@albanD Hi, the code now works without the retain graph = True flag after I declared reg_loss variable inside the training loop. But the training time is still very high compared to the TF code. Any feedback to debug this will be very helpful! Thanks!
@albanD , Hi, I have pasted a sample code which can be easily reproduced, can you please tell me why the training time is so high from one batch to the next.
import torch
import torch.nn as nn
from torchvision.utils import save_image
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
import time
import matplotlib.pyplot as plt
import math
from scipy import stats
import scipy
import os
import datetime
from math import sqrt
from math import log
from torch import optim
from torch.autograd import Variable
from math import sqrt
from math import log
# from tensorflow import keras as K
# dim_red = 1 # perform PCA on the codes and plot the first two components
# plot_on = 1 # plot the results, otherwise only textual output is returned
# interp_on = 0 # interpolate data (needed if the input time series have different length)
# tied_weights = 0 # train an AE where the decoder weights are the econder weights transposed
# lin_dec = 1 # train an AE with linear activations in the decoder
# parse input data
parser = argparse.ArgumentParser()
parser.add_argument("--code_size", default=20, help="size of the code", type=int)
parser.add_argument("--w_reg", default=0.001, help="weight of the regularization in the loss function", type=float)
parser.add_argument("--a_reg", default=0.2, help="weight of the kernel alignment", type=float)
parser.add_argument("--num_epochs", default=5000, help="number of epochs in training", type=int)
parser.add_argument("--batch_size", default=25, help="number of samples in each batch", type=int)
parser.add_argument("--max_gradient_norm", default=1.0, help="max gradient norm for gradient clipping", type=float)
parser.add_argument("--learning_rate", default=0.001, help="Adam initial learning rate", type=float)
parser.add_argument("--hidden_size", default=30, help="size of the code", type=int)
args = parser.parse_args()
print(args)
# ================= DATASET =================
# (train_data, train_labels, train_len, _, K_tr,
# valid_data, _, valid_len, _, K_vs,
# test_data_orig, test_labels, test_len, _, K_ts) = getBlood(kernel='TCK',
# inp='zero') # data shape is [T, N, V] = [time_steps, num_elements, num_var]
train_data = np.random.rand(9000,6)
train_labels = np.ones([9000,1])
train_len = 9000
valid_data = np.random.rand(9000,6)
valid_len = 9000
test_data = np.random.rand(1500,6)
test_labels = np.ones([1500,1])
K_tr = np.random.rand(9000,9000)
K_ts = np.random.rand(1500,1500)
K_vs = np.random.rand(9000,9000)
#test_data = test_data_orig
print(
'\n**** Processing Blood data: Tr{}, Vs{}, Ts{} ****\n'.format(train_data.shape, valid_data.shape, test_data.shape))
input_length = train_data.shape[1] # same for all inputs
# ================= GRAPH =================
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
encoder_inputs = train_data
prior_k = K_tr
# ============= TENSORBOARD =============
writer = SummaryWriter()
# # ----- ENCODER -----
input_length = encoder_inputs.shape[1]
print ("INPUT ")
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.We1 = torch.nn.Parameter(torch.Tensor(input_length, args.hidden_size).uniform_(-1.0 / math.sqrt(input_length), 1.0 / math.sqrt(input_length)))
self.We2 = torch.nn.Parameter(torch.Tensor(args.hidden_size, args.code_size).uniform_(-1.0 / math.sqrt(args.hidden_size), 1.0 / math.sqrt(args.hidden_size)))
self.be1 = torch.nn.Parameter(torch.zeros([args.hidden_size]))
self.be2 = torch.nn.Parameter(torch.zeros([args.code_size]))
def encoder(self, encoder_inputs):
hidden_1 = torch.tanh(torch.matmul(encoder_inputs.float(), self.We1) + self.be1)
code = torch.tanh(torch.matmul(hidden_1, self.We2) + self.be2)
#print ("CODE ENCODER SHAPE:", code.size())
return code
def decoder(self,encoder_inputs):
code = self.encoder(encoder_inputs)
Wd1 = torch.nn.Parameter(
torch.Tensor(args.code_size, args.hidden_size).uniform_(-1.0 / math.sqrt(args.code_size),
1.0 / math.sqrt(args.code_size)))
Wd2 = torch.nn.Parameter(
torch.Tensor(args.hidden_size, input_length).uniform_(-1.0 / math.sqrt(args.hidden_size),
1.0 / math.sqrt(args.hidden_size)))
bd1 = torch.nn.Parameter(torch.zeros([args.hidden_size]))
bd2 = torch.nn.Parameter(torch.zeros([input_length]))
#if lin_dec:
#hidden_2 = torch.matmul(code, Wd1) + bd1
#else:
hidden_2 = torch.tanh(torch.matmul(code, Wd1) + bd1)
#print("hidden SHAPE:", hidden_2.size())
dec_out = torch.matmul(hidden_2, Wd2) + bd2
return dec_out
def kernel_loss(self,code, prior_K):
# kernel on codes
code_K = torch.mm(code, torch.t(code))
# ----- LOSS -----
# kernel alignment loss with normalized Frobenius norm
code_K_norm = code_K / torch.linalg.matrix_norm(code_K, ord='fro', dim=(- 2, - 1))
prior_K_norm = prior_K / torch.linalg.matrix_norm(prior_K, ord='fro', dim=(- 2, - 1))
k_loss = torch.linalg.matrix_norm(torch.sub(code_K_norm,prior_K_norm), ord='fro', dim=(- 2, - 1))
return k_loss
# Initialize model
model = Model()
# trainable parameters count
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print('Total parameters: {}'.format(total_params))
#Optimizer
optimizer = torch.optim.Adam(model.parameters(),args.learning_rate)
# ================= TRAINING =================
# initialize training variables
time_tr_start = time.time()
batch_size = args.batch_size
max_batches = train_data.shape[0] // batch_size
loss_track = []
kloss_track = []
min_vs_loss = np.infty
model_dir = "logs/dkae_models/m_0.ckpt"
logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
###############################################################################
# Training code
###############################################################################
try:
for ep in range(args.num_epochs):
# shuffle training data
idx = np.random.permutation(train_data.shape[0])
train_data_s = train_data[idx, :]
K_tr_s = K_tr[idx, :][:, idx]
for batch in range(max_batches):
fdtr = {}
fdtr["encoder_inputs"] = train_data_s[(batch) * batch_size:(batch + 1) * batch_size, :]
fdtr["prior_K"] = K_tr_s[(batch) * batch_size:(batch + 1) * batch_size,
(batch) * batch_size:(batch + 1) * batch_size]
encoder_inputs = (fdtr["encoder_inputs"].astype(float))
encoder_inputs = torch.from_numpy(encoder_inputs)
#print("TYPE ENCODER_INP IN TRAIN:", type(encoder_inputs))
prior_K = (fdtr["prior_K"].astype(float))
prior_K = torch.from_numpy(prior_K)
dec_out = model.decoder(encoder_inputs)
#print("DEC OUT TRAIN:", dec_out)
reconstruct_loss = torch.mean((dec_out - encoder_inputs) ** 2)
reconstruct_loss = reconstruct_loss.float()
#print("RECONS LOSS TRAIN:", reconstruct_loss)
enc_out = model.encoder(encoder_inputs)
k_loss = model.kernel_loss(enc_out,prior_K)
k_loss = k_loss.float()
#print ("K_LOSS TRAIN:", k_loss)
#print ("ENTRPY LOSS:", entrpy_loss)
# Regularization L2 loss
reg_loss = 0
parameters = torch.nn.utils.parameters_to_vector(model.parameters())
# print ("PARAMS:", (parameters))
for tf_var in parameters:
reg_loss += torch.mean(torch.linalg.norm(tf_var))
tot_loss = reconstruct_loss + args.w_reg * reg_loss + args.a_reg * k_loss
tot_loss = tot_loss.float()
# Backpropagation
optimizer.zero_grad()
#tot_loss.backward(retain_graph=True)
tot_loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_gradient_norm)
optimizer.step()
#tot_loss = tot_loss.detach()
loss_track.append(reconstruct_loss)
kloss_track.append(k_loss)
#check training progress on the validations set (in blood data valid=train)
if ep % 100 == 0:
print('Ep: {}'.format(ep))
# fdvs = {"encoder_inputs": valid_data,
# "prior_K": K_vs}
fdvs = {}
fdvs["encoder_inputs"] = valid_data
fdvs["prior_K"] = K_vs
#dec_out_val, lossvs, klossvs, vs_code_K, summary = sess.run(
# [dec_out, reconstruct_loss, k_loss, code_K, merged_summary], fdvs)
encoder_inp = (fdvs["encoder_inputs"].astype(float))
encoder_inp = torch.from_numpy(encoder_inp)
prior_K_vs = (fdvs["prior_K"].astype(float))
prior_K_vs = torch.from_numpy(prior_K_vs)
enc_out_vs = model.encoder(encoder_inp)
dec_out_val = model.decoder(encoder_inp)
#print ("DEC OUT VAL:", dec_out_val)
reconstruct_loss_val = torch.mean((dec_out_val - encoder_inp) ** 2)
#print("RECONS LOSS VAL:", reconstruct_loss)
k_loss_val = model.kernel_loss(enc_out_vs,prior_K_vs)
#print("K_LOSS VAL:", k_loss_val)
writer.add_scalar("reconstruct_loss", reconstruct_loss_val, ep)
writer.add_scalar("k_loss", k_loss_val, ep)
#writer.add_scalar("tot_loss", tot_loss, ep)
print('VS r_loss=%.3f, k_loss=%.3f -- TR r_loss=%.3f, k_loss=%.3f' % (
reconstruct_loss_val, k_loss_val, torch.mean(torch.stack(loss_track[-100:])), torch.mean(torch.stack(kloss_track[-100:]))))
#reconstruct_loss_val, k_loss_val, np.mean(loss_track[-100:].detach().numpy()), np.mean(kloss_track[-100:].detach().numpy())))
# Save model yielding best results on validation
if reconstruct_loss_val < min_vs_loss:
min_vs_loss = reconstruct_loss_val
torch.save(model, model_dir)
torch.save(model.state_dict(), 'logs/dkae_models/best-model-parameters.pt')
#save_path = saver.save(sess, model_name)
except KeyboardInterrupt:
print('training interrupted')
time_tr_end = time.time()
print('Tot training time: {}'.format((time_tr_end - time_tr_start) // 60))
writer.close()
The code can be runs as:
!python3 filename.py --code_size 4 --w_reg 0.001 --a_reg 0.1 --num_epochs 100 --max_gradient_norm 0.5 --learning_rate 0.001 --hidden_size 30
Thanks a lot!
Hi,
Thanks for the code sample/
A couple things:
- You can use weight_decay parameter of the optimizer instead of computing the l2 regularization term by hand.
- You should use
.item()when you save losses for logging purposes.
hi @albanD , thanks for your suggestions. This is not improving much in terms of the training time. I have copied a sample code in my original post and requested @ptrblck to have a look at it. I have another doubt on the trainable params of the model. I will open a new post for that and address you. Thank you!
I encounter this situation too.
My training code is as below:
class testNet(nn.Module):
def __init__(self):
super(testNet, self).__init__()
self.layers = nn.ModuleList([])
self.posemb = nn.Linear(2, 40)
for i in range(3):
self.layers.append(nn.Linear(2, 40))
self.bias = None
def forward(self, x, idx):
if self.bias is None:
self.bias = self.posemb(x).reshape(-1, 20, 2)
pred = self.layers[idx](x)
pred = pred.reshape(-1, 20, 2) + self.bias
return pred
if __name__ == '__main__':
net = testNet()
for b in range(3):
x = torch.rand(4, 2)
label = torch.rand(4, 20, 2)
ll = []
for i in range(3):
pred = net(x, i)
x = pred[:, 0, :]
ll.append(torch.norm(pred - label, p=-1).mean())
loss = torch.stack(ll).mean()
loss.backward()
print('batch: %d | loss: %f' % (b, loss.item()))
In the first train loop, everything is ok, but in the second loop, it will give me this error.
I have checked for a long time, and finally find out the problem is in my network.
In my forward function, I will save a intermedium variable to save extra calculation.
In the second loop, this variable should to be calculate again, but my judgement condition skip the recalculate process, so the grad graph of this intermedium variable is being cleared.
After I change
if self.bias is None:
self.bias = self.posemb(x).reshape(-1, 20, 2)
to
if idx == 0:
self.bias = self.posemb(x).reshape(-1, 20, 2)
the problem is solved!
Hi,I have encountered the same error. Here is my code
similarity_matrix = torch.Tensor(batchsize,epoch)
dist_matrix = torch.Tensor(batchsize,epoch)
for i in range(epoch):
sim_matrix = torch.matmul(history_pred[epoch], history_pred[i].T)
d_matrix = torch.matmul(true_dist, history_dist[i].T)
mask = torch.eye(sim_matrix.shape[0], dtype=torch.bool)
similarity_matrix[:, i] = sim_matrix[mask]
dist_matrix[:, i] = d_matrix[mask]
mask = (dist_matrix >= distance).bool()
numerator = torch.Tensor(batchsize,epoch)#分子
denominator = torch.Tensor(batchsize,epoch)#分母
numerator.copy_(similarity_matrix)
denominator.copy_(similarity_matrix)
numerator[mask] = 0
denominator[~mask] = 0
numerator = torch.sum(torch.exp(numerator/T),dim=1)
denominator = torch.sum(torch.exp(denominator/T),dim=1)
loss = torch.mean(numerator/denominator)
loss.backward()
true_dist is the soft_labels I created over past epochs. history_pred is the predictions of the model over past epochs.
I don’t understand how this error occurs when I only call the backward() once.
Thanks a lot.
Hi,
I have a similar problem which I still can’t solve.
I am getting the same error, I am trying to update some weight factor in the loss function, let’s say after each epoch. I am not sure how to solve this issue efficiently. I am adding a code to show the general idea shortly. Thanks you very much
lamda = 0.03
for j in range(0, (int(N_train_samples / batch_size))):loss = loss1 + lamda * loss2
loss.backward()lamda=lamda+(loss_diff * 0.01)
@albanD @ptrblck Hi, there. I’ve faced the similar problem, too. Now I have to bother you.
Here is the structure of my networks:
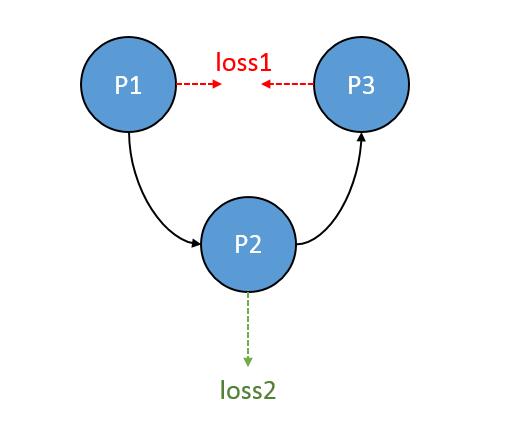
We just regard the P1,P2,P3 is some blocks stacked, a mini-CNN.
When I update loss2 with the learning rate 0.01, while loss1 just for 0.00005.
And, normally, the P1 will be influenced by both loss1 and loss2, too. Actually, I just want loss2 just for updating P2, for the high learning rate will destroy the training progress of P1 and cause non-convergence.
In my job, I use GradScaler() for backward and optimizer’s stepping. I also met the RuntimeError but I use the option retain_graph in backward() and no error occurs again.
But I am confused that, if I backward twice for two different loss.
Is these two case play the same role as below?
# -- Case A --
'''freeze opt'''
GradScaler.scale(loss2).backward(retain_graph=True)
'''defreeze opt'''
GradScaler.scale(loss1).backward()
# -- Case B --
'''freeze opt'''
loss2.backward()
'''defreeze opt'''
loss1.backward()
The frozen is requires_grad set to True or False.
Thanks!
Hi, I try this code, but find that
import torch
a = torch.rand(1, 1).requires_grad_(True) # if comment off require_grad will fail
This will be share by both iterations and will make the second backward fail !
# b = a * a # this will cause error
for i in range(10):
b = a * a # this way will get no error
d = b * b
# The first here will work but the second will not !
d.backward()
This is probably a stupid error for me, but… I’m getting this same error, and I’m baffled as to why.
AFAIK I’m only calling backward once.
Example code (a simple autoencoder):
mseloss = nn.MSELoss()
opt = optim.Adam(given_model.parameters(), lr=1e-4)
for i, batch in enumerate(train_dl):
batch = batch.to(device)
opt.zero_grad()
out = given_model(batch)
loss = mseloss(out, batch)
loss.backward()
opt.step()
given_model is very simply a few linear layers, activations and batch norms, no intermediate results. i.e. I’m familiar with getting this error with LSTMs, but that’s not what I’m doing here.
Things I’ve tried to fix this:
- Adding a
.detach()and/or.clone()tobatchpassed into themselossdoesn’t help; still get the error. - replacing
given_modelwith something very simple such asgiven_model = nn.Linear(...)(above the loop) doesn’t help; same error. - even completely removing the autoenocder aspect and just adding random target data still gives the same error, i.e.
target = torch.rand(batch.shape).to(device)
loss = F.mse_loss(out, target)
Can someone explain what’s going on and/or how to fix this? Thanks.
SOLUTION:
Seems the problem was not with the above code but rather with the dataset. The dataset was just an array of random numbers, but I’d initialized it with requires_grad=True. Removing that one kwarg fixed everything.
1 Like
I also have a similar problem. That is, I should save some parameters into a memory buffer. In fact, there is a very simple method to achieve it. You can use XXX.detach() !!!
Hi, I got the same error with pytorch. I have read this whole discussion, but I am still very confused with my own code. I have nested data, and try to train a model with these nested data by two for loops. When I run the ‘code A’, the backward error occurs at the loss.backward() part at the i=0, j=1 in code A, which means the first run of inner loop is successfully done, but the second run of inner loop encounters an error at the loss.backward(). However, when I run the ‘code B’ (the only difference from code A is I didn’t use the x_loader and y_loader.), no error happens. Can anyone help to explain why this error happens in code A but does not happen in code B? Any suggestions or hints will be appreciated!
code A
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
x = torch.range(start=0, end=1, step=0.5)
x = torch.tensor(x, requires_grad=True).float()
y = torch.range(start=0, end=1, step=0.5)
y = torch.tensor(y, requires_grad=True).float()
x_loader = DataLoader(x, shuffle=True, batch_size=2)
y_loader = DataLoader(y, shuffle=True, batch_size=2)
print(f'x is: {x}')
loss = nn.MSELoss()
for i, x_ in enumerate(x_loader):
print(f'{i}-th x is: {x_}')
for j, y_ in enumerate(y_loader):
print(f'{j}-th y is: {y_}')
l = loss(x_, y_)
print(f'l for {i, j} is: {l.item()}')
l.backward()
print(f'-----backward is completed for {i}-th x and {j}-th y')
`
here is the output and error
x is: tensor([0.0000, 0.5000, 1.0000], requires_grad=True)
0-th x is: tensor([1.0000, 0.5000], grad_fn=<StackBackward0>)
0-th y is: tensor([0.5000, 0.0000], grad_fn=<StackBackward0>)
l for (0, 0) is: 0.25
-----backward is completed for 0-th x and 0-th y
1-th y is: tensor([1.], grad_fn=<StackBackward0>)
l for (0, 1) is: 0.125
> in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
if I set loss.backward(require_grad=True) , then, it can run without error. But I am confused why do I need to go back to the same graph twice? In my design, I don’t expect backward twice on same graph. Based on my understanding, batches in the inner loop are independent to each other, and for each batch, once the loss is computed and the backward is processed, all of the immediate variables and graph of this batch should be useless so that being freed. If so then, why the inner loop can run for j==0, but not j==1? based on the output of ‘code A’, at j==1, the loss is sucessfully computed, but when the loss.backward() is trying to use the computational graph of last iteration instead of a new created one, why this happens?
But if I try the ‘code B’, then, no error reports. it runs successfully. Can you explain why this happens? Thank you in advance.
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
x = torch.range(start=0, end=1, step=0.5)
x = torch.tensor(x, requires_grad=True).float()
y = torch.range(start=0, end=1, step=0.5)
y = torch.tensor(y, requires_grad=True).float()
x_loader = DataLoader(x, shuffle=True, batch_size=2)
y_loader = DataLoader(y, shuffle=True, batch_size=2)
print(f'x is: {x}')
loss = nn.MSELoss()
for i, x_ in enumerate(x):
print(f'{i}-th x is: {x_}')
for j, y_ in enumerate(y):
print(f'{j}-th y is: {y_}')
l = loss(x_, y_)
print(f'l for {i, j} is: {l.item()}')
l.backward()
print(f'-----backward is completed for {i}-th x and {j}-th y')
and the output is:
x is: tensor([0.0000, 0.5000, 1.0000], requires_grad=True)
0-th x is: 0.0
0-th y is: 0.0
l for (0, 0) is: 0.0
-----backward is completed for 0-th x and 0-th y
1-th y is: 0.5
l for (0, 1) is: 0.25
-----backward is completed for 0-th x and 1-th y
2-th y is: 1.0
l for (0, 2) is: 1.0
-----backward is completed for 0-th x and 2-th y
1-th x is: 0.5
0-th y is: 0.0
l for (1, 0) is: 0.25
-----backward is completed for 1-th x and 0-th y
1-th y is: 0.5
l for (1, 1) is: 0.0
-----backward is completed for 1-th x and 1-th y
2-th y is: 1.0
l for (1, 2) is: 0.25
-----backward is completed for 1-th x and 2-th y
2-th x is: 1.0
0-th y is: 0.0
l for (2, 0) is: 1.0
-----backward is completed for 2-th x and 0-th y
1-th y is: 0.5
l for (2, 1) is: 0.25
-----backward is completed for 2-th x and 1-th y
2-th y is: 1.0
l for (2, 2) is: 0.0
-----backward is completed for 2-th x and 2-th y
I’m facing similar problem and each time I call the loss.backward() inside the training loop or outside it results to the same error, below is model, customGNN and embedding generation.
My use case is link prediction using min-max with negative sampling.
The error occurs each I run the training loop below. I have included other parts of my code too like my model, GNN layer and embedding generation just to add context in case something is wrong with how my model is structured. However, I believe the problem is with the loop, I tried required_grad=True but the error still persists.
from torch.nn.functional import cosine_similarity
class EmbeddingGenerationModel(nn.Module):
def init(self, user_in_feats, product_in_feats, image_in_feats, hidden_feats):
super(EmbeddingGenerationModel, self).init()
self.layers = CustomGNNLayer(user_in_feats, product_in_feats, image_in_feats, hidden_feats)
self.user_final_layer = nn.Linear(hidden_feats, hidden_feats)
self.product_final_layer = nn.Linear(hidden_feats, hidden_feats)
self.image_final_layer = nn.Linear(hidden_feats, hidden_feats)
def forward(self, g, h):
h = self.layers(g, h)
user_out = self.user_final_layer(h['user'])
product_out = self.product_final_layer(h['product'])
image_out = self.image_final_layer(h['image'])
return user_out, product_out, image_out
class LinkPredictionModel(nn.Module):
def init(self, user_in_feats, product_in_feats, image_in_feats, hidden_feats):
super().init()
self.embedding_model = EmbeddingGenerationModel(
user_in_feats, product_in_feats, image_in_feats, hidden_feats)
self.fc = nn.Linear(2, 1) # 2 similarity scores: user-image and user-product
def forward(self, g, user_feats, product_feats, image_feats, edges):
# Generate embeddings
user_embeddings, product_embeddings, image_embeddings = self.embedding_model(g, {'user': user_feats, 'product': product_feats, 'image': image_feats})
# Select relevant embeddings based on edges
user_embed_selected = user_embeddings[edges[0]]
product_embed_selected = product_embeddings[edges[1]]
image_embed_selected = image_embeddings[edges[0]] # Assuming image embeddings correspond to users
# Check if selected embeddings match edge sizes
assert user_embed_selected.size(0) == edges[0].size(0), "Mismatch between user embeddings and edges"
assert product_embed_selected.size(0) == edges[1].size(0), "Mismatch between product embeddings and edges"
assert image_embed_selected.size(0) == edges[0].size(0), "Mismatch between image embeddings and edges"
# Calculate user-image similarity (cosine similarity)
user_image_similarity = cosine_similarity(user_embed_selected, image_embed_selected, dim=1).unsqueeze(1)
# Calculate user-product similarity (cosine similarity)
user_product_similarity = cosine_similarity(user_embed_selected, product_embed_selected, dim=1).unsqueeze(1)
# Concatenate user_image_similarity and user_product_similarity
similarities = torch.cat([user_image_similarity, user_product_similarity], dim=1)
# Prediction using similarities
interaction_probabilities = torch.sigmoid(self.fc(similarities))
return interaction_probabilities
#GNN layer
cass CustomGNNLayer(nn.Module):
def init(self, user_in_feats, product_in_feats, image_in_feats, hidden_feats):
super(CustomGNNLayer, self).init()
# Define weight matrices for each node type
self.weight_user = nn.Linear(user_in_feats, hidden_feats)
self.weight_product = nn.Linear(product_in_feats, hidden_feats)
self.weight_image = nn.Linear(image_in_feats, hidden_feats)
self.weight_self = nn.Linear(hidden_feats, hidden_feats)
def forward(self, g, h):
with g.local_scope():
# Extract features from the dictionaries
user_feats = h['user']['features']
product_feats = h['product']['features']
image_feats = h['image']['features']
# Assign features to each node type
g.nodes['user'].data['h'] = self.weight_user(user_feats)
g.nodes['product'].data['h'] = self.weight_product(product_feats)
g.nodes['image'].data['h'] = self.weight_image(image_feats)
# Message function to fetch incoming messages
def message_func(edges):
return {'msg': edges.src['h']}
# Reduce function to aggregate messages
def reduce_func(nodes):
neigh_msg = nodes.mailbox['msg'].mean(dim=1)
self_msg = self.weight_self(nodes.data['h'])
return {'h': torch.relu(neigh_msg + self_msg)}
# Update all node types
g.update_all(message_func, reduce_func, etype=('user', 'rates', 'product'))
g.update_all(message_func, reduce_func, etype=('user', 'has', 'image'))
# Extract updated features for each node type
user_feats_out = g.nodes['user'].data['h']
product_feats_out = g.nodes['product'].data['h']
image_feats_out = g.nodes['image'].data['h']
return {'user': user_feats_out, 'product': product_feats_out, 'image': image_feats_out}
#training loop.
for epoch in range(num_epochs):
epoch_loss = 0.0 # Accumulate loss for the epoch
# DataLoader for positive and negative edge samples
dataloader = DataLoader(train_edges, batch_size=64, shuffle=True)
for batch in dataloader:
pos_u, pos_v = batch[:, 0], batch[:, 1]
neg_u = pos_u # Negative samples have the same users as positive samples
neg_v = torch.randint(0, train_num_products, (len(pos_v),)) # Random negative products
# Forward pass for positive edges
pos_scores = link_prediction_model(train_g, train_user_feats, train_product_feats, train_image_feats, (pos_u, pos_v))
pos_scores = pos_scores.squeeze(-1) # Remove the extra dimension
# Forward pass for negative edges
neg_scores = link_prediction_model(train_g, train_user_feats, train_product_feats, train_image_feats, (neg_u, neg_v))
neg_scores = neg_scores.squeeze(-1) # Remove the extra dimension
# Max-margin loss
loss = torch.sum(torch.clamp(1 - pos_scores + neg_scores, min=0))
# Backward pass
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item() # Accumulate (only once!)
print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {epoch_loss}")
print(“Training completed.”)
Hi,
I am facing the same issue here, but can’t manage to figure out why is the reason in my case. I’ll be very thankful if you could please help me with this:
class GCNWithEdgeF(torch.nn.Module):
def __init__(self, in_channles, out_channels, edge_emb_dim, num_edge_types):
super(GCNWithEdgeF, self).__init__()
self.conv1 = GCNConv(in_channels, out_channels)
self.edge_type_emb = torch.nn.Embedding(num_edge_types, edge_emb_dim)
self.edge_transform = torch.nn.Linear(out_channels + edge_emb_dim, out_channels)
self.link_prediction = torch.nn.Linear(out_channels * 2, 1)
def forward(self, node_f, edge_i, edge_w, edge_t):
node_f = self.conv1(node_f, edge_i, edge_w)
edge_emb = self.edge_type_emb(edge_t)
src, tgt = edge_i
node_fsrc = node_f[src]
node_ftgt = node_f[tgt]
comb_fsrc = torch.cat([node_fsrc, edge_emb], dim=-1)
comb_ftgt = torch.cat([node_ftgt, edge_emb], dim=-1)
transformed_fsrc = self.edge_transform(comb_fsrc)
transformed_ftgt = self.edge_transform(comb_ftgt)
out = torch.zeros_like(node_f, dtype=torch.float)
out.index_add_(0, src, transformed_fsrc)
out.index_add_(0, tgt, transformed_ftgt)
return F.relu(out)
def predict_linkweight(self, node_f, edge_i):
src, tgt = edge_i
node_fsrc = node_f[src]
node_ftgt = node_f[tgt]
comb_f = torch.cat([node_fsrc, node_ftgt], dim=-1)
pre_w = self.link_prediction(comb_f)
return pre_w.squeeze()
in_channels = node_features.shape[1]
out_channels = 120
edge_embbeding_dim = 20
num_edge_types = 4
# original_node_features = node_features
model = GCNWithEdgeF(in_channels, out_channels, edge_embbeding_dim, num_edge_types)
optimizer = optim.Adam(model.parameters(), lr = 0.01)
loss_function = torch.nn.MSELoss()
num_edges = edge_index.size(1)
num_train = int(0.9 * num_edges)
num_test = num_edges - num_train
train_indices = torch.randperm(num_edges)[:num_train]
test_indices = torch.randperm(num_edges)[num_train:num_train + num_test]
train_edge_index = edge_index[:, train_indices]
test_edge_index = edge_index[:, test_indices]
train_edge_weight = edge_weight[train_indices]
test_edge_weight = edge_weight[test_indices]
train_edge_type = edge_type[train_indices]
test_edge_type = edge_type[test_indices]
num_epochs = 100
for epoch in range(num_epochs):
model.train()
node_features_out = model(node_features, train_edge_index, train_edge_weight, train_edge_type)
predicted_weights = model.predict_linkweight(node_features_out, train_edge_index)
loss = loss_function(predicted_weights, train_edge_weight)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}')
model.eval()
with torch.no_grad():
test_node_features = model(node_features, test_edge_index, test_edge_weight, test_edge_type)
predicted_test_weights = model.predict_linkweight(test_node_features, test_edge_index)
test_loss = loss_function(predicted_test_weights, test_edge_weight)
print(f'Test Loss: {test_loss.item()}')
Thanks a lot!
I am also facing same issue , here is my code , can someone please help me? thanks you!
def train_epoch(model, train_loader, optimizer, loss_fn, device, scaler):
model.train()
total_loss = 0
correct = 0
total = 0
for batch_idx, (batch_embedding, batch_target) in enumerate(tqdm(train_loader, desc="Training")):
# Move data to device
batch_embedding = batch_embedding.to(device)
batch_target = batch_target.to(device)
# Zero gradients before forward pass
optimizer.zero_grad()
# Enable autocasting for mixed precision
with torch.amp.autocast(device_type='cuda'):
outputs = model(batch_embedding)
loss = loss_fn(outputs, batch_target)
# Debugging: Print loss tensor ID
print(f"Batch {batch_idx}: Loss tensor ID: {id(loss)}")
#scaler.scale(loss).backward(retain_graph=True)
scaler.scale(loss).backward()
# Update weights and scaler
scaler.step(optimizer)
scaler.update()
# Accumulate metrics
total_loss += loss.item()
predicted = (outputs > 0).float()
total += batch_target.size(0)
correct += (predicted == batch_target).sum().item()
#correct += (predicted == batch_target.squeeze(-1)).sum().item()
avg_loss = total_loss / len(train_loader)
accuracy = correct / total
lr_scheduler.step()
return avg_loss, accuracy