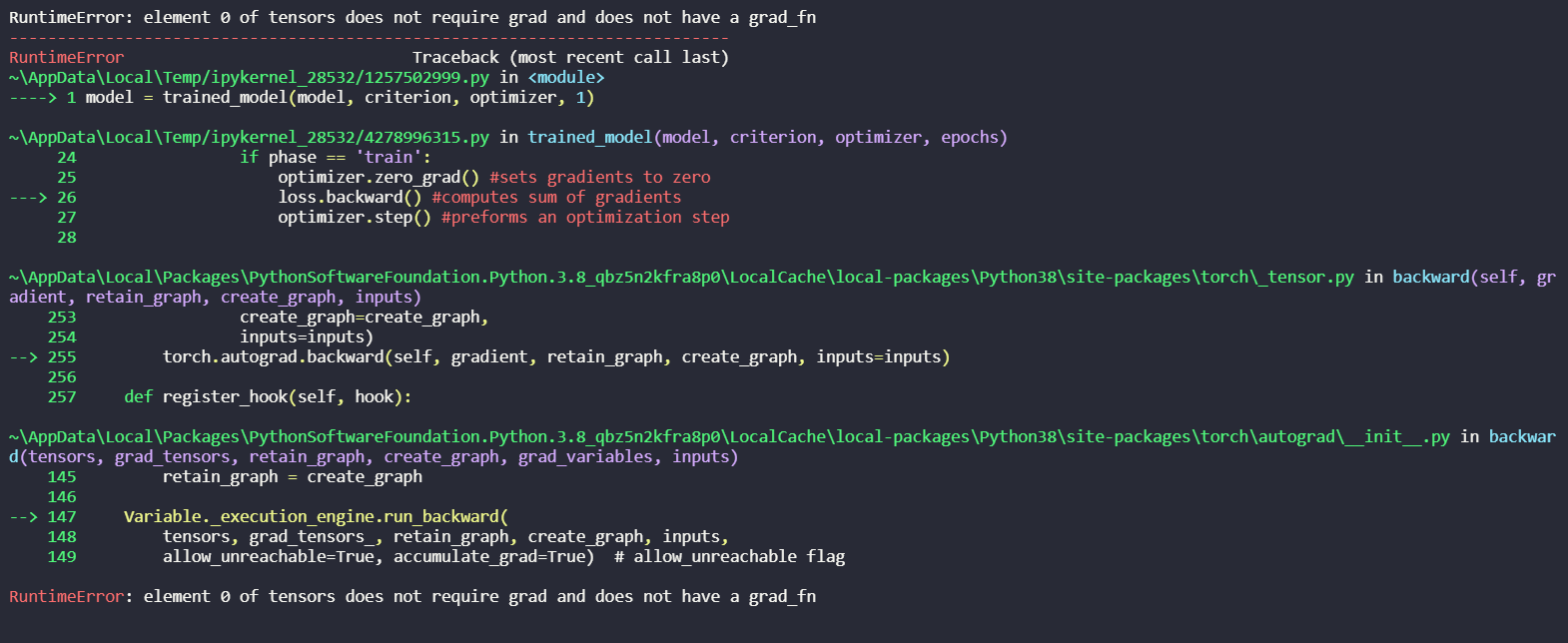
Hey everybody,
I’ve just started out and have been trying to debug this but don’t understand what’s wrong.
Would really appreciate the help!
Regards!
def trained_model(model, criterion, optimizer, epochs):
for epoch in range(epochs):
print('Epoch:', str(epoch+1) + '/' + str(epochs))
print('-'*10)
for phase in ['train', 'validation']:
if phase == 'train':
model.train() #this trains the model
else:
model.eval() #this evaluates the model
running_loss, running_corrects = 0.0, 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device) #convert inputs to cpu or cuda
labels = labels.to(device) #convert labels to cpu or cuda
outputs = model(inputs) #outputs is inputs being fed to the model
loss = criterion(outputs, labels) #outputs are fed into the model
# loss.requires_grad = True
if phase == 'train':
optimizer.zero_grad() #sets gradients to zero
loss.backward() #computes sum of gradients
optimizer.step() #preforms an optimization step
_, preds = torch.max(outputs, 1) #max elements of outputs with output dimension of one
running_loss += loss.item() * inputs.size(0) #loss multiplied by the first dimension of inputs
running_corrects += torch.sum(preds == labels.data) #sum of all the correct predictions
epoch_loss = running_loss / len(data_images[phase]) #this is the epoch loss
epoch_accuracy = running_corrects.double() / len(data_images[phase]) #this is the epoch accuracy
print(phase, ' loss:', epoch_loss, 'epoch_accuracy:', epoch_accuracy)
return model