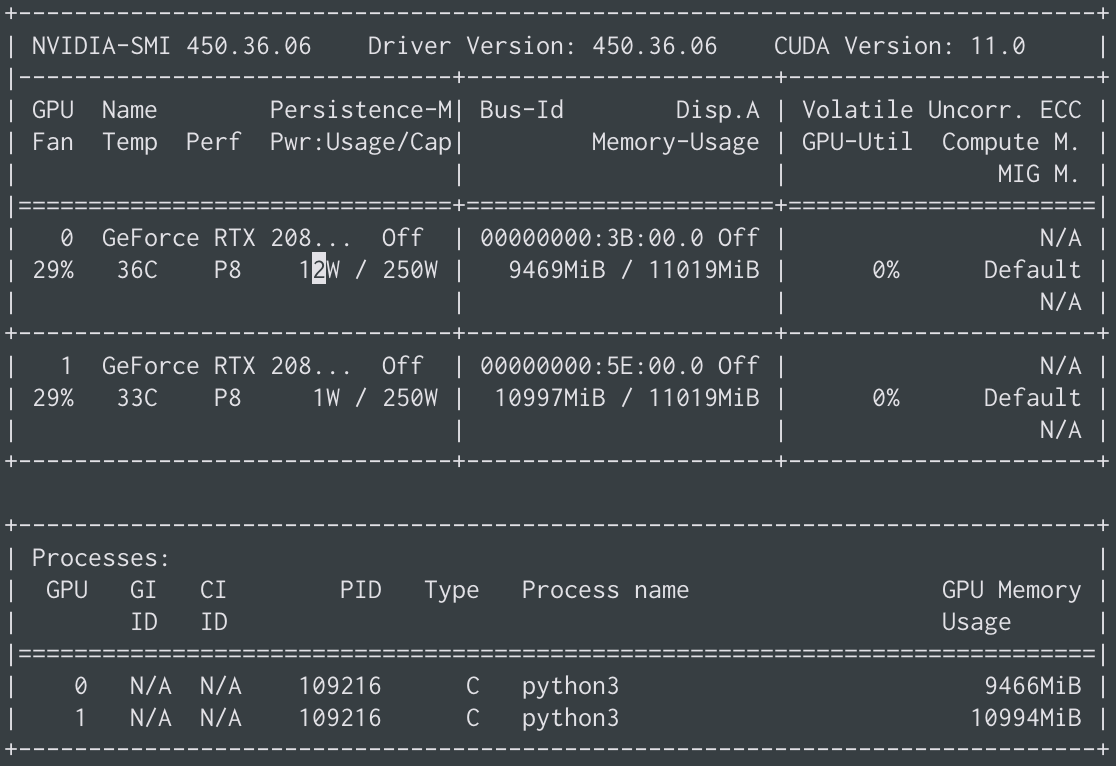
I had RuntimeError: CUDA out of memory. Tried to allocate 66.00 MiB (GPU 1; 10.76 GiB total capacity; 9.67 GiB already allocated; 25.44 MiB free; 9.86 GiB reserved in total by PyTorch)
What should I do?..![]()
This save and load function code is
def save(self):
"""
Saves the current model and related training parameters into a subdirectory of the checkpoint directory.
The name of the subdirectory is the current local time in Y_M_D_H_M_S format.
"""
date_time = time.strftime('%Y_%m_%d_%H_%M_%S', time.localtime())
path = os.path.join(self.SAVE_PATH, self.CHECKPOINT_DIR_NAME, date_time)
if os.path.exists(path):
shutil.rmtree(path) # delete path dir & sub-files
os.makedirs(path)
trainer_states = {
'optimizer': self.optimizer,
'trainset_list': self.trainset_list,
'validset': self.validset,
'epoch': self.epoch
}
torch.save(trainer_states, os.path.join(path, self.TRAINER_STATE_NAME))
torch.save(self.model, os.path.join(path, self.MODEL_NAME))
torch.save(self.model.state_dict(), os.path.join(path, 'model_state_dict.pt')) ##
torch.save({
'model': self.model.state_dict(),
'optimizer': self.optimizer,
'trainset_list': self.trainset_list,
'validset': self.validset,
'epoch': self.epoch
}, os.path.join(path, 'all.tar')) ##
logger.info('save checkpoints\n%s\n%s'
% (os.path.join(path, self.TRAINER_STATE_NAME),
os.path.join(path, self.MODEL_NAME)))
def load(self, path, first=True):
"""
Loads a Checkpoint object that was previously saved to disk.
Args:
path (str): path to the checkpoint subdirectory
Returns:
checkpoint (Checkpoint): checkpoint object with fields copied from those stored on disk
"""
logger.info('load checkpoints\n%s\n%s'
% (os.path.join(path, self.TRAINER_STATE_NAME),
os.path.join(path, self.MODEL_NAME)))
if torch.cuda.is_available():
resume_checkpoint = torch.load(os.path.join(path, self.TRAINER_STATE_NAME))
model = torch.load(os.path.join(path, self.MODEL_NAME))
checkpoint = torch.load(os.path.join(path, 'all.tar')) ##
model.load_state_dict(checkpoint['model']) ##
else:
resume_checkpoint = torch.load(os.path.join(path, self.TRAINER_STATE_NAME), map_location=lambda storage, loc: storage)#
model = torch.load(os.path.join(path, self.MODEL_NAME), map_location=lambda storage, loc: storage)
if isinstance(model, SpeechSeq2seq):
if isinstance(model, nn.DataParallel):
model.module.flatten_parameters() # make RNN parameters contiguous
else:
model.flatten_parameters()
return Checkpoint(
model=model, optimizer=resume_checkpoint['optimizer'], epoch=resume_checkpoint['epoch'],
trainset_list=resume_checkpoint['trainset_list'],
validset=resume_checkpoint['validset']
)
I used code this github(GitHub - sooftware/kospeech: Open-Source Toolkit for End-to-End Korean Automatic Speech Recognition leveraging PyTorch and Hydra.)
Traceback (most recent call last):
File "./main.py", line 113, in <module>
main()
File "./main.py", line 109, in main
train(opt)
File "./main.py", line 87, in train
resume=opt.resume
File "../kospeech/trainer/supervised_trainer.py", line 147, in train
train_queue, teacher_forcing_ratio)
File "../kospeech/trainer/supervised_trainer.py", line 232, in __train_epoches
targets=targets, teacher_forcing_ratio=teacher_forcing_ratio)
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 550, in __$
all__
result = self.forward(*input, **kwargs)
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 15$
, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 165
, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 85
, in parallel_apply
output.reraise()
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/_utils.py", line 395, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in replica 1 on device 1. [6/1849]
Original Traceback (most recent call last):
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 60
, in _worker
output = module(*input, **kwargs)
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 550, in __c
all__
result = self.forward(*input, **kwargs)
File "../kospeech/models/acoustic/seq2seq/seq2seq.py", line 51, in forward
result = self.decoder(targets, output, teacher_forcing_ratio, return_decode_dict)
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 550, in __c
all__
result = self.forward(*input, **kwargs)
File "../kospeech/models/acoustic/seq2seq/decoder.py", line 175, in forward
step_output, hidden, attn = self.forward_step(input_var, hidden, encoder_outputs, attn)
File "../kospeech/models/acoustic/seq2seq/decoder.py", line 126, in forward_step
context, attn = self.attention(output, encoder_outputs, encoder_outputs)
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 550, in __c
all__
result = self.forward(*input, **kwargs)
File "../kospeech/models/acoustic/transformer/sublayers.py", line 22, in forward
output = self.sublayer(*args)
File "/home/stt_py/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 550, in __c
all__
result = self.forward(*input, **kwargs)
File "../kospeech/models/attention.py", line 96, in forward
key = key.permute(2, 0, 1, 3).contiguous().view(batch_size * self.num_heads, -1, self.d_head)
# BNxK_LENxD
RuntimeError: CUDA out of memory. Tried to allocate 32.00 MiB (GPU 1; 10.76 GiB total capacity; 9.56
GiB already allocated; 22.44 MiB free; 9.86 GiB reserved in total by PyTorch)