Hello.
I have a question about GPU allocate and cache.
I have seen GPU allocation and cache using code like below (Below is nothing loaded on the GPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
print()
if device.type == 'cuda':
print(torch.cuda.get_device_name(0))
print('Memory Usage:')
print('Allocated:', round(torch.cuda.memory_allocated(0)/1024**3,1), 'GB')
print('Cached: ', round(torch.cuda.memory_cached(0)/1024**3,1), 'GB')
Using device: cuda
TITAN RTX
Memory Usage:
Allocated: 0.0 GB
Cached: 0.0 GB
However, when I loaded the model and inputs(targets) into the GPU and checked the code above for each step, I found something strange.
model = model.to(device)
for batch_idx , (data,target) in enumerate(data_loader):
inputs,target = data.to(device),target.to(device)
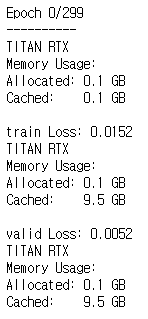
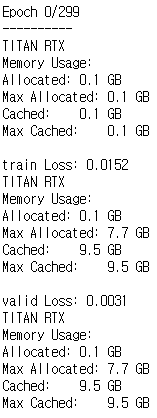
As shown in the picture, during training and validation, only GPU memory was allocated 0.1GB and most of them went into the cache.
Because of this, CPU usage seems to increase abnormally.
I loaded both the model and inputs(targets) into the GPU. Why is the GPU allocation only 0.1GB?
How do I increase GPU allocation?