Hi, I want to train a big dataset with 1M images. I have a RTX2060 with 6Gbs of VRAM.
I am using a pretrained Alexnet with some extra layers and once I upload my model to my GPU It uses approximately 1Gb from it leaving 4.4 Gbs free.
Then I try to train my images but my model crashes at the first batch when updating the weights of the network due to lack of memory in my GPU. I tried even with batch_size = 1.
I am using Adam optimizer set to update only the parameters that requires_grad = True which are just the last two layers.
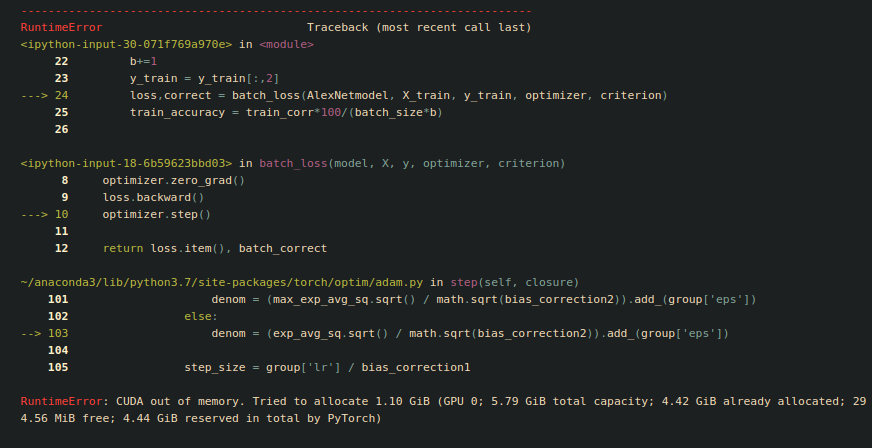
Am I doing something wrong or can I do something to fix this issue?
Am I doing something wrong or simply my hardware isn’t enough for such a problem?
How can I solve this issue?