Dear All:
My code runs perfectly on CPU but when I switched to an AWS P2 instance with GPU supported, I met below erorr:
Looks like something wrong with my backward path.
/home/ec2-user/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/torch/autograd/anomaly_mode.py:70: UserWarning: Anomaly Detection has been enabled. This mode will increase the runtime and should only be enabled for debugging. warnings.warn('Anomaly Detection has been enabled. ' Warning: Error detected in CudnnRnnBackward. Traceback of forward call that caused the error: File "issue_recommender.py", line 327, in <module> train(FLAGS) File "issue_recommender.py", line 216, in train existing_model=None) # Setting existing model to None will force training File "/home/ec2-user/Projects/CN_JIRA_Analyzer/CN_JIRA_Analyzer/recommender/dl_base_model.py", line 505, in train_load_model self._train_model(corpus_txt=corpus_txt, jira_db=jira_db) File "/home/ec2-user/Projects/CN_JIRA_Analyzer/CN_JIRA_Analyzer/recommender/dl_base_model.py", line 518, in _train_model train_loss = self._train_epoch(epoch) File "/home/ec2-user/Projects/CN_JIRA_Analyzer/CN_JIRA_Analyzer/recommender/vae_model.py", line 462, in _train_epoch recon_x, mu, logvar = self.model(indice) File "/home/ec2-user/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 550, in __call__ result = self.forward(*input, **kwargs) File "/home/ec2-user/Projects/CN_JIRA_Analyzer/CN_JIRA_Analyzer/recommender/vae_model.py", line 71, in forward recon_x = self.decode(z) File "/home/ec2-user/Projects/CN_JIRA_Analyzer/CN_JIRA_Analyzer/recommender/vae_model.py", line 246, in decode outputs, _ = self.decoder_rnn(self.input_embedding, hidden) # (B,U,H) File "/home/ec2-user/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 550, in __call__ result = self.forward(*input, **kwargs) File "/home/ec2-user/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/torch/nn/modules/rnn.py", line 727, in forward self.dropout, self.training, self.bidirectional, self.batch_first) (print_stack at /pytorch/torch/csrc/autograd/python_anomaly_mode.cpp:60) Traceback (most recent call last): File "issue_recommender.py", line 327, in <module> train(FLAGS) File "issue_recommender.py", line 216, in train existing_model=None) # Setting existing model to None will force training File "/home/ec2-user/Projects/CN_JIRA_Analyzer/CN_JIRA_Analyzer/recommender/dl_base_model.py", line 505, in train_load_model self._train_model(corpus_txt=corpus_txt, jira_db=jira_db) File "/home/ec2-user/Projects/CN_JIRA_Analyzer/CN_JIRA_Analyzer/recommender/dl_base_model.py", line 518, in _train_model train_loss = self._train_epoch(epoch) File "/home/ec2-user/Projects/CN_JIRA_Analyzer/CN_JIRA_Analyzer/recommender/vae_model.py", line 464, in _train_epoch loss.backward() File "/home/ec2-user/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/torch/tensor.py", line 198, in backward torch.autograd.backward(self, gradient, retain_graph, create_graph) File "/home/ec2-user/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/torch/autograd/__init__.py", line 100, in backward allow_unreachable=True) # allow_unreachable flag RuntimeError: The output of backward path has to be either tuple or tensor
Copied part of my code here:
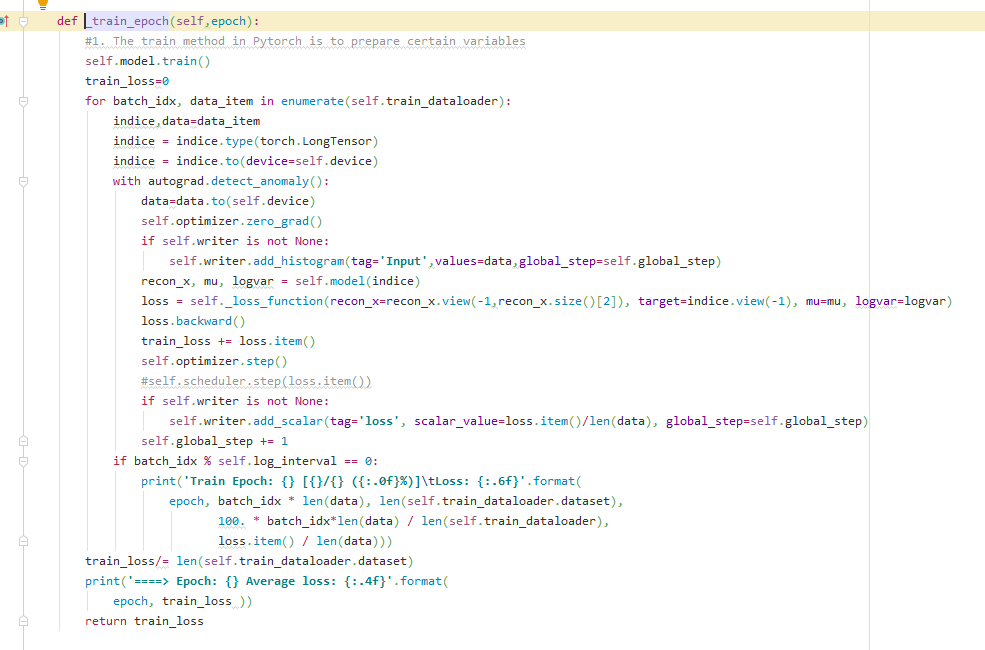
Thank you so much!