EDIT: Resolved see comment
Hi everyone,
I’m trying to solve a relaxation of the below optimization problem over hyperplanes w.
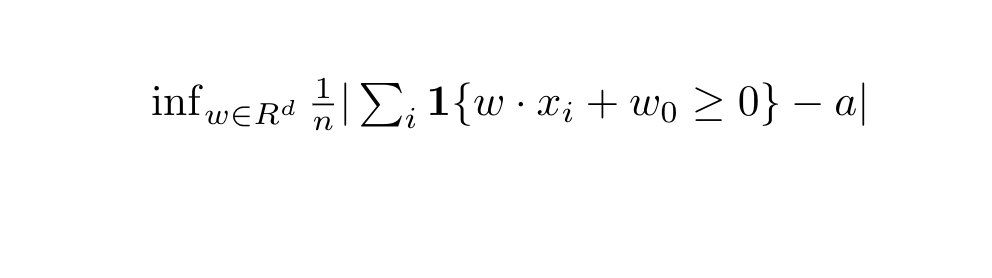
I’m solving it by relaxing the problem by approximating the indicator loss with logistic loss as in a logistic regression. Note that the generate_data(n, d) function just generates a random data frame of size n x d.
However, when I run the below routine, it does not decrease the objective; if anything it increases it. I’m not sure exactly where the error lies – either in the optimization step or in the relaxation.
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
from synth_data_class import *
class Net(nn.Module):
def __init__(self, input_size):
super(Net, self).__init__()
self.linear = nn.Linear(input_size, 1, bias=True)
# nn.Linear automatically does softmax
def forward(self, x):
out = self.linear(x)
# compute softmax
soft_out = torch.stack([torch.exp(out)/(1 + torch.exp(out)), 1/(1 + torch.exp(out))])
soft_out = soft_out.transpose(0,1).view(-1,2)
return soft_out
class Dataset(Dataset):
def __init__(self, X, y):
self.data = X
self.labels = y
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
x = self.data.__getitem__(idx)
y = self.labels[idx]
return {'X': x, 'y': y}
# get data
n = 100
d = 6
data = torch.tensor(np.array(gen_synthetic_data(d, n, 'binary', intercept=False)[0])).type(torch.FloatTensor)
labels = torch.tensor([1]*n).type(torch.FloatTensor)
dataset = Dataset(data, labels)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
net = Net(d)
a = torch.tensor(.3)
learning_rate = 0.001
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate)
criterion = nn.NLLLoss()
n_passes = 1000
for epoch in range(n_passes):
for batch in dataloader:
#print(list(net.parameters()))
outputs = net(data)
_, predicted = torch.max(outputs.data, 1)
if torch.tensor(1.0/n)*torch.sum(predicted) > a:
sign = 1
else:
sign = -1
print(torch.abs(torch.tensor(1.0/n)*torch.sum(predicted)-a))
X, y = batch['X'], batch['y']
optimizer.zero_grad()
y_hat = net(X)
# compute log likelihood loss
loss = torch.tensor(sign)*criterion(torch.log(y_hat), y.type(torch.LongTensor))
loss.backward()
optimizer.step()