I’m trying to work out whether the torch.utils.data.WeightedRandomSampler class will still cover all available data inputs provided a long enough training period when choosing sampling with replacement.
Given that WeightedRandomSampler requires shuffle=False in the DataLoader, does that mean that WeightedRandomSampler will observe the entire sampling array (which is paired to the data thanks to DataLoader), select the same high ranked objects, replace them, and then select them again… every epoch?
Or is there some inbuilt way that ensures it will still manage to cover all objects given enough time?
The reason I ask is because, when using sampling with replacement, the number of objects evaluated in one epoch remains the same length as when not…when intuitively you would expect the number of objects selected to increase.
Sorry for my poor understanding but if they are drawn from a multinomial does that mean that there is a random chance a sample will be drawn from a low probability region (like MCMC) or does the method stick to orderly sampling from highest to lowest probability?
Also is there any point in sampling without replacement if it will sample all of the input objects anyway, despite the probabilities, just in a selected order?
I could try num_samples …the only problem then is the overhead time in calculating the number of extra object samples to allow for.
There is no “random chance” but a well defined probability to draw a specific class. For example if you have a multinomial distribution with three classes A, B, and C with probabilities P(A) = 90 %, P(B) = 9 %, P(C) = 1 %, then sampling from that distribution gives instances of class A with 90 % probability, instances of class B with 9 % proboability and instances of class C with 1 % probability.
And no. Random sampling does not define any kind of order.
So I understand that there is a well defined percentage chance of sampling a class…but given that you are sampling without replacement, and the number of samples chosen in an epoch remains unchanged, then presumably sampling without replacement is pointless as all objects will be sampled anyway. Unless however, you specifically reduce the number of samples in an epoch in which case there must be some random selection of say B1 over B2 (2 samples from class B), for example, if the sample limit is being approached?
Yes, you are right. If you specify replacement=False and keep the size as the whole dataset length, only your batches at the beginning will be balanced using the weights until all minority classes are “used”. You could try to decrease the length so that most of your batches will be balanced.
If one was to give all the training classes equal probabilities for WeightedRandomSampler, does this mean that the function will draw samples for each batch randomly from the entire dataset. So in epoch 2 the objects in batch 1 will not be the same as in batch 1 from epoch 3 for example?
Does Pytorch have a method of sampling from a dataset (who’s objects are given weights based on their frequency of appearance in the dataset) such that for every draw you have a roughly balanced sample set for regression?
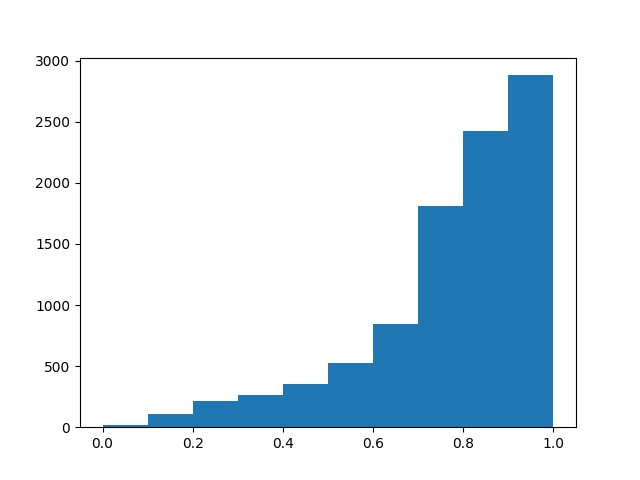
For example: If you had a dataset who’s number of objects per label looks as follows:
(X-axis = label, Y-axis = number in the dataset)
Using WeightedRandomSampler with a controlled num_samples where the weights are given as 1-label, to my understanding this will not balance a sample’s number of objects with certain labels as they will be drawn from a distribution which favours the lower value labelled objects than the high value labelled objects.
So the distribution of labels in your sample will look like the plot above but mirrored about the y-axis.
Is there a way to sample such that from these labels you can draw a more balanced set given that your num_samples is smaller than the total number of objects in the dataset?
Please note that the values on the X-axis above are continuous as this is a regression problem and I have only binned the data to present my point.
I think your binning approach could work to balance each batch for your regression problem.
Could you explain your concerns a bit more as I’m not understanding them clearly.
The weight distribution will favor the lower bins, but since they are rare, you’ll end up with a (hopefully) balanced batch.
Okay I’ll try to expand on my explanation a little more:
I’m conducting a regression task where I’m trying to return a value (k) between 0-1.
There are more k=1 values than k=0 as shown above in an exponential fashion.
I have weighted each image by 1-k in the hopes of seeing more of the rare images which have low k.
I’m concerned that: say you have 6 million images and you restrict num_samples to 25 thousand for example, that you will not get balanced batches where you see equal number of low k images as high k images. (This is what i meant by a balanced sample set, apologies for the lingo)…simply because the multinomial sampler might not explore the high k images enough as they’re down-weighted so much.
If balancing through the multinomial sampler works to hopefully balance the batches then that’s good news, but wouldn’t there be an optimal num_samples in that case to make this happen? For example if you sample 2 weighted images from 6 million… then realistically your low weighted images would never get picked but choosing 5.9 million for a batch would cause the weighting to become obsolete as the sampler has to boost the excess space with more low weighted images to the point at which they unbalance the batch again.
I should note that I am using sampling with replacement here.
I think it will still work. If I’m not misunderstanding your concern, that should be exactly how the WeightedRandomSampler works.
I’ve adapted an old example using two highly imbalanced classes:
numDataPoints = 1000
data_dim = 5
bs = 100
# Create dummy data with class imbalance 99 to 1
data = torch.randn(numDataPoints, data_dim)
target = torch.cat((torch.zeros(int(numDataPoints * 0.99), dtype=torch.long),
torch.ones(int(numDataPoints * 0.01), dtype=torch.long)))
print('target train 0/1: {}/{}'.format(
(target == 0).sum(), (target == 1).sum()))
class_sample_count = torch.tensor(
[(target == t).sum() for t in torch.unique(target, sorted=True)])
weight = 1. / class_sample_count.float()
samples_weight = torch.tensor([weight[t] for t in target])
sampler = WeightedRandomSampler(samples_weight, int(len(samples_weight)))
train_dataset = torch.utils.data.TensorDataset(data, target)
train_loader = DataLoader(
train_dataset, batch_size=bs, num_workers=1, sampler=sampler)
for i, (x, y) in enumerate(train_loader):
print("batch index {}, 0/1: {}/{}".format(
i, (y == 0).sum(), (y == 1).sum()))
Even though the classes are distributed in 99 to 1, each each will contain approx. a balanced set of classes.
Let me know, if you could adapt this code to your use case.
Hmm that does appear to be working fine doesn’t it. I assume that this means that the weighted sampler attempts to balance the dataset by taking repeated samples of the underrepresented class in each batch? …The reason I say that is because only 10 of the dataset are class 1 and therefore in a batch of 100, to get ~50 of each class you must resample the underrepresented set.
Well, that’s exactly what replacement=True does. The sampler oversamples the minority classes with replacement, such that the samples will be repeated.
It works just fine in a lot of use cases. If you don’t want to repeat samples you can specify replacement=False and adapt the num_samples to get fewer balanced batches.
No no that’s what i want to happen really because then I don’t need to find an optimal num_samples. The idea was to make sure that the network doesn’t default to an output of 0.7 all the time based on it being a balance point in the returned loss because of the distribution of number of samples, so using replacement=True seems to fix that.
That being said, I’ve altered your code to make it a regression problem with more values >0.9 than <0.9 and it seems to sample in an unbalanced way now:
numDataPoints = 1000
data_dim = 5
bs = 100
# Create dummy data with class imbalance 99 to 1
data = torch.randn(numDataPoints, data_dim)
target = torch.cat( (torch.FloatTensor(int(numDataPoints*0.01)).uniform_(0, 0.9), torch.FloatTensor(int(numDataPoints*0.99)).uniform_(0.9, 1)) )
print('target train <0.9/>0.9: {}/{}'.format(
(target < 0.9).sum(), (target > 0.9).sum()))
samples_weight = 1-target
sampler = WeightedRandomSampler(samples_weight, int(len(samples_weight)))
train_dataset = torch.utils.data.TensorDataset(data, target)
train_loader = DataLoader(
train_dataset, batch_size=bs, num_workers=1, sampler=sampler)
for i, (x, y) in enumerate(train_loader):
print("batch index {}, <0.9/>0.9: {}/{}".format(
i, (y < 0.9).sum(), (y > 0.9).sum()))
OUT:
target train <0.9/>0.9: 10/990
batch index 0, <0.9/>0.9: 7/93
batch index 1, <0.9/>0.9: 7/93
batch index 2, <0.9/>0.9: 11/89
batch index 3, <0.9/>0.9: 12/88
batch index 4, <0.9/>0.9: 9/91
batch index 5, <0.9/>0.9: 10/90
batch index 6, <0.9/>0.9: 12/88
batch index 7, <0.9/>0.9: 9/91
batch index 8, <0.9/>0.9: 12/88
batch index 9, <0.9/>0.9: 13/87
Your weights are not a good representation of the class imbalance if you use (target-1).
I think a binning approach would work to count the class occurrences.
In your example this would fix the issue:
class_sample_count = torch.tensor([(target <= 0.9).sum(),
(target > 0.9).sum()])
weight = 1. / class_sample_count.float()
samples_weight = torch.tensor([weight[int(t>0.9)] for t in target])