That’s a good point, you would need to find a way or relating the target label to it’s frequency in the dataset based on a known distribution of object counts.
I’ll try your method above and see how it goes!
Thanks again! 
That’s a good point, you would need to find a way or relating the target label to it’s frequency in the dataset based on a known distribution of object counts.
I’ll try your method above and see how it goes!
Thanks again!
Even if the distribution is unknown, we could use binning with a specified number of bins to make the labels categorical. This would allow us to treat the regression samples as classes and count their occurrences.
Basically in the same way you’ve already binned your targets. 
Or one could try to work with kernel density estimation. But that is computationally way more expensive and more work.
I’ve tried to implement this by first binning the data by rounding them to their closest 0.5 and then defining each of those 0.5 intervals as a class from 0-10.
I’m finding that the sampler is still preferring the rare events such as the extremely low and extremely high labelled data. Perhaps because there’s only one or two images for these ‘classes’.
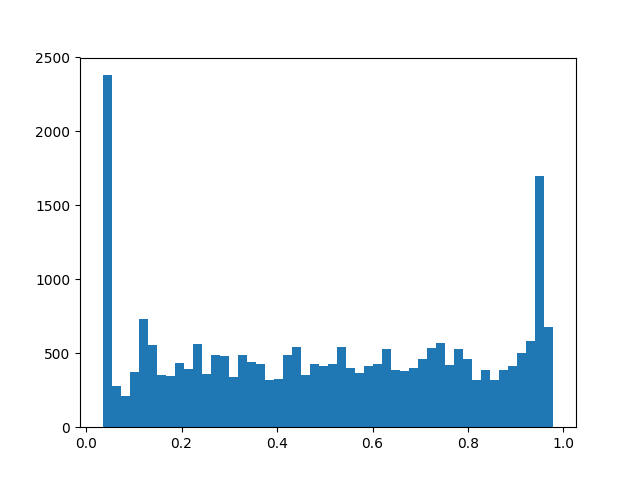
I’ve observed this happening for every batch…so I’m not sure why this isn’t working at the moment as it seems to be fine in test cases such as the code snippet below:
numDataPoints = 1000
data_dim = 5
bs = 100
# Create dummy data with class imbalance 99 to 1
data = torch.randn(numDataPoints, data_dim)
target = np.hstack([np.random.uniform(0.055,0.5,999), np.random.uniform(0,0.04,1)])
def binner(array):
array = np.round(np.round(array*200)/20)
return array.astype(int)
target = binner(target)
target = torch.LongTensor(target)
class_sample_count = torch.tensor(
[(target == t).sum() for t in torch.unique(target, sorted=True)])
weight = 1. / class_sample_count.float()
samples_weight = torch.tensor([weight[t] for t in target])
sampler = WeightedRandomSampler(samples_weight, int(len(samples_weight)),replacement=True)
train_dataset = torch.utils.data.TensorDataset(data, target)
train_loader = DataLoader(
train_dataset, batch_size=bs, shuffle=False, num_workers=1, sampler=sampler)
for i, (x, y) in enumerate(train_loader):
print("batch index {}, 0/1/2/3/4/5...: {}/{}/{}/{}/{}/{}".format(
i, (y == 0).sum(), (y == 1).sum(), (y == 2).sum(), (y == 3).sum(), (y == 4).sum(), (y == 5).sum(), (y == 6).sum()))
OUT:
batch index 0, 0/1/2/3/4/5...: 13/16/22/16/17/16
batch index 1, 0/1/2/3/4/5...: 10/15/24/14/15/22
batch index 2, 0/1/2/3/4/5...: 16/17/22/12/17/16
batch index 3, 0/1/2/3/4/5...: 12/14/14/21/14/25
batch index 4, 0/1/2/3/4/5...: 13/19/12/21/20/15
batch index 5, 0/1/2/3/4/5...: 13/25/18/17/13/14
batch index 6, 0/1/2/3/4/5...: 16/22/15/12/18/17
batch index 7, 0/1/2/3/4/5...: 18/18/13/22/17/12
batch index 8, 0/1/2/3/4/5...: 15/18/13/15/21/18
batch index 9, 0/1/2/3/4/5...: 16/17/16/15/23/13
That’s still strange, as it seems to work in the example.
Could you post the class frequencies?
Are you observing this distribution in every batch?
Hi, I am kind of trying to work with imbalanced dataset. Would you please explain, how exactly use the num_samples to perform undersampling? (Getting fewer batches corresponding to the minority class?)
I’m not sure, if you are referring to the num_samples from WeightedRandomSampler, but if so, this argument only specifies the number of returned samples while the weights define the sampling weights and thus the balancing.
My previous post has a working example to show how to use it.
Thanks for your response. I really appreciate it!
Actually, from what I have understood about undersampling, “Only the number of samples from majority classes are reduced to maintain the ratio with the minority class in class imbalance”. But, using replacement=False also returns the same number of batches as it does with replacement=True.
So, I would be glad if you could explain how exactly undersampling and oversampling is done in pytorch.
I am kind of expecting few batches in undersampling .
Thanks for your clear reply. In the current “replacement” deployment scenario, it is probable to sample a majority class instance several times in one epoch. It is proposed to accept replacement with respect to each class label or with respect to each sample. for example the replacement can be like [True,False] in the binary class problem or like replacement=[False,False,False,…,True,False,…True] in the instance-wise state that each element of replacement say about corresponding sample index.