Recently, I am deploying my model to Android. I found that my quantized model has very high cpu usage, even much higher than fp32 float model. So I tried to run a model with only one Linear layer like:
#Calibration
for i in range(1,100):
x = model(torch.randn(15, idim))
torch.quantization.convert(model, inplace=True)
script_module = torch.jit.script(model)
script_module.save(‘model.pt’)
Then I load the exported script model and do inference using C++. In order to control the inference frequency, I do inference every 160ms to imitate the streaming speech recognition task.
Even this simple model, the quantized model’s cpu usage is about 30% while the fp32 model is 1%.
My pytorch is 1.6.0 and ndk is r19c. I test my model using arm32 and aarch64 both.
My libtorch builds cmd:
./script/build_android.sh
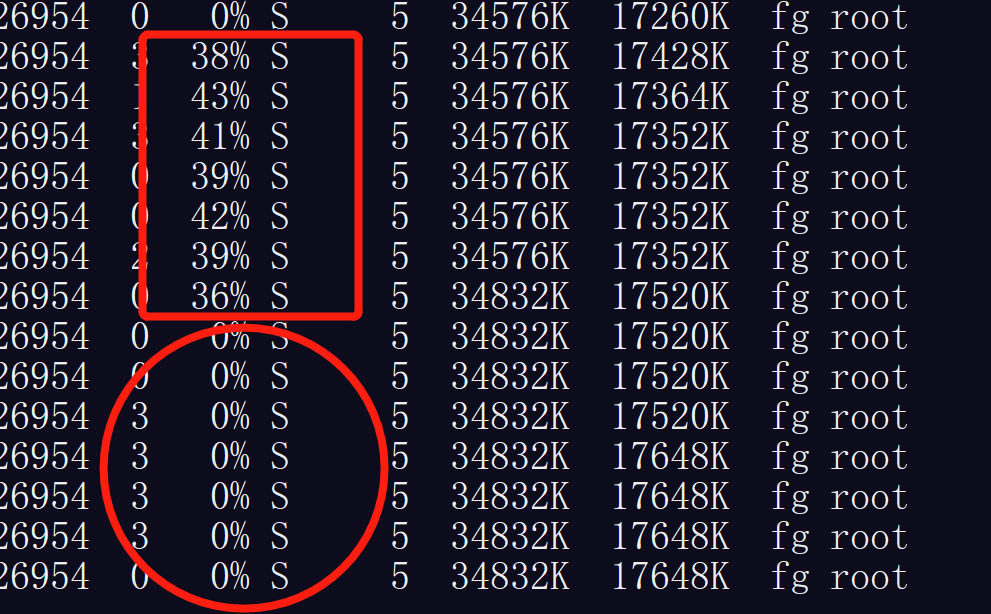
This picture is the cpu usage of quantized (rectangle) and fp32 (circle) models on on arm32:
Well, you could limit the number of threads to make it a better comparison. The overall work done should somewhat decrease.
What might happen here is that the backends are set up differently and this is what you see.