I’m new to pytorch and trying to train a GNN with my limited knowledge…However, I met a problem with CUDA running out of memory. My dataset contains graphs with variable sizes.
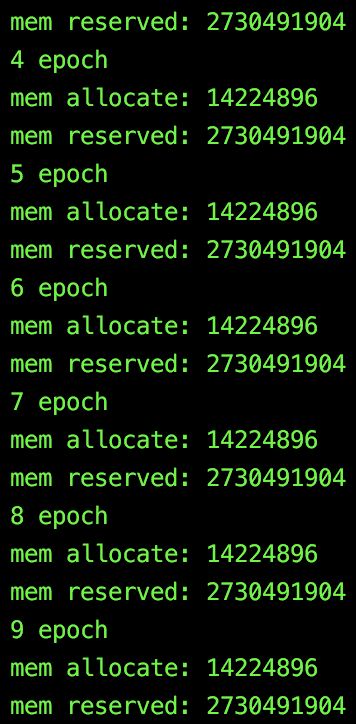
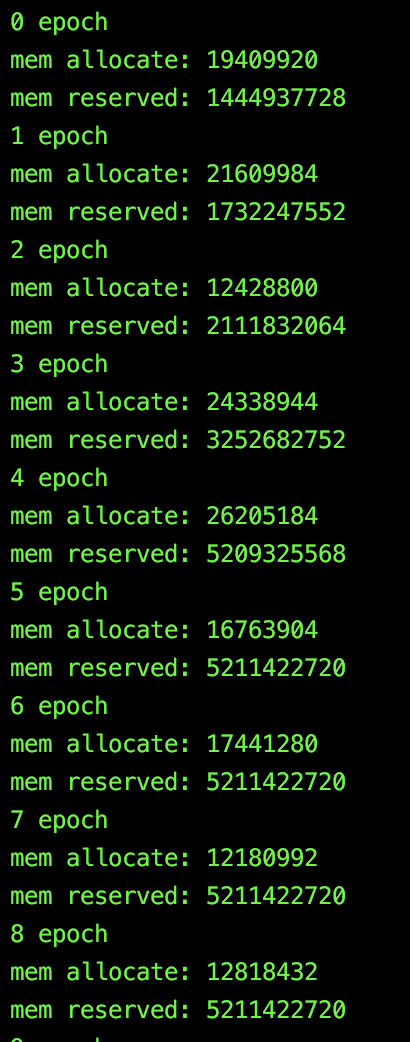
By printing out the memory allocated by Cuda and the memory reserved by Cuda, it seems if I don’t use a sampler in DataLoader, the memory reserved stays unchanged, but if I use a sampler (with replacement = True), the memory reserved is different, and keep increasing. I’m guessing that if I unluckily sampled a bunch of large graphs needs a lot more memory. However, why after each iteration, those memory are not freed? Is this because I used the sampler in a wrong way?
I’m currently using it by:
loader = GraphDataLoader(ds_train, batch_size=batch_size, drop_last=True, sampler=sampler)
Here is the two memory usage comparison:
Without sampler:
Hi there,
Thanks for replying!
GraphDataLoader is just the DataLoader from torch_geometric and Sampler is the torch.utils.data’ s WeightedRandomSampler
Here is the code:
from torch_geometric.data import DataLoader as GraphDataLoader
from torch_geometric.data import Data
from automate.nn.mate_dataset import RawMateDataset
import automate
from torch.utils.data import Dataset, WeightedRandomSampler
import torch
import numpy as np
from automate.nn.modules.graph_dataset import GraphDataset
from automate.nn.modules.graph_classifier import GraphClassifier
def train_GNN(
path,
filters,
experiment_name,
save_dir,
batch_size = 32,
n_examples = -1,
lr = 0.001,
save = False):
print('creating raw mate dataset')
ds_raw = automate.nn.mate_dataset.RawMateDataset({'mate_list':path, 'filters':filters})
print('creating graph dataset')
ds_graph = GraphDataset(ds_raw)
if n_examples == -1:
n_examples = len(ds_graph)
n_examples = int(.95*n_examples)
ds_train, ds_val = torch.utils.data.random_split(ds_graph, (n_examples, len(ds_graph) - n_examples))
print(f'have {len(ds_train)} training examples')
print(f'have {len(ds_val)} training examples')
train_weights = ds_raw.weights[ds_train.indices]
sampler = WeightedRandomSampler(train_weights, len(train_weights))
print('created loader')
loader = GraphDataLoader(ds_train, batch_size=batch_size, drop_last=True, sampler=sampler)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
classifier = GraphClassifier(v_in=71, e_in=6, v_g=30, e_g=6, v_out=200, mc_out=22, i_types=11).float().to(device)
optimizer = torch.optim.Adam(classifier.parameters(), lr=lr)
loss = torch.nn.CrossEntropyLoss()
best = -1
print('starting training')
classifier.train()
for epoch in range(1000):
try:
if save and epoch % 100 == 0 and epoch != 0:
save_model(classifier, save_dir, epoch)
epoch_loss = 0
total = 0
correct = 0
classifier.train()
for i, data in enumerate(loader):
optimizer.zero_grad()
data = data.to(device)
target = torch.tensor(data.mate_type).to(device)
preds = classifier(data)
err = loss(preds, target)
_, preds_temp = torch.max(preds.data, 1)
total += len(target)
correct += (preds_temp == target).sum().item()
epoch_loss += err.item()
err.backward()
optimizer.step()
print(f'Epoch {epoch + 1} Loss = {epoch_loss/(i+1)} Train Accuracy = {correct / total}')