I meet a problem that it is slower to train with autocast. I experiment on a toy model and find that it keep running slower than normal until a big batch size is set. I tried it on A30, 3090, 2080Ti, 2060 super.
I am confused about the reason and the strategy of batch size setting. A small batch size makes autocast not work but a big batch size would cause crash.
Here is my code:
import torch
import torch.nn as nn
import time
import argparse
parser = argparse.ArgumentParser()
BATCH_SIZE = 1024
# BATCH_SIZE = 10240
class Model(nn.Module):
def __init__(self):
super().__init__()
layer = []
for i in range(50):
layer.append(nn.Linear(512, 512))
self.layer = nn.Sequential(*layer)
def forward(self, x):
y = self.layer(x)
return y
model = Model().cuda()
scaler = torch.cuda.amp.GradScaler()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
loss_fn = nn.MSELoss()
d = []
label = []
for i in range(100):
d.append(torch.randn(BATCH_SIZE, 512).cuda())
label.append(torch.randn(BATCH_SIZE, 512).cuda())
print("################ with autocast #######################")
print_flag = False
time0 = time.time()
for i in range(len(d)):
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(d[i])
if not print_flag:
print("dtype: ", outputs.dtype)
print_flag = True
loss = loss_fn(outputs, label[i])
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# loss.backward()
# optimizer.step()
time1 = time.time()
print("with autocast cost: ", time1 - time0)
#######################################################
print("################ without autocast #######################")
print_flag = False
time0 = time.time()
for i in range(len(d)):
optimizer.zero_grad()
outputs = model(d[i])
if not print_flag:
print("dtype: ", outputs.dtype)
print_flag = True
loss = loss_fn(outputs, label[i])
loss.backward()
optimizer.step()
time1 = time.time()
print("without autocast cost: ", time1 - time0)
when BATCH_SIZE = 1024, the output is (on 3090)
################ with autocast #######################
dtype: torch.float16
with autocast cost: 1.9760982990264893
################ without autocast #######################
dtype: torch.float32
without autocast cost: 1.1353034973144531
when BATCH_SIZE = 10240, the output is
################ with autocast #######################
dtype: torch.float16
with autocast cost: 2.055091619491577
################ without autocast #######################
dtype: torch.float32
without autocast cost: 3.0732078552246094
CUDA operations are executed asynchronously, so you would need to synchronize the code before starting and stopping the timers via torch.cuda.synchronize() or use an event-based profiling. Your current profiling code does not measure the runtime and is invalid.
I have another try but still slower. Here is my code and output. The GPU is 2060 super.
import torch
import torch.nn as nn
import time
import argparse
parser = argparse.ArgumentParser()
class Model(nn.Module):
def __init__(self):
super().__init__()
layer = []
for i in range(5):
layer.append(nn.Linear(128, 128))
self.layer = nn.Sequential(*layer)
def forward(self, x):
y = self.layer(x)
return y
model = Model().cuda()
scaler = torch.cuda.amp.GradScaler()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
loss_fn = nn.MSELoss()
d = []
label = []
for i in range(1000):
d.append(torch.randn(20, 128).cuda())
label.append(torch.randn(20, 128).cuda())
print("################ with autocast #######################")
print_flag = False
torch.cuda.synchronize()
time0 = time.time()
for i in range(len(d)):
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(d[i])
if not print_flag:
print("dtype: ", outputs.dtype)
print_flag = True
loss = loss_fn(outputs, label[i])
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# loss.backward()
# optimizer.step()
torch.cuda.synchronize()
time1 = time.time()
print("with autocast cost: ", time1 - time0)
#######################################################
print("################ without autocast #######################")
print_flag = False
torch.cuda.synchronize()
time0 = time.time()
for i in range(len(d)):
optimizer.zero_grad()
outputs = model(d[i])
if not print_flag:
print("dtype: ", outputs.dtype)
print_flag = True
loss = loss_fn(outputs, label[i])
loss.backward()
optimizer.step()
torch.cuda.synchronize()
time1 = time.time()
print("without autocast cost: ", time1 - time0)
output:
################ with autocast #######################
dtype: torch.float16
with autocast cost: 10.757721424102783
################ without autocast #######################
dtype: torch.float32
without autocast cost: 0.9863979816436768
import torch
import torch.nn as nn
import time
import argparse
parser = argparse.ArgumentParser()
class Model(nn.Module):
def __init__(self):
super().__init__()
layer = []
for i in range(5):
layer.append(nn.Linear(128, 128))
self.layer = nn.Sequential(*layer)
def forward(self, x):
y = self.layer(x)
return y
model = Model().cuda()
scaler = torch.cuda.amp.GradScaler()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
loss_fn = nn.MSELoss()
d = []
label = []
for i in range(1000):
d.append(torch.randn(20, 128).cuda())
label.append(torch.randn(20, 128).cuda())
#################### warmup #####################
for i in range(len(d)):
optimizer.zero_grad()
with torch.cuda.amp.autocast(enabled=True):
outputs = model(d[i])
loss = loss_fn(outputs, label[i])
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
for i in range(len(d)):
optimizer.zero_grad()
outputs = model(d[i])
loss = loss_fn(outputs, label[i])
loss.backward()
optimizer.step()
#################### warmup #####################
print("################ with autocast #######################")
print_flag = False
torch.cuda.synchronize()
time0 = time.time()
for i in range(len(d)):
optimizer.zero_grad()
with torch.cuda.amp.autocast(enabled=True):
outputs = model(d[i])
if not print_flag:
print("dtype: ", outputs.dtype)
print_flag = True
loss = loss_fn(outputs, label[i])
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# loss.backward()
# optimizer.step()
torch.cuda.synchronize()
time1 = time.time()
print("with autocast cost: ", time1 - time0)
#######################################################
print("################ without autocast #######################")
print_flag = False
torch.cuda.synchronize()
time0 = time.time()
for i in range(len(d)):
optimizer.zero_grad()
outputs = model(d[i])
if not print_flag:
print("dtype: ", outputs.dtype)
print_flag = True
loss = loss_fn(outputs, label[i])
loss.backward()
optimizer.step()
torch.cuda.synchronize()
time1 = time.time()
print("without autocast cost: ", time1 - time0)
output:
################ with autocast #######################
dtype: torch.float16
with autocast cost: 1.8655202388763428
################ without autocast #######################
dtype: torch.float32
without autocast cost: 0.9314119815826416
Thanks for the follow-up. On my 2080Ti I see a runtime of:
################ with autocast #######################
dtype: torch.float16
with autocast cost: 0.34975481033325195
################ without autocast #######################
dtype: torch.float32
without autocast cost: 0.21597671508789062
and after checking the profile my guess that this tiny workload is CPU-limited and is thus not seeing a speedup seems to be valid.
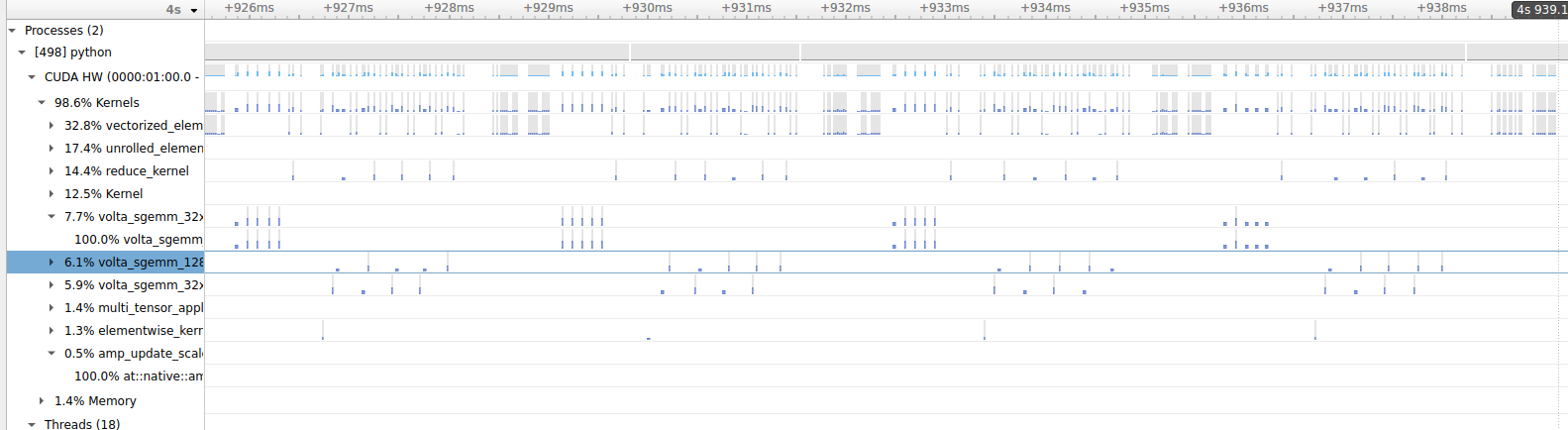
With autocast:
As you can see, both use cases suffer from huge white spaces between the actual kernel runtimes.
While the kernel execution times are faster using autocast, the overhead of loss scaling etc. is visible since the actual model computation is too small to hide it and you are seeing a slowdown in the end.
To see a speedup, you would have to scale up the actual workload by using a larger model instead of a toy model or by increasing the batch size.
You can recreate the same profiles via Nsight Systems to analyze them further.
PS: if you want to speedup these tiny workloads, you might want to check CUDA Graphs.