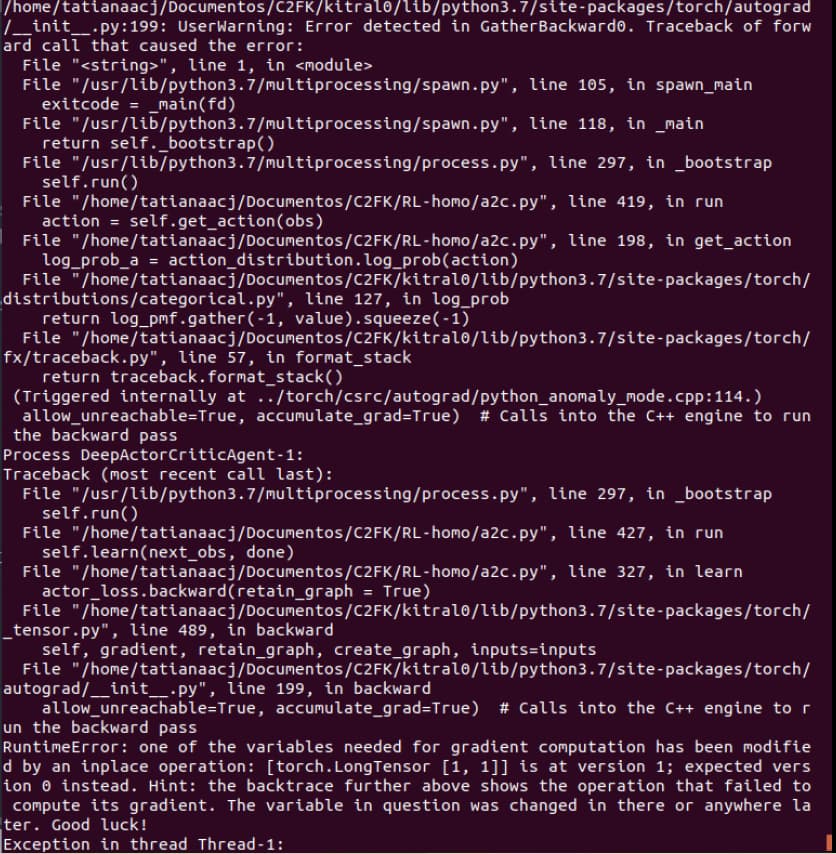
Hi!
I’m working on A2C algorithm for similar enviroments. A2C has learned the optimal solution for 2 error-free environments. But, while training some of the other environments the error is thrown:
RuntimeError: one of the variables needed for gradient computation has been modified by inplace operation: [torch.LongTensor[1,1]] is at version 1; expected version 0 instead.
As I mentioned at the beginning, all the environments are very similar to each other. They all try to solve the same problem and their main difference lies in the number of actions available, what each action does in the environment and the calculation of the reward.
It’s the first time that I work with neural networks (CNN) and with RL algorithms. I’ve read other posts about the same error, I’ve made the mentioned recommendations, I’ve reviewed the code… but I still can’t find the reason for the problem, let alone how to fix it. Especially, why it works perfectly in 2 environments and not in 2 others that I’ve tested so far.
I’m using PyTorch=1.13.1. I really appreciate your help:
The A2C algorithm code is as follows:
class DeepActorCriticAgent(mp.Process):
def __init__(self, id, env_name, agent_params, env_params):
super(DeepActorCriticAgent, self).__init__()
self.id = id
self.actor_name = "Actor " + str(self.id)
self.env_name = env_name
self.params = agent_params
self.env_conf = env_params
self.policy = self.discrete_policy
self.gamma = self.params["gamma"]
self.firebreaks_num = self.env_conf["firebreak_num"]
self.nsims_env = self.env_conf["nsims"]
self.trajectory = []
self.rewards = []
self.global_step_num = 0
self.best_mean_reward = -float("inf")
self.best_reward = -float("inf")
self.saved_params = False
def discrete_policy(self, obs):
logits = self.actor(obs)
value = self.critic(obs)
self.logits = logits.to(torch.device("cpu"))
self.value = value.to(torch.device("cpu"))
self.action_distribution = Categorical(logits = self.logits)
return self.action_distribution
def preprocess_obs(self, obs):
aux_list = []
for i in range(len(obs)):
aux = torch.Tensor(np.array(np.reshape(obs[i], self.env.grid_size()[0:2])))
aux_list.append(aux)
aux_tuple = tuple(aux_list)
obs = torch.stack(aux_tuple)
return obs
def get_action(self, obs):
obs = self.preprocess_obs(obs)
action_distribution = self.policy(obs)
value = self.value
action = action_distribution.sample()
log_prob_a = action_distribution.log_prob(action)
self.trajectory.append(Transition(obs, value, action, log_prob_a))
return action
def calculate_n_step_return(self, n_step_rewards, final_state, done, gamma):
g_t_n_s = list()
with torch.no_grad():
g_t_n = torch.tensor([[0]]).float() if done else self.critic(self.preprocess_obs(final_state)).cpu()
for r_t in n_step_rewards[::-1]:
g_t_n = torch.tensor(r_t).float() + gamma * g_t_n
g_t_n_s.insert(0, g_t_n)
return g_t_n_s
def calculate_loss(self, trajectory, td_targets):
n_step_trayectory = Transition(*zip(*trajectory))
v_s = n_step_trayectory.value_s
log_prob_a = n_step_trayectory.log_prob_a
actor_losses = []
critic_losses = []
for td_target, critic_prediction, log_p_a in zip(td_targets, v_s, log_prob_a):
td_error = td_target - critic_prediction
actor_losses.append(- log_p_a * td_error)
critic_losses.append(F.smooth_l1_loss(critic_prediction, td_target))
actor_loss = torch.stack(actor_losses).mean() - self.action_distribution.entropy().mean()
critic_loss = torch.stack(critic_losses).mean()
return actor_loss, critic_loss
def learn(self, n_th_observation, done):
td_targets = self.calculate_n_step_return(self.rewards, n_th_observation, done, self.gamma)
actor_loss, critic_loss = self.calculate_loss(self.trajectory, td_targets)
self.actor_optimizer.zero_grad()
actor_loss.backward(retain_graph = True)
self.actor_optimizer.step()
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
self.trajectory.clear()
self.rewards.clear()
def run(self):
self.env = FireEnv(self.env_name, seed = seed, nsims = self.nsims_env, T = self.firebreaks_num)
self.features_shape = self.env.feature_shape()
self.action_shape = int(self.params["actions_shape"])
self.critic_shape = 1
self.policy = self.discrete_policy
self.actor = DeepActor(self.features_shape, self.action_shape, device).to(device)
self.critic = DeepCritic(self.features_shape, self.critic_shape, device).to(device)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr = self.params["learning_rate"])
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr = self.params["learning_rate"])
episode_rewards = list()
previous_checkpoint_mean_ep_rew = self.best_mean_reward
num_improved_episodes_before_checkpoint = 0
for episode in range(self.params["max_num_episodes"]):
obs = self.env.reset()
done = False
ep_reward = 0.0
step_num = 0
step_episode = 0
while not done:
action = self.get_action(obs)
next_obs, reward, done = self.env.step(obs, action, step_episode)
self.rewards.append(reward)
ep_reward += reward
step_num += 1
step_episode += 1
if step_num > self.params["learning_step_thresh"] or done:
self.learn(next_obs, done)
step_num = 0
if done:
episode_rewards.append(ep_reward)
if ep_reward > self.best_reward:
self.best_reward = ep_reward
if np.nanmean(episode_rewards) > previous_checkpoint_mean_ep_rew:
num_improved_episodes_before_checkpoint += 1
if num_improved_episodes_before_checkpoint >= self.params['save_freq']:
previous_checkpoint_mean_ep_rew = np.nanmean(episode_rewards)
self.best_mean_reward = np.nanmean(episode_rewards)
num_improved_episodes_before_checkpoint = 0
obs = next_obs
self.global_step_num += 1
And the CNN code is:
class DeepActor(torch.nn.Module):
def __init__(self, input_shape, output_shape, device = torch.device("cpu")):
super(DeepActor, self).__init__()
self.device = device
self.layer1 = torch.nn.Sequential(torch.nn.Conv2d(input_shape, 32, 3, stride = 1, padding = 1), torch.nn.ReLU())
self.layer2 = torch.nn.Sequential(torch.nn.Conv2d(32, 64, 3, stride = 2, padding = 1), torch.nn.ReLU())
self.layer3 = torch.nn.Sequential(torch.nn.Conv2d(64, 64, 3, stride = 1, padding = 0), torch.nn.ReLU())
self.layer4 = torch.nn.Sequential(torch.nn.Linear(64*3*3, 512), torch.nn.ReLU())
self.logits = torch.nn.Linear(512, output_shape)
def forward(self, x):
x.requires_grad_()
x = x.to(self.device)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = x.view(-1, x.shape[0]*x.shape[1]*x.shape[2])
x = self.layer4(x)
logits = self.logits(x)
return logits
class DeepCritic(torch.nn.Module):
def __init__(self, input_shape, output_shape = 1, device = torch.device("cpu")):
super(DeepCritic, self).__init__()
self.device = device
self.layer1 = torch.nn.Sequential(torch.nn.Conv2d(input_shape, 32, 3, stride = 1, padding = 1), torch.nn.ReLU())
self.layer2 = torch.nn.Sequential(torch.nn.Conv2d(32, 64, 3, stride = 2, padding = 1), torch.nn.ReLU())
self.layer3 = torch.nn.Sequential(torch.nn.Conv2d(64, 64, 3, stride = 1, padding = 0), torch.nn.ReLU())
self.layer4 = torch.nn.Sequential(torch.nn.Linear(64*3*3, 512), torch.nn.ReLU())
self.critic = torch.nn.Linear(512, output_shape)
def forward(self, x):
x.requires_grad_()
x = x.to(self.device)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = x.view(-1, x.shape[0]*x.shape[1]*x.shape[2])
x = self.layer4(x)
critic = self.critic(x)
return critic