I am working on semantic Segmentation on Pascal VOC 2012 dataset and my model is not working.
Please help.
My model is like.
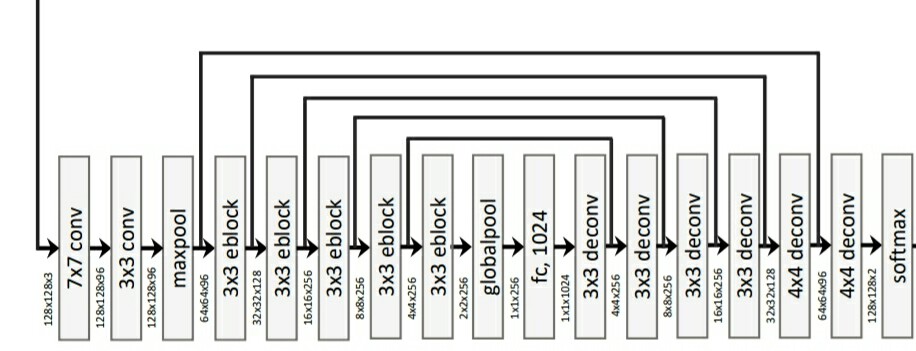
(I took the final decoder output dimension as
1 as binary so 1 dimension labelmap)
class Net(nn.Module):
def __init__(self):
print('\nGruInitializing')
super(GRUNet,self).__init__()
self.is_x_tensor4 = False
self.batch_size, self.img_w, self.img_h=10,128,128
self.input_shape = (self.batch_size, 3, self.img_w, self.img_h)
#number of filters for each convolution layer in the encoder
self.n_convfilter = [96, 128, 256, 256, 256, 256]
#the dimension of the fully connected layer
self.n_fc_filters = [1024]
#number of filters for each 2d convolution layer in the decoder
self.n_deconvfilter = [256, 256, 256, 128, 96, 1]
self.encoder=encoder(self.input_shape,self.n_convfilter,\
self.n_fc_filters)
#HERE THE PROBELM IS idx1,idx2,idx3
self.decoder=decoder(self.n_deconvfilter,n_class=1)
def forward(self,x):
output,c1,c2,c3,c4,c5= self.encoder(x)
ok=self.decoder(output,c1,c2,c3,c4,c5)
return ok
I have used the encoder-decoder model and my code is as follows–
class encoder(nn.Module):
def __init__(self,input_shape,n_convfilter,\
n_fc_filters):
print("\ninitalizing \"encoder\"")
super(encoder,self).__init__()
#conv1
self.conv1a = Conv2d(input_shape[1], n_convfilter[0], 7, padding=3,stride=1)#
self.conv1b = Conv2d(n_convfilter[0], n_convfilter[0], 3, padding=1,stride=1)
#conv2
self.conv2a = Conv2d(n_convfilter[0], n_convfilter[1], 3, padding=1,stride=1)
self.conv2b = Conv2d(n_convfilter[1], n_convfilter[1], 3, padding=1,stride=1)
self.conv2c = Conv2d(n_convfilter[0], n_convfilter[1], 1)
#conv3
self.conv3a = Conv2d(n_convfilter[1], n_convfilter[2], 3, padding=1,stride=1)
self.conv3b = Conv2d(n_convfilter[2], n_convfilter[2], 3, padding=1,stride=1)
self.conv3c = Conv2d(n_convfilter[1], n_convfilter[2], 1)
#conv4
self.conv4a = Conv2d(n_convfilter[2], n_convfilter[3], 3, padding=1,stride=1)
self.conv4b = Conv2d(n_convfilter[3], n_convfilter[3], 3, padding=1,stride=1)
#conv5
self.conv5a = Conv2d(n_convfilter[3], n_convfilter[4], 3, padding=1,stride=1)
self.conv5b = Conv2d(n_convfilter[4], n_convfilter[4], 3, padding=1,stride=1)
self.conv5c = Conv2d(n_convfilter[3], n_convfilter[4], 1)
#conv6
self.conv6a = Conv2d(n_convfilter[4], n_convfilter[5], 3, padding=1,stride=1)
self.conv6b = Conv2d(n_convfilter[5], n_convfilter[5], 3, padding=1,stride=1)
#conv6
self.conv6a = Conv2d(n_convfilter[4], n_convfilter[5], 3, padding=1,stride=1)
self.conv6b = Conv2d(n_convfilter[5], n_convfilter[5], 3, padding=1,stride=1)
#conv7
self.conv7a = Conv2d(n_convfilter[5], n_convfilter[5], 3, padding=1,stride=1)
self.conv7b = Conv2d(n_convfilter[5], n_convfilter[5], 3, padding=1,stride=1)
#self.conv7c = Conv2d(n_convfilter[3], n_convfilter[4], 1)
########################### n_convfilter[5]=256###################all
#pooling layer
self.pool1 = MaxPool2d(kernel_size= 2,stride=2)#,return_indices=True)
self.pool2 = MaxPool2d(kernel_size=1,stride=2)#,return_indices=True)
self.gpool=nn.AvgPool2d(kernel_size=2)
#nonlinearities of the network
self.leaky_relu = LeakyReLU(negative_slope= 0.01)
self.sigmoid = Sigmoid()
self.tanh = Tanh()
self.conv8a = Conv2d(n_convfilter[5], 1024, 1, padding=0,stride=1)
#self.fc7 = Linear(1*1*256, 1024)
def forward(self, x):
idx1,idx2,idx3=0,0,0
#x is the input and the size of x is (batch_size, channels, heights, widths).
conv1a = self.conv1a(x)
rect1a = self.leaky_relu(conv1a)
conv1b = self.conv1b(rect1a)
rect1 = self.leaky_relu(conv1b)
pool1,idx1 = self.pool1(rect1),0
conv2a = self.conv2a(pool1)
rect2a = self.leaky_relu(conv2a)
conv2b = self.conv2b(rect2a)
rect2 = self.leaky_relu(conv2b)
conv2c = self.conv2c(pool1)
res2 = conv2c + rect2
pool2,idx2 = self.pool2(res2),0
conv3a = self.conv3a(pool2)
rect3a = self.leaky_relu(conv3a)
conv3b = self.conv3b(rect3a)
rect3 = self.leaky_relu(conv3b)
conv3c = self.conv3c(pool2)
res3 = conv3c + rect3
pool3,idx3 = self.pool2(res3),0
conv4a = self.conv4a(pool3)
rect4a = self.leaky_relu(conv4a)
conv4b = self.conv4b(rect4a)
rect4 = self.leaky_relu(conv4b)
pool4,idx4 = self.pool2(rect4),0
conv5a = self.conv5a(pool4)
rect5a = self.leaky_relu(conv5a)
conv5b = self.conv5b(rect5a)
rect5 = self.leaky_relu(conv5b)
conv5c = self.conv5c(pool4)
res5 = conv5c + rect5
pool5,idx5 = self.pool2(res5),0
conv6a = self.conv6a(pool5)
rect6a = self.leaky_relu(conv6a)
conv6b = self.conv6b(rect6a)
rect6 = self.leaky_relu(conv6b)
res6 = pool5 + rect6
pool6,idx6 = self.pool2(res6),0
conv7a = self.conv6a(pool6)
rect7a = self.leaky_relu(conv7a)
conv7b = self.conv6b(rect7a)
rect7 = self.leaky_relu(conv7b)
res7 = pool6 + rect7
pool7,idx6 = self.pool2(res7),0
pool8=self.gpool(pool7)
#pool9 = pool8.view(pool8.size(0), -1)
#print(pool8.shape)
fc7 = self.conv8a(pool8)
rect7 = self.leaky_relu(fc7)
#print(rect7.shape)
return rect7,pool1,pool2,pool3,pool4,pool5
Decoder–
class decoder(nn.Module):
def __init__(self, n_deconvfilter,n_class):
self.n_class=n_class
print("\ninitializing \"decoder\"")
super(decoder, self).__init__()
#2d conv10
self.conv10 = ConvTranspose2d(1024, n_deconvfilter[0], 3,stride=2, output_padding=1)#n_deconvfilter[0](we have to replace it with 256)
#self.conv7b = ConvTranspose2d(n_deconvfilter[1], 256, 3, padding=1)#n_deconvfilter[0](we have to replace it with 256)
#2d conv11
self.conv11 = ConvTranspose2d(n_deconvfilter[0], n_deconvfilter[1], 3, padding=1,stride=2,output_padding=1)#((4-1)*2+3-2*1)
#self.conv8b = ConvTranspose2d(n_deconvfilter[2], n_deconvfilter[2], 3, padding=1)
#2d conv12
self.conv12 = ConvTranspose2d(n_deconvfilter[1], n_deconvfilter[2], 3, padding=1,stride=2,output_padding=1)
#self.conv9b = ConvTranspose2d(n_deconvfilter[3], n_deconvfilter[3], 3, padding=1)
#self.conv9c = ConvTranspose2d(n_deconvfilter[2], n_deconvfilter[3], 1)
#2d conv13
self.conv13 = ConvTranspose2d(n_deconvfilter[2], n_deconvfilter[3], 3, padding=1,stride=2,output_padding=1)
#self.conv10b = ConvTranspose2d(n_deconvfilter[4], n_deconvfilter[4], 3, padding=1)
#self.conv10c = ConvTranspose2d(n_deconvfilter[4], n_deconvfilter[4], 3, padding=1)
#2d conv14
self.conv14 = ConvTranspose2d(n_deconvfilter[3], n_deconvfilter[4], 4, padding=1,stride=2)
self.conv15 = ConvTranspose2d(n_deconvfilter[4], n_deconvfilter[5], 4, padding=1,stride=2)
self.leaky_relu = LeakyReLU(negative_slope= 0.01)
self.softmax=nn.Softmax2d()
def forward(self, rect7,c1,c2,c3,c4,c5):
#rect7=rect7.view([rect7.shape[0],1024,1 , 1])#idx3
#unpool7 = self.unpool2d(rect7)###HERE FACING PROBLEM
#unpool7=unpool7.cuda()
print(rect7.shape)
conv10 = self.conv10(rect7)
rect10 = self.leaky_relu(conv10)
rect10=rect10+c5
print(rect10.shape)
#resp=res7[0:,0:,:5,:5]
#unpool8 = self.unpool2d(res7)#Here is the probelm
conv11 = self.conv11(rect10)
rect11 = self.leaky_relu(conv11)
rect11=rect11+c4
conv12 = self.conv12(rect11)
rect12 = self.leaky_relu(conv12)
rect12=rect12+c3
conv13 = self.conv13(rect12)
rect13 = self.leaky_relu(conv13)
rect13=rect13+c2
conv14 = self.conv14(rect13)
rect14 = self.leaky_relu(conv14)
rect14=rect14+c1
conv15=self.conv15(rect14)
#rect10=rect10+c5
h=conv15
h=self.softmax(conv15)
#print(h.shape)
soft=h.view(h.shape[0]*self.n_class,h.shape[2]*h.shape[3]*h.shape[1])
return soft
My images are of size(10 as batch size)
[10,3,128,128]
training–
n_epochs = 5
#model=model.cuda()
valid_loss_min = np.Inf # track change in validation loss
model.train()
train_loss = 0.0
valid_loss=0.0
import datetime
for epoch in range(1, n_epochs+1):
print("ALL ABOUT LOSS(training)--------",(train_loss/len(images)),"----------/n")
print("ALL ABOUT LOSS(valid)--------",(valid_loss/len(valid_target)),"----------/n")
train_loss = 0.0
valid_loss=0.0
model.train()
for i in range(len(train_img)):
data=train_img[i]#.cuda()
tar=train_target[i]#.cuda()
#tar=tar.long()
print(tar.size())
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output=model(data)
print(output.size())
loss = criterion(output, tar)
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item()*data.size(0)
if(i==1):
print("about me 1 ",train_loss)
#print("time", datetime.datetime.now().time())
if(i==43):
print("\nabout me 43 ",train_loss)
print("time", datetime.datetime.now().time())
"""
if(i==200):
print("\nabout me 200 ",train_loss)
print("time", datetime.datetime.now().time())
"""
model.eval()
for i in range(len(valid_img)):
data=valid_img[i]#.cuda()
tar=valid_target[i]#.cuda()
loss = torch.mean(criterion(model(data), tar))
valid_loss += loss.item()*data.size(0)
And i am using Optimizers and loss as-
import torch.optim as optim
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-5,eps=1e-08)
I think the problem is in the Loss function
My images are Binary in nature–

So i create label map as-
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 1., 1., 1.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 0., 0., 0.]])
I guess the probelm is with the last layer.
Using softmax 2d all my output converts to 1(each cell).
I am not getting where i am lacking.
Please Help.