Actually, I do have two additional questions related to the example code, if @tom or others don’t mind:
-
In the example code, the input and target are assigned from index 3 onward of data, as in “torch.from_numpy(data[3:, :-1])”. What is the purpose of excluding data at indexes 0,1,2 from the input and target?
-
I’m finding that if I make one of the time series a bit more ‘interesting’, e.g. adding the following ‘amplitude clipping’ immediately after data is defined…
data[4] = [ np.min( [np.max([_, -0.5]), 0.5] ) for _ in data[3]]…then despite the training loss getting very small (~3e-5) the code never seems to be able to predict the series accurately (picture below).
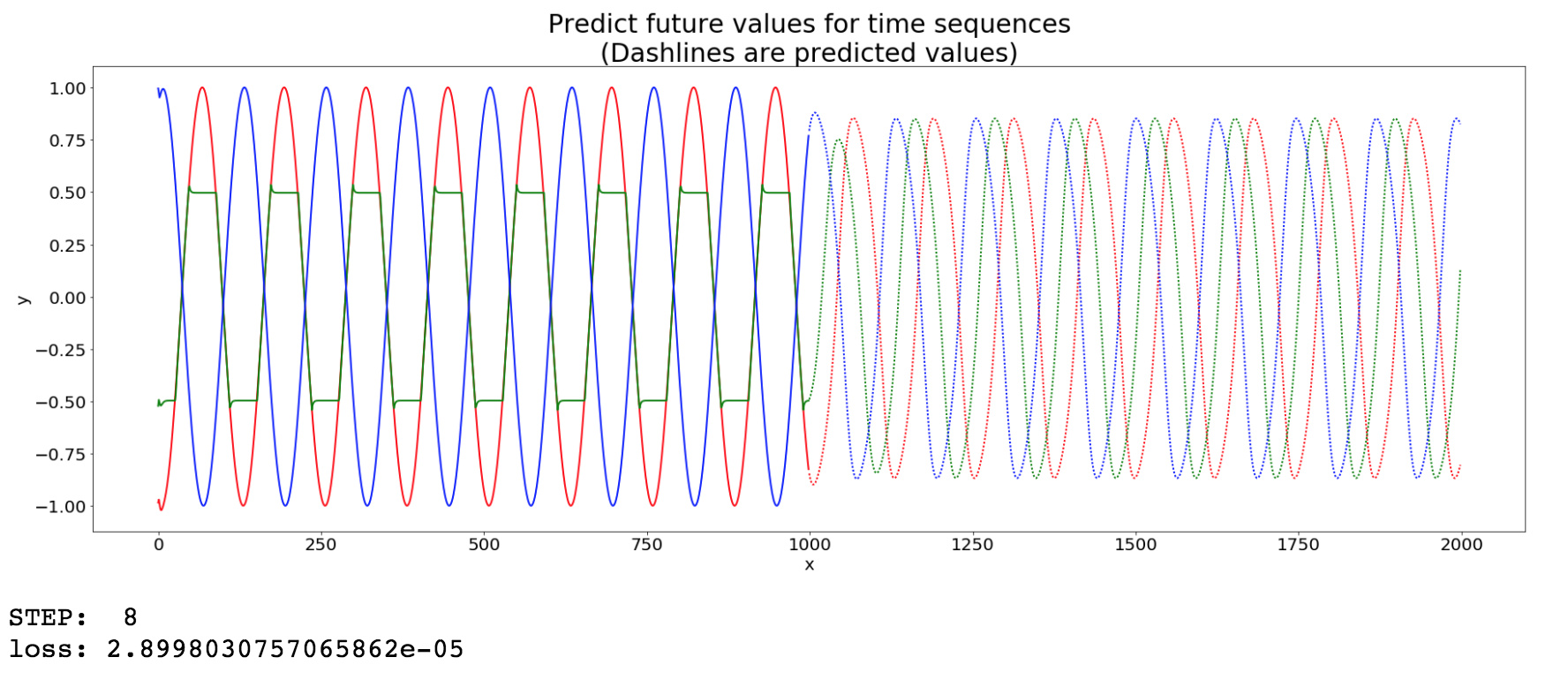
Is this…expected behavior? I would have thought the LSTM could predict better (since it seems to fit the training data well).
P.S.- Even if I clip all the series instead of just one, the same thing results: excellent fitting of training data and low loss, but extremely poor prediction. Doubling the network size (from 51 to 102) doesn’t help either. Alternatively to clipping, one can try a superposition of sinusoids, e.g. data = 0.5*np.sin(x / 1.0 / T).astype('float32') + 0.4*np.cos(x / 2 / T).astype('float32'), and still the code shows the same behavior of low training loss but terrible prediction.