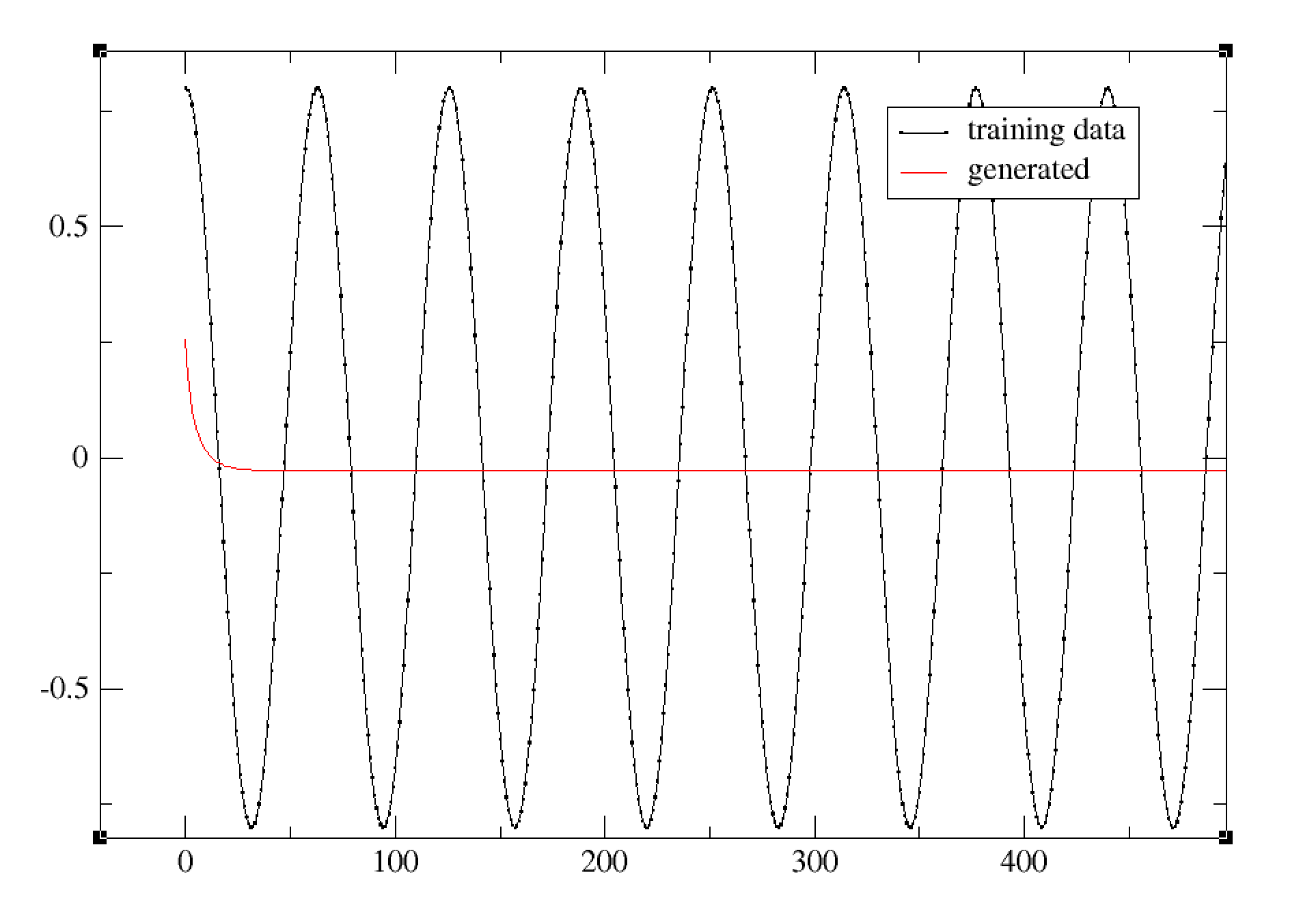
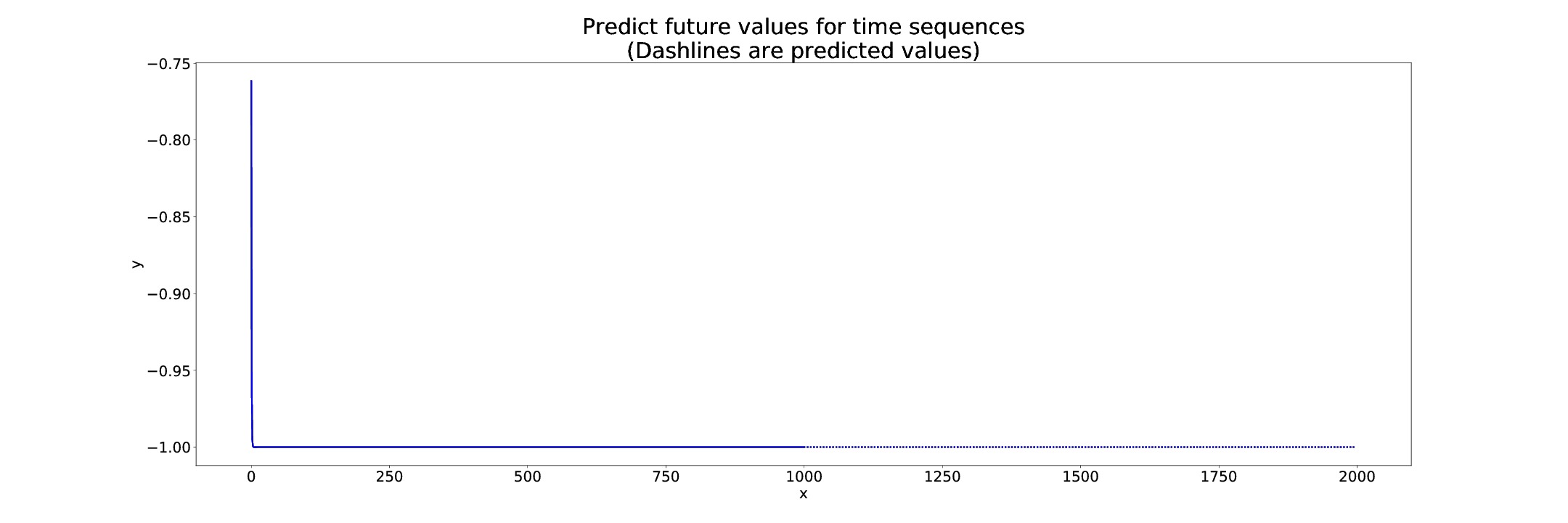
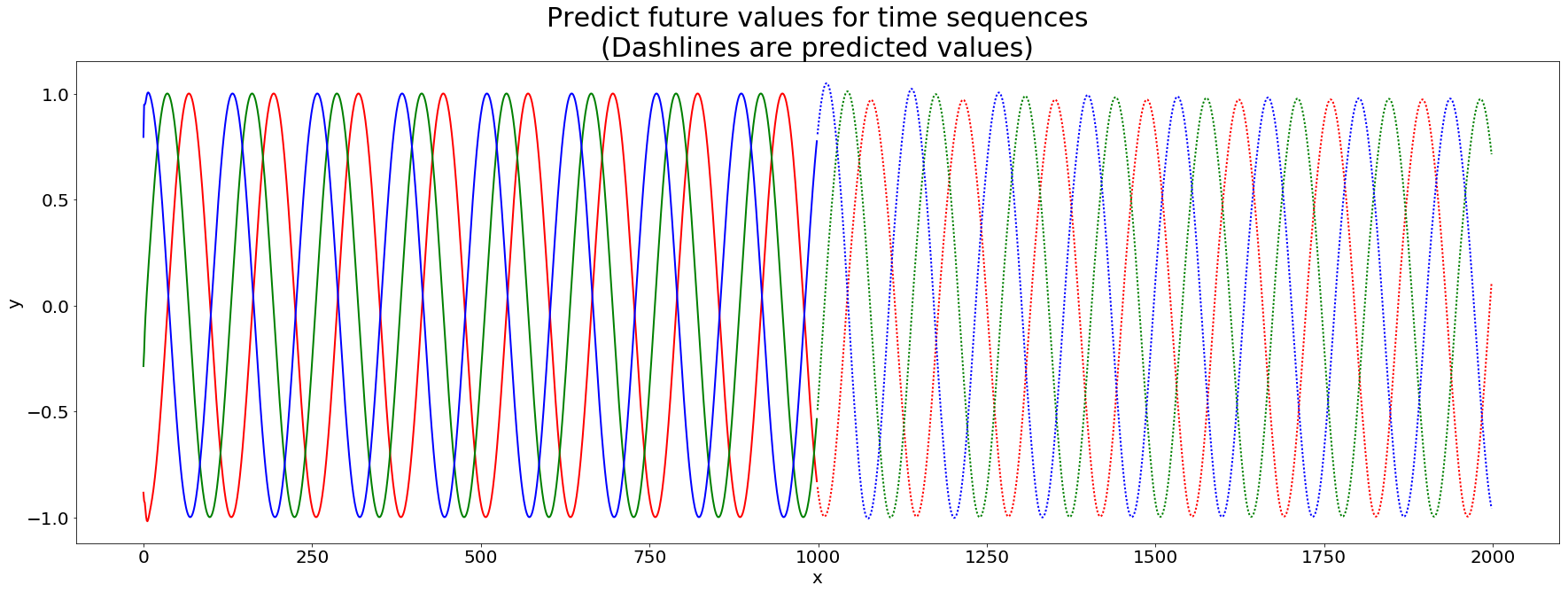
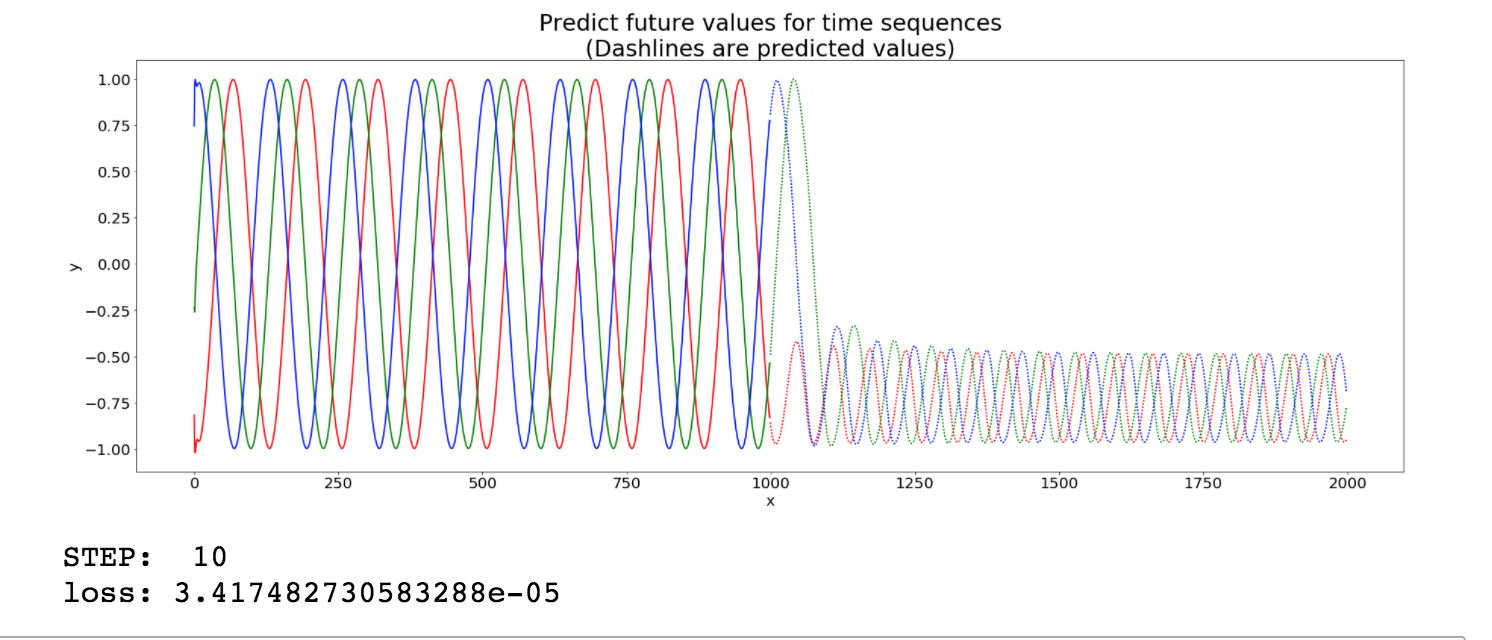
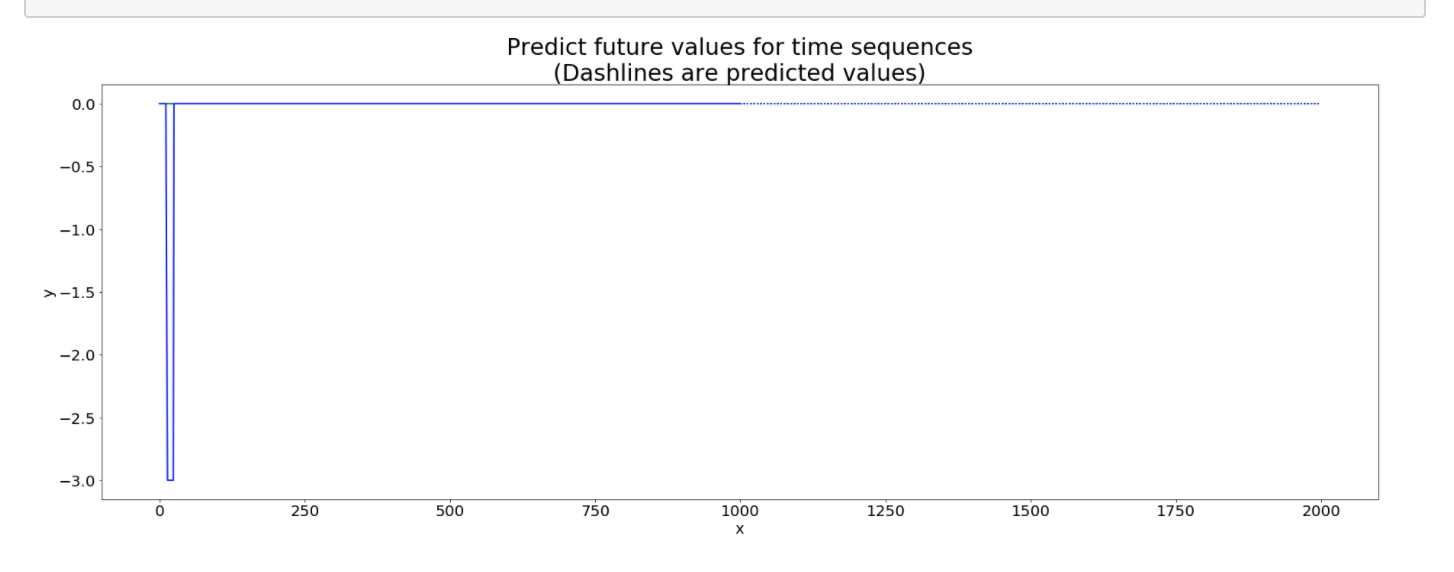
I’m trying to modify the world_language_model example to generate a time series. My naive approach was to replace the softmax output with a single linear output layer, and change the loss function to MSELoss. Unfortunately, my network seems to learn to output the current input, instead of predicting the next sample. So when I try to generate a new time series, the network is soon stuck at a fixed point. Any suggestions on how to improve my model? Here’s my code:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
Train a LSTM network to generate a time series.
'''
import argparse
import collections
import csv
import math
import pickle
import time
import torch
import torch.nn as nn
from torch.autograd import Variable
def read_arguments():
parser = argparse.ArgumentParser(description='Train a recurrent network to generate a time series.')
parser.add_argument('--data', type=str, default='data.txt',
help='data file to read (CSV)')
parser.add_argument('--model', type=str, default='LSTM',
help='type of recurrent net (RNN_TANH, RNN_RELU, LSTM, GRU)')
parser.add_argument('--nhid', type=int, default=100,
help='humber of hidden units per layer')
parser.add_argument('--nlayers', type=int, default=2,
help='number of layers')
parser.add_argument('--lr', type=float, default=.05,
help='initial learning rate')
parser.add_argument('--clip', type=float, default=5,
help='gradient clipping')
parser.add_argument('--epochs', type=int, default=10,
help='upper epoch limit')
parser.add_argument('--batch-size', type=int, default=10, metavar='N',
help='batch size')
parser.add_argument('--bptt', type=int, default=375,
help='sequence length')
parser.add_argument('--checkpoint-interval', type=int, default=10, metavar='N',
help='interval to save intermediate models')
parser.add_argument('--save', type=str, default='model',
help='path to save the final model')
args = parser.parse_args()
return args
class RNNModel(nn.Module):
"""Container module with an encoder, a recurrent module, and a decoder."""
def __init__(self, rnn_type, nhid, nlayers):
super(RNNModel, self).__init__()
self.rnn = getattr(nn, rnn_type)(1, nhid, nlayers)
self.output = nn.Linear(nhid, 1)
self.init_weights()
self.rnn_type = rnn_type
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):
initrange = 0.1
self.output.bias.data.fill_(1.0)
self.output.weight.data.uniform_(-initrange, initrange)
def forward(self, input, hidden):
output_lstm, hidden = self.rnn(input, hidden)
output = self.output(output_lstm.view(output_lstm.size(0)*output_lstm.size(1), output_lstm.size(2)))
return output.view(output_lstm.size(0), output_lstm.size(1), output.size(1)), hidden
def init_hidden(self, bsz):
weight = next(self.parameters()).data
if self.rnn_type == 'LSTM':
return (Variable(weight.new(self.nlayers, bsz, self.nhid).zero_()),
Variable(weight.new(self.nlayers, bsz, self.nhid).zero_()))
else:
return Variable(weight.new(self.nlayers, bsz, self.nhid).zero_())
def flatten(l):
for el in l:
if isinstance(el, collections.Iterable) and not isinstance(el, str):
for sub in flatten(el):
yield sub
else:
yield el
def batchify(data, bsz):
nbatch = data.size(0) // bsz
data = data.narrow(0, 0, nbatch * bsz)
data = data.view(bsz, -1).t().contiguous()
if torch.cuda.is_available():
data = data.cuda()
return data
def load_data(filename, batch_size):
'''
Load a training data sequence from a CSV file
'''
with open(filename) as csvfile:
csvreader = csv.reader(csvfile)
data = list(csvreader)
data = torch.Tensor([float(x) for x in flatten(data)])
train_length = math.ceil(len(data) * .7)
val_length = math.ceil(len(data) * .2)
train_data = data[:train_length]
val_data = data[train_length:train_length+val_length]
test_data = data[train_length+val_length:]
return batchify(train_data, batch_size), batchify(val_data, batch_size), batchify(test_data, batch_size)
###############################################################################
# Training code
###############################################################################
def clip_gradient(model, clip):
"""Computes a gradient clipping coefficient based on gradient norm."""
totalnorm = 0
for p in model.parameters():
modulenorm = p.grad.data.norm()
totalnorm += modulenorm ** 2
totalnorm = math.sqrt(totalnorm)
return min(1, clip / (totalnorm + 1e-6))
def repackage_hidden(h):
"""Wraps hidden states in new Variables, to detach them from their history."""
if type(h) == Variable:
return Variable(h.data)
else:
return tuple(repackage_hidden(v) for v in h)
def get_batch(source, i, seq_length, evaluation=False):
seq_len = min(seq_length, len(source) - 1 - i)
data = Variable(source[i:i+seq_len].view(seq_len, -1, 1), volatile=evaluation)
target = Variable(source[i+1:i+1+seq_len].view(-1))
return data, target
def evaluate(data_source, model, criterion, batch_size, seq_length):
total_loss = 0
hidden = model.init_hidden(batch_size)
for i in range(0, data_source.size(0) - 1, seq_length):
data, targets = get_batch(data_source, i, seq_length, evaluation=True)
output, hidden = model(data, hidden)
total_loss += len(data) * criterion(output, targets).data
hidden = repackage_hidden(hidden)
return total_loss[0] / len(data_source)
def train(train_data, model, criterion, lr, batch_size, seq_length, grad_clip):
total_loss = 0
hidden = model.init_hidden(batch_size)
for batch, i in enumerate(range(0, train_data.size(0) - 1, seq_length)):
data, targets = get_batch(train_data, i, seq_length)
hidden = repackage_hidden(hidden)
model.zero_grad()
output, hidden = model(data, hidden)
loss = criterion(output, targets)
loss.backward()
clipped_lr = lr * clip_gradient(model, grad_clip)
for p in model.parameters():
p.data.add_(-clipped_lr, p.grad.data)
print('.', end='', flush=True)
total_loss += loss.data
return total_loss[0] / batch
def save_model(model, name, checkpoint = ''):
filename = name + str(checkpoint) + '.pt'
print('Saving model to', filename)
with open(filename, 'wb') as f:
torch.save(model, f)
def main():
args = read_arguments()
print("Loading data...")
ecg_data, val_data, test_data = load_data(args.data, args.batch_size)
print("Building network ...")
###############################################################################
# Build the model
###############################################################################
model = RNNModel(args.model, args.nhid, args.nlayers)
if torch.cuda.is_available():
print('Using CUDA')
model.cuda()
criterion = nn.MSELoss()
print("Training network ...")
try:
lr = args.lr
ci = args.checkpoint_interval
filename = args.save
print('Learning rate {:.5f}'.format(lr))
prev_loss = None
for epoch in range(1, args.epochs+1):
epoch_start_time = time.time()
train_loss = train(ecg_data, model, criterion, lr, args.batch_size, args.bptt, args.clip)
val_loss = evaluate(val_data, model, criterion, args.batch_size, args.bptt)
print()
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | '
'train loss {:5.2f} | val loss{:5.2f}'.format(epoch, (time.time() - epoch_start_time),
train_loss, val_loss))
print('-' * 89)
if not (epoch % ci):
save_model(model, filename, epoch)
if prev_loss and val_loss > prev_loss:
lr /= 4
print('New learning rate {:.5f}'.format(lr))
prev_loss = val_loss
except KeyboardInterrupt:
pass
finally:
print()
test_loss = evaluate(test_data, model, criterion, args.batch_size, args.bptt)
print('=' * 89)
print('| End of training | test loss {:5.2f} |'.format(
test_loss))
print('=' * 89)
save_model(model, filename)
if __name__ == '__main__':
main()