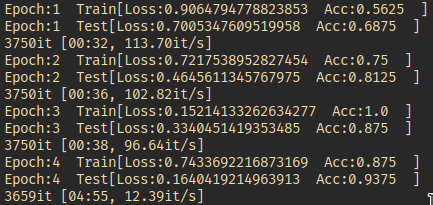
I am trying to make an vanilla RNN implementation in Pytorch work (code below), however test loss and accuracy is perpetually stuck at the same values as shown in the print statements:
X shape before squeeze: torch.Size([4, 1, 28, 28])
X shape after squeeze: torch.Size([4, 28, 28])
Model out shape: torch.Size([4, 10])
Model out: tensor([[ 0.0942, 0.0554, -0.0131, -0.0168, 0.0099, 0.0048, -0.1002, 0.0427,
0.0390, -0.0805],
[ 0.0948, 0.0549, -0.0114, -0.0175, 0.0102, 0.0039, -0.1002, 0.0431,
0.0396, -0.0813],
[ 0.1007, 0.0566, -0.0089, -0.0158, 0.0119, 0.0025, -0.1016, 0.0404,
0.0368, -0.0865],
[ 0.0945, 0.0552, -0.0125, -0.0174, 0.0092, 0.0035, -0.0995, 0.0428,
0.0394, -0.0811]], grad_fn=<AddmmBackward0>)
Model pred shape: torch.Size([4])
Model pred: tensor([0, 0, 0, 0])
Target shape: torch.Size([4])
Target: tensor([0, 6, 9, 0])
Epoch:1 Train[Loss:20.794414520263672 Acc:0.0 ]
Epoch:1 Test[Loss:24.953298568725586 Acc:0.0 ]
X shape before squeeze: torch.Size([4, 1, 28, 28])
X shape after squeeze: torch.Size([4, 28, 28])
Model out shape: torch.Size([4, 10])
Model out: tensor([[ 0.0945, 0.0553, -0.0122, -0.0176, 0.0093, 0.0031, -0.1001, 0.0435,
0.0399, -0.0809],
[ 0.0955, 0.0551, -0.0115, -0.0172, 0.0099, 0.0036, -0.0994, 0.0430,
0.0396, -0.0812],
[ 0.0951, 0.0549, -0.0113, -0.0175, 0.0099, 0.0031, -0.1001, 0.0431,
0.0398, -0.0815],
[ 0.0945, 0.0552, -0.0117, -0.0143, 0.0090, 0.0035, -0.0992, 0.0427,
0.0397, -0.0807]], grad_fn=<AddmmBackward0>)
Model pred shape: torch.Size([4])
Model pred: tensor([0, 0, 0, 0])
Target shape: torch.Size([4])
Target: tensor([0, 3, 0, 8])
Epoch:2 Train[Loss:38.81624221801758 Acc:0.0 ]
Epoch:2 Test[Loss:24.953298568725586 Acc:0.0 ]
X shape before squeeze: torch.Size([4, 1, 28, 28])
X shape after squeeze: torch.Size([4, 28, 28])
Model out shape: torch.Size([4, 10])
Model out: tensor([[ 0.0998, 0.0537, -0.0075, -0.0196, 0.0124, 0.0029, -0.0984, 0.0438,
0.0405, -0.0843],
[ 0.0947, 0.0554, -0.0115, -0.0174, 0.0109, 0.0042, -0.1005, 0.0433,
0.0394, -0.0816],
[ 0.0950, 0.0550, -0.0113, -0.0178, 0.0102, 0.0038, -0.1000, 0.0430,
0.0395, -0.0816],
[ 0.0928, 0.0567, -0.0105, -0.0158, 0.0055, 0.0036, -0.0978, 0.0448,
0.0364, -0.0807]], grad_fn=<AddmmBackward0>)
Model pred shape: torch.Size([4])
Model pred: tensor([0, 0, 0, 0])
Target shape: torch.Size([4])
Target: tensor([9, 4, 6, 9])
Epoch:3 Train[Loss:29.1121826171875 Acc:0.0 ]
Epoch:3 Test[Loss:24.953298568725586 Acc:0.0 ]
X shape before squeeze: torch.Size([4, 1, 28, 28])
X shape after squeeze: torch.Size([4, 28, 28])
Model out shape: torch.Size([4, 10])
Model out: tensor([[ 0.0951, 0.0550, -0.0115, -0.0177, 0.0101, 0.0037, -0.1004, 0.0430,
0.0394, -0.0816],
[ 0.0955, 0.0547, -0.0111, -0.0178, 0.0104, 0.0032, -0.1003, 0.0429,
0.0394, -0.0817],
[ 0.0962, 0.0546, -0.0093, -0.0168, 0.0119, 0.0033, -0.1013, 0.0420,
0.0397, -0.0835],
[ 0.0918, 0.0559, -0.0107, -0.0159, 0.0101, 0.0053, -0.1008, 0.0446,
0.0404, -0.0811]], grad_fn=<AddmmBackward0>)
Model pred shape: torch.Size([4])
Model pred: tensor([0, 0, 0, 0])
Target shape: torch.Size([4])
Target: tensor([6, 3, 0, 9])
I have tried different ways to address the issue: 1) tried various ways to adjust the input 2) adjusted hyperparams (i.e. num_layers, learning rate etc.), 3) increase sequence lentgh and input size, without much success. The network seems to predict each element in the batch to be the same digit i.e., 7 and then remains stuck forever at predicting 7.
While i know it is very tempting to say “vanishisng gradients”, we observe the same phenomenon when using a GRU and LSTM cell. We also tried gradient clipping which did not improve help either.
Just now I have also tried using the pytorch implementation nn.Rnn, and the test loss is frozen as well at similar values. I strongly suspect the problem lies within the training and test function. We are passing the data into the model incorrectly.
import torch
from torch import nn
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
import numpy as np
from torch.autograd import Variable
import torchvision
import torchvision.transforms as T
import torch.optim as optim
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
class RNNCell(nn.Module):
def __init__(self, input_size, hidden_size, bias=True, nonlinearity="tanh"):
super(RNNCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.bias = bias
self.nonlinearity = nonlinearity
if self.nonlinearity not in ["tanh", "relu"]:
raise ValueError("Invalid nonlinearity selected for RNN.")
self.x2h = nn.Linear(input_size, hidden_size, bias=bias)
self.h2h = nn.Linear(hidden_size, hidden_size, bias=bias)
self.reset_parameters()
def reset_parameters(self):
std = 1.0 / np.sqrt(self.hidden_size)
for w in self.parameters():
w.data.uniform_(-std, std)
def forward(self, input, hx=None):
# Inputs:
# input: of shape (batch_size, input_size)
# hx: of shape (batch_size, hidden_size)
# Output:
# hy: of shape (batch_size, hidden_size)
if hx is None:
hx = Variable(input.new_zeros(input.size(0), self.hidden_size))
hy = (self.x2h(input) + self.h2h(hx))
if self.nonlinearity == "tanh":
hy = torch.tanh(hy)
else:
hy = torch.relu(hy)
return hy
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, bias, output_size, activation='tanh'):
super(SimpleRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.bias = bias
self.output_size = output_size
self.rnn_cell_list = nn.ModuleList()
if activation == 'tanh':
self.rnn_cell_list.append(RNNCell(self.input_size,
self.hidden_size,
self.bias,
"tanh"))
for l in range(1, self.num_layers):
self.rnn_cell_list.append(RNNCell(self.hidden_size,
self.hidden_size,
self.bias,
"tanh"))
elif activation == 'relu':
self.rnn_cell_list.append(RNNCell(self.input_size,
self.hidden_size,
self.bias,
"relu"))
for l in range(1, self.num_layers):
self.rnn_cell_list.append(RNNCell(self.hidden_size,
self.hidden_size,
self.bias,
"relu"))
else:
raise ValueError("Invalid activation.")
self.fc = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hx=None):
# Input of shape (batch_size, seqence length, input_size)
#
# Output of shape (batch_size, output_size)
if hx is None:
if torch.cuda.is_available():
h0 = Variable(torch.zeros(self.num_layers, input.size(0), self.hidden_size).cuda())
else:
h0 = Variable(torch.zeros(self.num_layers, input.size(0), self.hidden_size))
else:
h0 = hx
outs = []
hidden = list()
for layer in range(self.num_layers):
hidden.append(h0[layer, :, :])
for t in range(input.size(1)):
for layer in range(self.num_layers):
if layer == 0:
hidden_l = self.rnn_cell_list[layer](input[:, t, :], hidden[layer])
else:
hidden_l = self.rnn_cell_list[layer](hidden[layer - 1],hidden[layer])
hidden[layer] = hidden_l
hidden[layer] = hidden_l
outs.append(hidden_l)
# Take only last time step. Modify for seq to seq
out = outs[-1].squeeze()
out = self.fc(out)
return out
weight_decay = 0.0005
sequence_length = 28
input_size = 28
hidden_size = 128
nlayers = 2
nclasses = 10
batch_size = 4
nepochs = 50
lr = 0.0003
data_dir = 'data/'
def train (train_loader, model, optimizer, loss_f):
"""
Input: train loader (torch loader), model (torch model), optimizer (torch optimizer)
loss function (torch custom yolov1 loss).
Output: loss (torch float).
"""
model.train()
for batch_idx, (x, y) in enumerate(train_loader):
x, y = x.to(device), y.to(device)
if batch_idx == 0:
print("X shape before squeeze: ", x.shape)
x = x.squeeze(1)
if batch_idx == 0:
print("X shape after squeeze: ", x.shape)
out = model(x)
if batch_idx == 0:
print("Model out shape: ", out.shape)
print("Model out:", out)
del x
pred_class = torch.max(out, dim = 1)[1]
if batch_idx == 0:
print("Model pred shape: ", pred_class.shape)
print("Model pred: ", pred_class)
print("Target shape: ", y.shape)
print("Target: ", y)
train_acc = sum(pred_class == y) / y.shape[0]
loss_val = loss_f(pred_class.float(), y.float())
loss_val.requires_grad = True
del y
del out
del pred_class
optimizer.zero_grad()
nn.utils.clip_grad_value_(model.parameters(), clip_value=1.0)
loss_val.backward()
optimizer.step()
return (float(loss_val.item()), train_acc)
def test (test_loader, model, loss_f):
"""
Input: test loader (torch loader), model (torch model), loss function
(torch custom yolov1 loss).
Output: test loss (torch float).
"""
model.eval()
with torch.no_grad():
for batch_idx, (x, y) in enumerate(test_loader):
x, y = x.to(device), y.to(device)
x = x.squeeze(1)
out = model(x)
del x
pred_class = torch.max(out, dim = 1)[1]
test_acc = sum(pred_class == y) / y.shape[0]
test_loss_val = loss_f(pred_class.float(), y.float())
del y
del out
del pred_class
return(float(test_loss_val.item()), test_acc)
def main():
model = SimpleRNN(input_size=28, hidden_size=128, num_layers=2, bias=True, output_size=10, activation = 'relu').to(device)
optimizer = optim.Adam(model.parameters(), lr = lr)
loss_f = nn.CrossEntropyLoss()
train_loss_lst = []
test_loss_lst = []
train_acc_lst = []
test_acc_lst = []
last_epoch = 0
train_dataset = torchvision.datasets.MNIST(root = data_dir ,
train=True,
transform=T.Compose([T.ToTensor()]),
download=True)
test_dataset = torchvision.datasets.MNIST(root = data_dir,
train = False,
transform=T.Compose([T.ToTensor()]))
train_loader = DataLoader(dataset=train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = DataLoader(dataset=test_dataset,
batch_size = batch_size,
shuffle = False)
for epoch in range(nepochs - last_epoch):
train_loss_value, train_acc_value = train(train_loader, model, optimizer, loss_f)
train_loss_lst.append(train_loss_value)
train_acc_lst.append(train_acc_value)
test_loss_value, test_acc_value = test(test_loader, model, loss_f)
test_loss_lst.append(test_loss_value)
test_acc_lst.append(test_acc_value)
print(f"Epoch:{epoch + last_epoch + 1 } Train[Loss:{train_loss_value} Acc:{train_acc_value} ]")
print(f"Epoch:{epoch + last_epoch + 1 } Test[Loss:{test_loss_value} Acc:{test_acc_value} ]")
if __name__ == "__main__":
main()