my batch size is 1 , but amount of data is huge
In that case you would have to reduce the amount of the data (number of images, if I understand the use case correctly).
But I need to take complete data, in my program.
The ~11GB are apparently not enough for all 240 images.
You could try to use torch.utils.checkpoint to trade compute for memory, reduce the model, or possible use model sharding on multiple GPUs.
Can DataParallel help but there also I get error.
nn.DataParallel could be used, if your batch size is >1.
However, as far as I understand your use case your batch size is 1 and the number of images is in another dimension, which is apparently not the batch dimension?
Using DataParallel ,I m getting error:
File “/.local/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py”, line 149, in forward
“them on device: {}”.format(self.src_device_obj, t.device))
RuntimeError: module must have its parameters and buffers on device cuda:0 (device_ids[0]) but found one of them on device: cuda:1
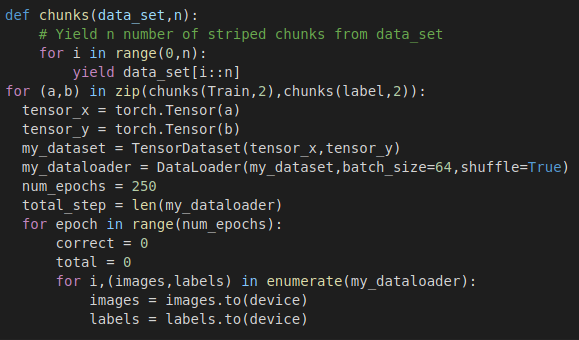
I guess you are using some sort of time distributed CNN-LSTM architecture. When I was using the same, I used to face a lot of memory issues. One thing you can do is to avoid loading the entire data in the memory. You can divide the data into chunks and load the chunks one by one to train your model. For example, the following code divides the data into two chunks and proceed for the training of the model.