I have a RNN model that throws this strange exception. I am using PyTorch 0.4 since this is an old code and I am still trying to upgrade it (still would really like to have it running for comparison).
I have CUDA 10.1 installed and it seems only the LSTM based model is causing issues. Any help would be highly appreciated.
self.lang_model.cuda()
File "/home/chinmay/Desktop/setup/3dsis/lib/python3.6/site-packages/torch/nn/modules/module.py", line 258, in cuda
return self._apply(lambda t: t.cuda(device))
File "/home/chinmay/Desktop/setup/3dsis/lib/python3.6/site-packages/torch/nn/modules/module.py", line 185, in _apply
module._apply(fn)
File "/home/chinmay/Desktop/setup/3dsis/lib/python3.6/site-packages/torch/nn/modules/rnn.py", line 112, in _apply
self.flatten_parameters()
File "/home/chinmay/Desktop/setup/3dsis/lib/python3.6/site-packages/torch/nn/modules/rnn.py", line 105, in flatten_parameters
self.batch_first, bool(self.bidirectional))
RuntimeError: CuDNN error: CUDNN_STATUS_SUCCESS
Hi @ptrblck the issue does not happen with the latest version of PyTorch it is just that I have an older code and I am still working on porting it. However, interestingly, I found an old issue which suggests that we should try and put the model on CUDA twice and I was able to get it to work (5 minutes before your message ).
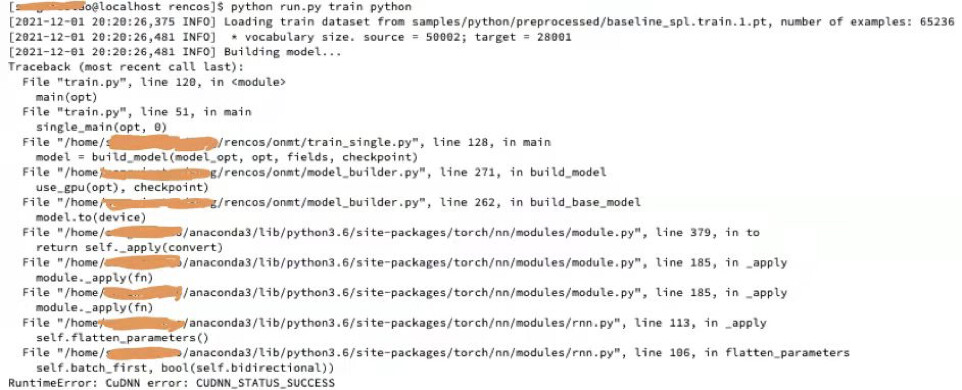
Hi, my problem is similar to the above post. Specifically, my GPU server environment is centOS Linux 7.8.2003(core),and pytorch0.4.1, two cuda version 9.0 and 10.1(and 10.1 is the version I use). And I’m reproducing others program( that is cloned from GitHub) now, When I run the program, the system throw some exception as the following,
You mean I need set torch.backends.cudnn.enabled = False, which file that I need to add this line in? or I need modify some global config file, such as my .bashrc file, etc ? Could you give me some suggestion! Thank you very much, I’ll try it now!
Thanks for your help! The program that I reproduce is from GitHub(GitHub - zhangj111/rencos). The main.py is run.py at(GitHub - zhangj111/rencos). Its content as follows:
import os
import sys
import time
Hi, My problem that I posted before have been solved, thank you for your help! And now I met another problem when I translate and generate output, it is “Runtime error; CUDA error: out of memory”. I think that it may be caused by the small amount of the monitor memory of our GPU server, so I want to reset my batch-size so that it can be suitable to the monitor memory of our GPU server, but I don’t know which file I need to choose to.
 ).
).