Hi, I’m confusing in the padding masking of transformer.
The following picture shows the self-attention weight of the query(row) and key(coloumn).
As you can see, there are some tokens "<PAD>" and I have already mask it in key using nn.MultiheadAttention. Therefore the tokens will not calculate the attention weight.
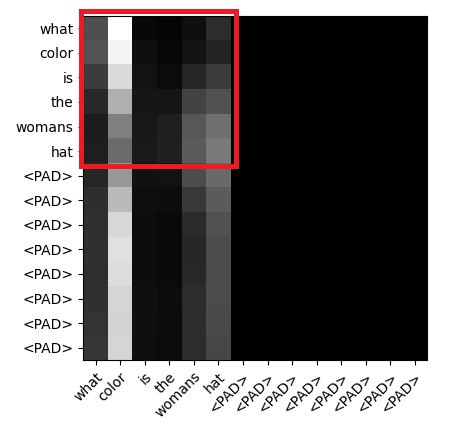
There are two questions:
- In query part, can I also mask them except for the red square part? Is this reasonable?
- How can I mask "<PAD>" in the query?
The attention weights use thesoftmaxfunction along the row. If I set all the "<PAD>" row into-inf, thesoftmaxwill returnnanand the loss with benan