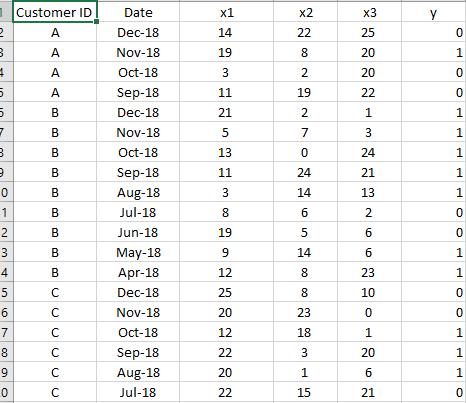
I work in consumer credit where we deal with a lot of panel data, e.g., a customer’s payment history. Consequently, I will have customers with multiple and varying number of observations. I’m looking at exploring an LSTM architecture but having difficulty figuring out how the time series element of the data should be reshaped and padded to account for the varying lengths of the sequence for different customers. This would be a one step classification problem where we try to predict whether a customer defaults or not in the month following the end of the sequence.
For a given customer, if for example that customer had 25 observations because he took out an account 25 months ago we would have 24 sequences for that customer the shortest with 1 observation and the longest with 24 observations.
A dataset might look like this for your reference: