Hi, I got this “device-side assert triggered” while training fasterRCNN model using trochvision. I used BDD100K Object detection dataset. While training, the model did iterated through the inputs a bit (check my screenshots below) and then crashes with that error message when trained with CUDA.
I have 11 classes including the background and it ranged from 0 to 10.
I checked every detail where i could make mistake from my sides and I could not really pin point why is this error occurring. Can Someone please help me with this issue. I would really appreciate it.
Following is my env config setup:
PyTorch version: 1.7.1
Is debug build: False
CUDA used to build PyTorch: 10.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.2 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: Could not collect
CMake version: version 3.19.6
Python version: 3.7 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: 10.1.243
GPU models and configuration: GPU 0: GeForce GTX 1080
Nvidia driver version: 418.197.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.0
[pip3] torch==1.7.1
[pip3] torchaudio==0.9.0
[pip3] torchtext==0.4.0
[pip3] torchvision==0.8.2
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.1.243 h6bb024c_0
[conda] magma-cuda110 2.5.2 1 pytorch
[conda] mkl 2021.2.0 h06a4308_296
[conda] mkl-include 2020.2 256
[conda] mkl-service 2.3.0 py37h27cfd23_1
[conda] mkl_fft 1.3.0 py37h42c9631_2
[conda] mkl_random 1.2.1 py37ha9443f7_2
[conda] numpy 1.20.2 py37h2d18471_0
[conda] numpy-base 1.20.2 py37hfae3a4d_0
[conda] pytorch 1.7.1 py3.7_cuda10.1.243_cudnn7.6.3_0 pytorch
[conda] torchaudio 0.9.0 pypi_0 pypi
[conda] torchtext 0.4.0 pypi_0 pypi
[conda] torchvision 0.8.2 py37_cu101 pytorch
This is the error message when trained with CUDA:
/opt/conda/conda-bld/pytorch_1607370141920/work/aten/src/ATen/native/cuda/IndexKernel.cu:84: operator(): block: [0,0,0], thread: [77,0,0] Assertion index >= -sizes[i] && index < sizes[i] && "index out of bounds" failed.
/opt/conda/conda-bld/pytorch_1607370141920/work/aten/src/ATen/native/cuda/IndexKernel.cu:84: operator(): block: [1,0,0], thread: [107,0,0] Assertion index >= -sizes[i] && index < sizes[i] && "index out of bounds" failed.
/opt/conda/conda-bld/pytorch_1607370141920/work/aten/src/ATen/native/cuda/IndexKernel.cu:84: operator(): block: [0,0,0], thread: [23,0,0] Assertion index >= -sizes[i] && index < sizes[i] && "index out of bounds" failed.
/opt/conda/conda-bld/pytorch_1607370141920/work/aten/src/ATen/native/cuda/IndexKernel.cu:84: operator(): block: [3,0,0], thread: [94,0,0] Assertion index >= -sizes[i] && index < sizes[i] && "index out of bounds" failed.
/opt/conda/conda-bld/pytorch_1607370141920/work/aten/src/ATen/native/cuda/IndexKernel.cu:84: operator(): block: [0,0,0], thread: [125,0,0] Assertion index >= -sizes[i] && index < sizes[i] && "index out of bounds" failed.
Traceback (most recent call last):
File “test.py”, line 197, in
train()
File “test.py”, line 185, in train
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
File “/home/student/Desktop/my_test/engine.py”, line 30, in train_one_epoch
loss_dict = model(images, targets)
File “/home/student/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py”, line 727, in _call_impl
result = self.forward(*input, **kwargs)
File “/home/student/anaconda3/lib/python3.7/site-packages/torchvision/models/detection/generalized_rcnn.py”, line 100, in forward
detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
File “/home/student/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py”, line 727, in _call_impl
result = self.forward(*input, **kwargs)
File “/home/student/anaconda3/lib/python3.7/site-packages/torchvision/models/detection/roi_heads.py”, line 746, in forward
proposals, matched_idxs, labels, regression_targets = self.select_training_samples(proposals, targets)
File “/home/student/anaconda3/lib/python3.7/site-packages/torchvision/models/detection/roi_heads.py”, line 645, in select_training_samples
matched_idxs, labels = self.assign_targets_to_proposals(proposals, gt_boxes, gt_labels)
File “/home/student/anaconda3/lib/python3.7/site-packages/torchvision/models/detection/roi_heads.py”, line 585, in assign_targets_to_proposals
labels_in_image = gt_labels_in_image[clamped_matched_idxs_in_image]
RuntimeError: CUDA error: device-side assert triggered
This is the error message when trained with CPU:
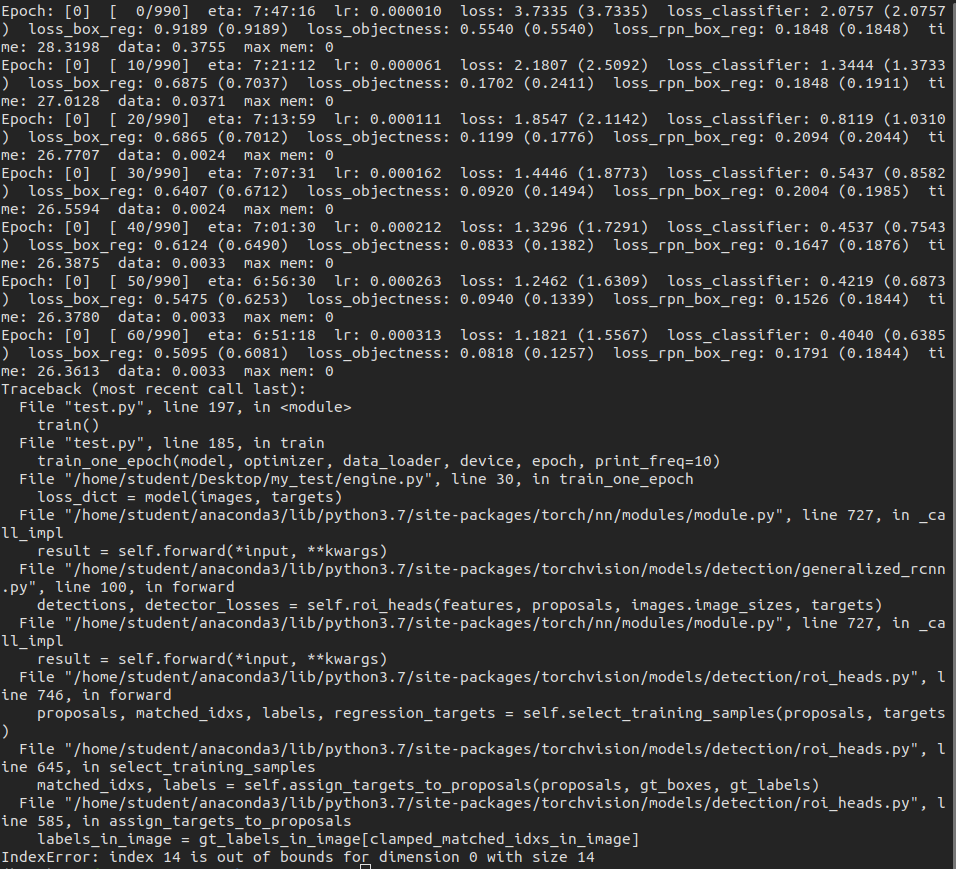
Here is my target(label) format looks like:
Target: {‘labels’: tensor([ 5, 3, 3, 3, 3, 3, 3, 4, 10, 9, 3, 3, 10, 3]), ‘boxes’: tensor([[ 1.2478, 125.1739, 214.4690, 510.1283],
[475.3943, 323.1683, 665.0529, 471.6510],
[398.0335, 336.8936, 474.1465, 388.0515],
[207.1272, 363.0964, 279.4969, 400.5563],
[628.8680, 329.4071, 658.8141, 367.5104],
[676.2827, 319.4250, 690.0080, 336.8936],
[691.2557, 315.6818, 703.7333, 330.6548],
[611.3995, 311.9385, 663.8052, 330.6548],
[504.0926, 311.9385, 514.0746, 323.1683],
[277.0014, 304.4520, 299.4610, 320.6728],
[339.3891, 350.4868, 383.5327, 366.8397],
[279.4969, 363.0964, 338.1414, 384.5341],
[535.2865, 294.4699, 572.7191, 314.4340],
[706.2288, 311.9385, 718.7063, 323.1683]])}
Here is the shape of the input(image) looks like:
IMage shape: torch.Size([3, 720, 1280])
Here is my Custom data preparation code:
class PennFudanDataset(object):
def init(self, root, transforms):
self.root = root
self.transforms = transforms
self.imgs = list(sorted(os.listdir(os.path.join(root, "img"))))
self.json_labels = self.get_json()
def get_json(self):
json_file_path = os.path.join(self.root,"det_label.json")
with open(json_file_path) as f:
json_labels = json.load(f)
return json_labels
def __getitem__(self, idx):
categories = ["pedestrian", "rider", "car", "truck", "bus", "train", "motorcycle", "bicycle", "traffic light", "traffic sign"]
cat_ids, boxes = [],[]
img_path = os.path.join(self.root, "img", self.imgs[idx])
json_label = self.json_labels[idx]
img = cv2.imread(img_path)
for l in json_label["labels"]:
for id, cat in enumerate(categories, start = 1):
if cat == l["category"]:
cat_ids.append(id)
box = l["box2d"]
boxes.append([box["x1"], box["y1"], box["x2"], box["y2"]])
t = {}
t["labels"] = torch.as_tensor(cat_ids, dtype=torch.int64)
t["boxes"] = torch.as_tensor(boxes, dtype=torch.float32)
t["image_id"] = torch.tensor([idx])
#print("Target:",t)
if self.transforms is not None:
img, target = self.transforms(img, t)
return img, target
def __len__(self):
return len(self.imgs)
Here is the model definition code:
def get_model_instance_segmentation(num_classes):
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
Here is the training and supporting function code:
def get_transform(train):
transforms =
transforms.append(T.ToTensor())
return T.Compose(transforms)
def train():
# train on the GPU or on the CPU, if a GPU is not available
os.environ[‘CUDA_LAUNCH_BLOCKING’]= “1”
device = torch.device(‘cuda’) if torch.cuda.is_available() else torch.device(‘cpu’)
# our dataset has two classes only - background and person
num_classes = 11
# use our dataset and defined transformations
dataset = PennFudanDataset(os.path.join(‘det_final_label_image’,‘train’), get_transform(train= False))
dataset_test = PennFudanDataset(os.path.join(‘det_final_label_image’,‘val’), get_transform(train=False))
# define training and validation data loaders
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=5, shuffle=True, num_workers=10,
collate_fn=utils.collate_fn)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=1, shuffle=False, num_workers=10,
collate_fn=utils.collate_fn)
# get the model using our helper function
model = get_model_instance_segmentation(num_classes)
# move model to the right device
model.to(device)
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
#print("Optimiser Params:", params)
optimizer = torch.optim.Adam(params, lr=0.005, betas= (0.9,0.999),weight_decay= 0.0005)
# and a learning rate scheduler
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=1, gamma=0.1)
# let's train it for 10 epochs
num_epochs = 2
for epoch in range(num_epochs):
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
print("That's it!")
if name == “main”:
train()