1)*2+1,dtype=torch.long):
self.cropped_seg[:,:,:,:,m,n]=padded_seg[:,:,m:m+conv0_out.size()[2],n:n+conv0_out.size()[3]].clone()
multi1 = self.cropped_seg.mul(weight)
multi2 = multi1.view(multi1.shape[0],multi1.shape[1],multi1.shape[2],multi1.shape[3],-1).sum(-1).mul(conv0_out)
multi3 = sum_weight.mul(conv0_out)
assocA = multi2.view(multi2.shape[0],multi2.shape[1],-1).sum(-1)
assocV = multi3.view(multi3.shape[0],multi3.shape[1],-1).sum(-1)
assoc = assocA.div(assocV).sum(-1)
loss = self.Kconst - assoc'''
#loss = self.loss(conv0_out, padded_seg, weight, sw)
return [conv0_out,padded_seg]
oduleNotFoundError: No module named 'configure'
help me