Hi, I have a problem when training pytorch programs, it is a simple face classification task trained with cross entropy loss. The images of the same person is in the same folder. There are 320000 images in 7000 folders.
I run the same python script one the same machine(ubuntu-16.04, one GTX-1080ti, pytorch-1.8, python-3.6, cuda-10.2)
The following are the screen shot of different runs:
Fast run: (about 5 iters/s)

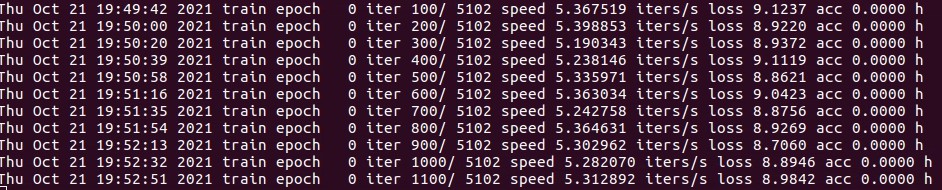
Slow run:(about 1 iters/s)

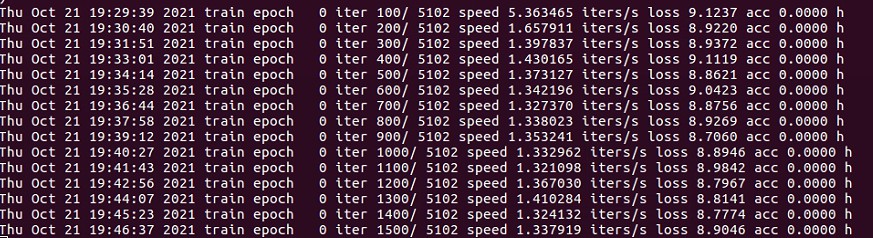
I assume this is the IO problem of loading data, since D means uninterruptible sleep (usually IO)
Here is the main code of me loading the data
train_transforms = T.Compose([
T.Grayscale(),
T.RandomCrop(args.input_shape[1:]),
T.RandomHorizontalFlip(),
T.ToTensor(),
T.Normalize(mean=[0.5], std=[0.5]),
])
train_dataset = torchvision.datasets.ImageFolder(data_dir, transform = train_transforms)
# traing_size means percentage of whole training dataset
if args.train_size != 1:
train_idx, val_idx= train_test_split(np.arange(len(train_dataset.targets)),
train_size=args.train_size,
shuffle=True,
random_state = args.random_state,
stratify=train_dataset.targets) # data re-shuffled at every epoch 按比例分配
train_dataset = torch.utils.data.Subset(train_dataset, train_idx)
trainloader = data.DataLoader(train_dataset,
batch_size=args.train_batch_size,
shuffle=True,
num_workers=args.num_workers)
else:
trainloader = data.DataLoader(train_dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.num_workers)
I am confused with why this happens, since I am not running other programs or applications of the same time.
I have tried using data_prefetcher from an example from apex official website, but it did not solve the problem.
Can anyone give me some insights how to solve the problem, thanks a lot