Hi all,
I’m facing these issue in these days but I haven’t found a solution.
I’m using the simpletransformers library on github, a wrapper for the transformers library by HuggingFace. The main code of the model that I’m trying to train is here.
I’ve trained the model correctly and I would like to continue the training for more epochs, so I’ve loaded the model simply using:
model = T5Model("/PATHtoCHECKPOINT")
Then I’ve started the training with:
model.train_model(train_df, eval_data=eval_df)
The training starts and the first observation is that the loss spikes at a higher value w.r.t the value of the last checkpoint, as shown in the image:
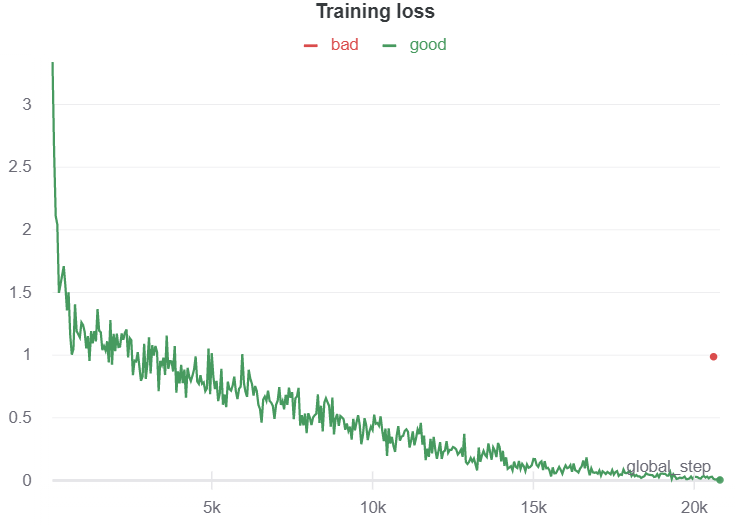
After some steps the loss starts to decrease and then this error is thrown:
Traceback (most recent call last):
File "TINIA_doubleTraining.py", line 112, in <module>
model.train_model(train_df, eval_data=eval_df) #,args={'num_train_epochs': 5, 'learning_rate':2e-5}) #args=model_args, sacreBLEU=sacreBLEU)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/simpletransformers/t5/t5_model.py", line 165, in train_model
global_step, training_details = self.train(
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/simpletransformers/t5/t5_model.py", line 418, in train
results = self.eval_model(
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/simpletransformers/t5/t5_model.py", line 613, in eval_model
result = self.evaluate(eval_dataset, output_dir, verbose=verbose, silent=silent, **kwargs)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/simpletransformers/t5/t5_model.py", line 673, in evaluate
outputs = model(**inputs)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 155, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 165, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 85, in parallel_apply
output.reraise()
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/_utils.py", line 395, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in replica 1 on device 5.
Original Traceback (most recent call last):
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 60, in _worker
output = module(*input, **kwargs)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 155, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 165, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 85, in parallel_apply
output.reraise()
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/_utils.py", line 395, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in replica 0 on device 0.
Original Traceback (most recent call last):
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 60, in _worker
output = module(*input, **kwargs)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/datadrive/data/T5/transformers/src/transformers/modeling_t5.py", line 1169, in forward
encoder_outputs = self.encoder(
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/datadrive/data/T5/transformers/src/transformers/modeling_t5.py", line 711, in forward
inputs_embeds = self.embed_tokens(input_ids)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/modules/sparse.py", line 124, in forward
return F.embedding(
File "/home/ubuntu/anaconda3/envs/nlp_venv/lib/python3.8/site-packages/torch/nn/functional.py", line 1814, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: arguments are located on different GPUs at /opt/conda/conda-bld/pytorch_1595629395347/work/aten/src/THC/generic/THCTensorIndex.cu:403
I’m using AWS EC2 with 8 GPUs, so I’ve tried the same code with a machine with 1 GPU only and the code starts, has this peaks at the beginning of each epoch but I don’t get any error, therefore the problem is related to the DataParallel.
Any suggestion?
Thanks!