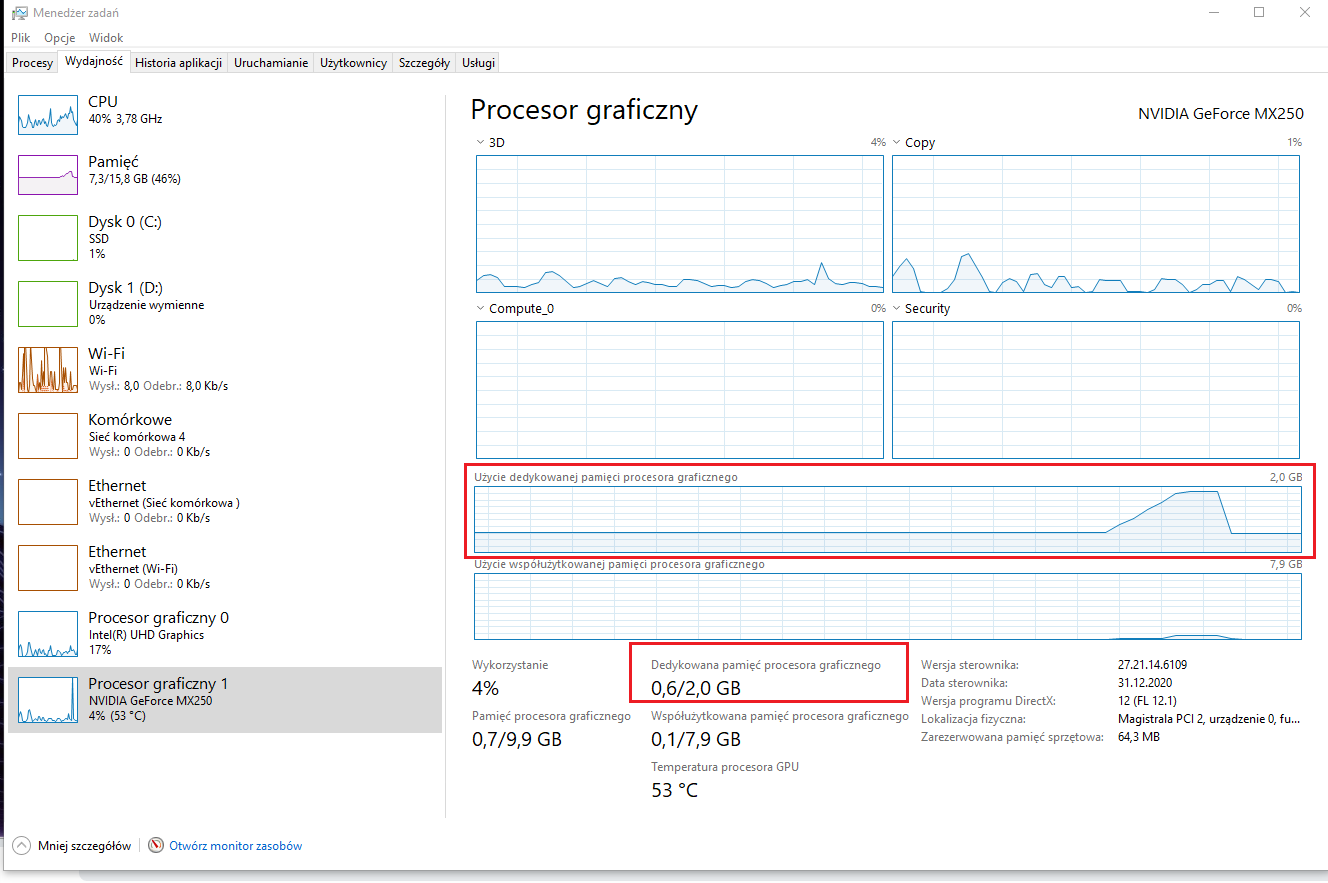
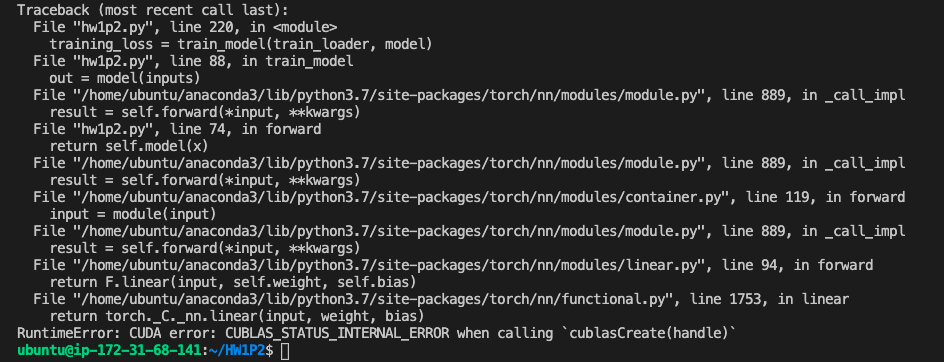
Hi, I’m getting the same error.
I’m using the GPT2ForSequenceClassification from transformers by hugginface.
import torch
print(torch.__version__)
# out
1.7.1+cu101
import transformers
print(transformers.__version__)
#out
4.3.3
! nvidia-smi
#out
NVIDIA-SMI 460.39 Driver Version: 460.32.03 CUDA Version: 11.2 |
I tried running this on colab as well as on another machine with higher RAM.
This is the stack trace:
RuntimeError Traceback (most recent call last)
<ipython-input-19-3435b262f1ae> in <module>()
----> 1 trainer.train()
12 frames
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in train(self, resume_from_checkpoint, trial, **kwargs)
938 tr_loss += self.training_step(model, inputs)
939 else:
--> 940 tr_loss += self.training_step(model, inputs)
941 self._total_flos += self.floating_point_ops(inputs)
942
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in training_step(self, model, inputs)
1302 loss = self.compute_loss(model, inputs)
1303 else:
-> 1304 loss = self.compute_loss(model, inputs)
1305
1306 if self.args.n_gpu > 1:
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in compute_loss(self, model, inputs, return_outputs)
1332 else:
1333 labels = None
-> 1334 outputs = model(**inputs)
1335 # Save past state if it exists
1336 # TODO: this needs to be fixed and made cleaner later.
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/gpt2/modeling_gpt2.py in forward(self, input_ids, past_key_values, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, labels, use_cache, output_attentions, output_hidden_states, return_dict)
1206 output_attentions=output_attentions,
1207 output_hidden_states=output_hidden_states,
-> 1208 return_dict=return_dict,
1209 )
1210 hidden_states = transformer_outputs[0]
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/gpt2/modeling_gpt2.py in forward(self, input_ids, past_key_values, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, use_cache, output_attentions, output_hidden_states, return_dict)
753 encoder_attention_mask=encoder_attention_mask,
754 use_cache=use_cache,
--> 755 output_attentions=output_attentions,
756 )
757
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/gpt2/modeling_gpt2.py in forward(self, hidden_states, layer_past, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, use_cache, output_attentions)
293 head_mask=head_mask,
294 use_cache=use_cache,
--> 295 output_attentions=output_attentions,
296 )
297 attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/gpt2/modeling_gpt2.py in forward(self, hidden_states, layer_past, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, use_cache, output_attentions)
223 attention_mask = encoder_attention_mask
224 else:
--> 225 query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
226
227 query = self.split_heads(query)
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/modeling_utils.py in forward(self, x)
1204 def forward(self, x):
1205 size_out = x.size()[:-1] + (self.nf,)
-> 1206 x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
1207 x = x.view(*size_out)
1208 return x
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
From the stack trace, this is the line that’s causing the error. This line belongs to the follwing class:
class Conv1D(nn.Module):
"""
1D-convolutional layer as defined by Radford et al. for OpenAI GPT (and also used in GPT-2).
Basically works like a linear layer but the weights are transposed.
Args:
nf (:obj:`int`): The number of output features.
nx (:obj:`int`): The number of input features.
"""
def __init__(self, nf, nx):
super().__init__()
self.nf = nf
w = torch.empty(nx, nf)
nn.init.normal_(w, std=0.02)
self.weight = nn.Parameter(w)
self.bias = nn.Parameter(torch.zeros(nf))
def forward(self, x):
size_out = x.size()[:-1] + (self.nf,)
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
x = x.view(*size_out)
return x
I tried creating a random tensor and passing it to the Conv1D class but that ran fine. Not sure if that helps in narrowing down where the problem is:
nx = 768
n_state = nx
conv = Conv1D_i(3 * n_state, nx)
hidden_states = torch.randn([16, 1024, 768])
conv(hidden_states) # This runs fine.