Sorry for picking up on old thread but I found your statement interesting.
Without any in-depth knowledge of how GPUs work, I assume that this means: The data transfer to the GPU can happen independent of the computation i.e. tensor transformations which is why non_blocking=True is a good option.
If, however, we wanted to do something that changes the data itself, say normalize it along some dimension, then its not really going to help because that updated data will have to be readied before output=model(data) part.
If I understand your description correctly, your general understanding should be correct.
Asynchronous operation would allow you to execute other operations in the meantime while the async operation is being executed in the background. If you have a data dependency between both tasks, the execution of the data-dependent operation would need to wait.
@ptrblck how does one wait after issuing the non_blocking=True? I want to perform a bunch of computations while data is being transferred, but then wait for the transfer to complete afterward.
Hello, I want to test whether using to with non_blocking=True actually achieves computation-communication overlap. Therefore, I set up a tensor transfer with to and a multiplication calculation between two tensors:
import torch
# Define the matrix size and operations
matrix_size = 10000
a = torch.randn((matrix_size, matrix_size), device='cuda:0')
b = torch.randn((matrix_size, matrix_size), device='cuda:0')
# Create timing events
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
c = torch.randn((5, matrix_size, matrix_size), device='cpu').pin_memory()
# Test with non_blocking=False
start_event.record()
c.to('cuda:0', non_blocking=False) # Synchronous
_ = torch.matmul(a, b) # Perform a large matrix operation
end_event.record()
torch.cuda.synchronize()
time_non_blocking_false = start_event.elapsed_time(end_event)
print(f"Time with non_blocking=False: {time_non_blocking_false:.3f} ms")
c = torch.randn((5, matrix_size, matrix_size), device='cpu').pin_memory()
# Test with non_blocking=True
start_event.record()
c.to('cuda:0', non_blocking=True) # Asynchronous
_ = torch.matmul(a, b) # Perform a large matrix operation
end_event.record()
torch.cuda.synchronize()
time_non_blocking_true = start_event.elapsed_time(end_event)
print(f"Time with non_blocking=True: {time_non_blocking_true:.3f} ms")
But the output is:
Time with non_blocking=False: 187.034 ms
Time with non_blocking=True: 186.822 ms
It seems that this didn’t reduce the time. What’s going on?
It’s important to understand the async behavior w.r.t. the host and device.
A proper profile helps visualizing your code (I’ve added warmup iterations).
In the first part of the code the copies are synchronous, so the CPU waits until the operation finishes before launching the matmul kernel.
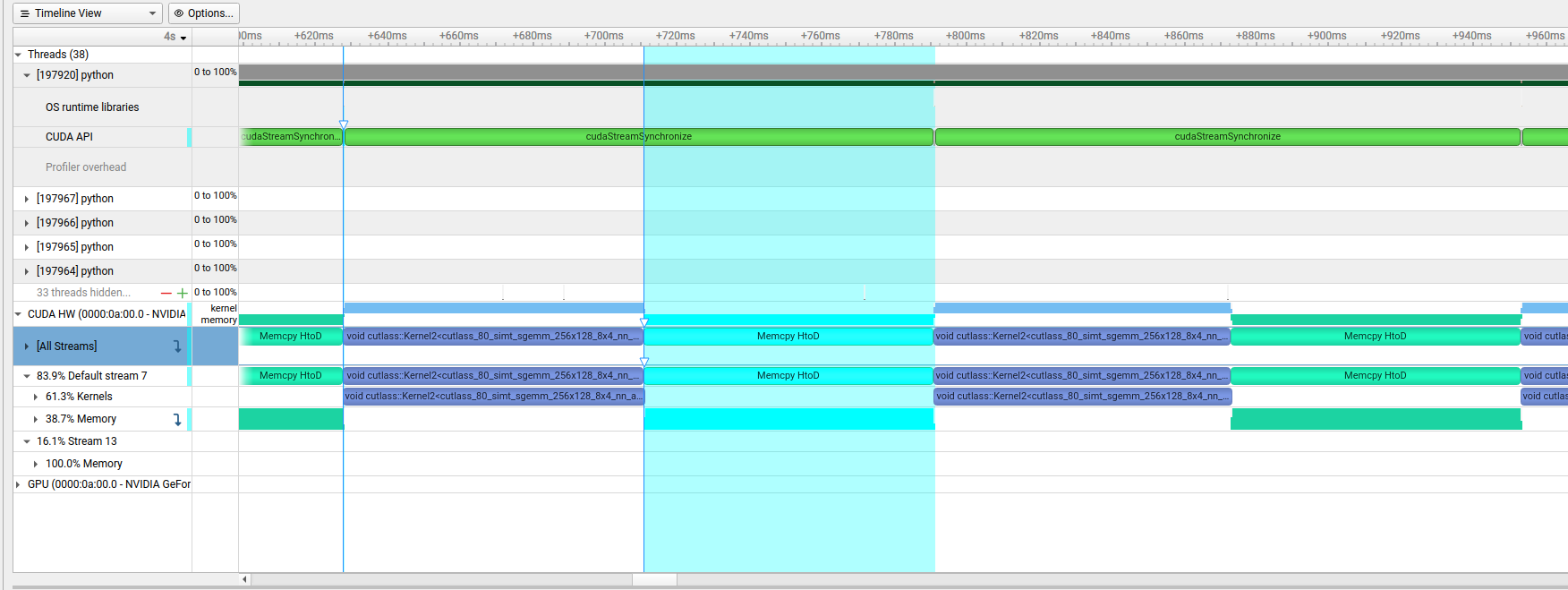
In this section of the Nsight Systems profile you can see the alternating kernel execution (bottom row). The top row shows the launch of the copy kernel followed by a sync, and the matmul kernel launch (hard to see as the sync takes a lot more time than the launches):
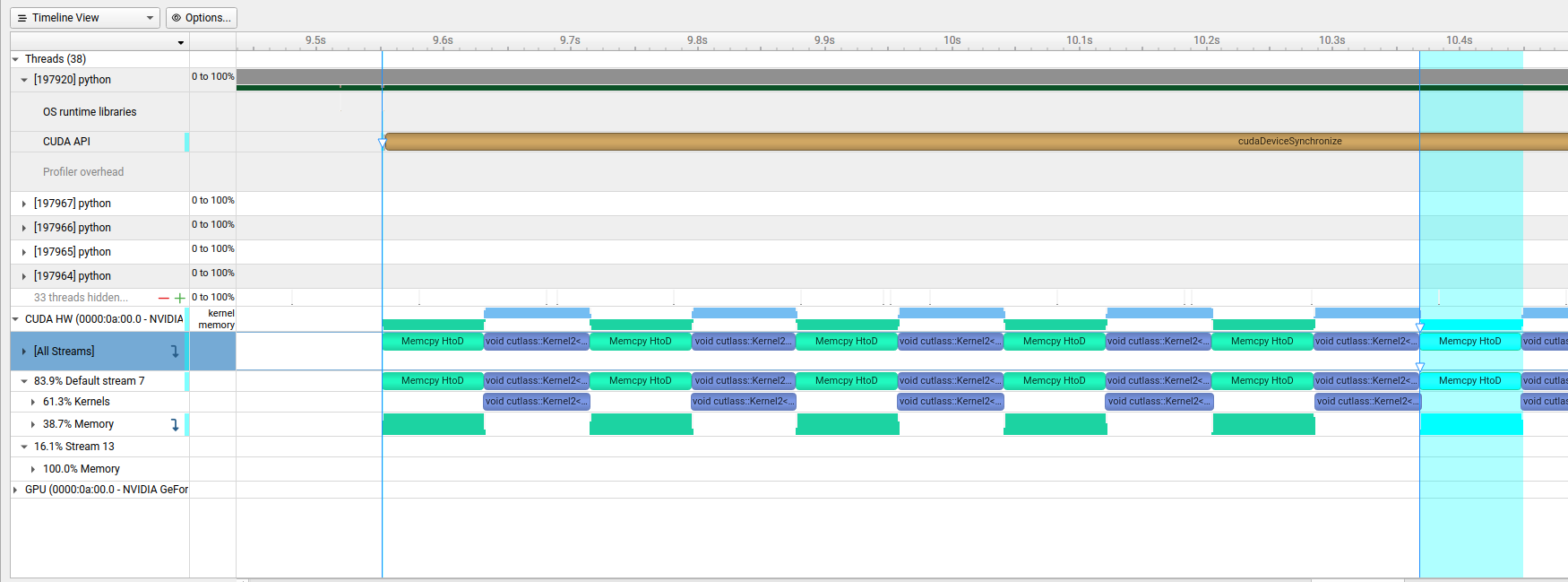
The second code snippet uses async kernel launches (by using pinned memory and non_blocking=True) but the kernel execution on the GPU will still be alternating, since launches are stream ordered and since you are using the default stream only:
You can see here that all kernel launches are packed together on the top row on the left followed by a single sync.
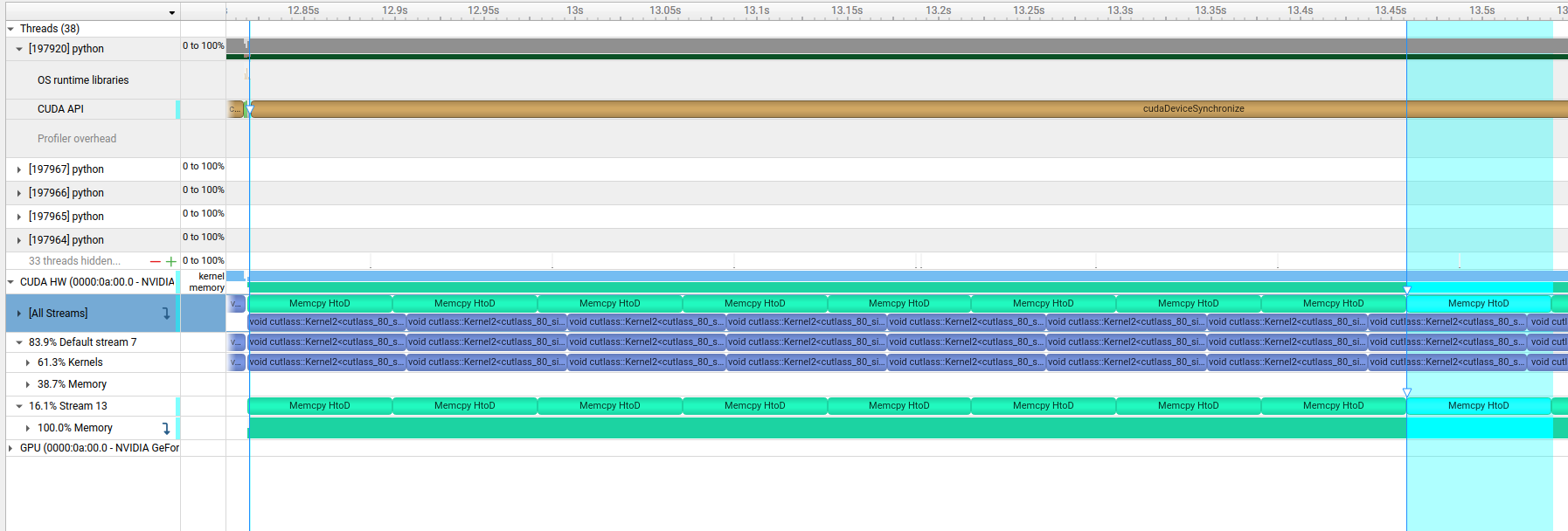
Now using custom CUDA streams allows us to also overlap the device copies and execution:
s = torch.cuda.Stream()
# warmup
for _ in range(10):
with torch.cuda.stream(s):
c.to('cuda:0', non_blocking=True) # Asynchronous
_ = torch.matmul(a, b) # Perform a large matrix operation
# Test with non_blocking=True
start_event.record()
for _ in range(10):
with torch.cuda.stream(s):
c.to('cuda:0', non_blocking=True) # Asynchronous
_ = torch.matmul(a, b) # Perform a large matrix operation
end_event.record()
torch.cuda.synchronize()
time_non_blocking_true = start_event.elapsed_time(end_event)
print(f"Time with non_blocking=True: {time_non_blocking_true:.3f} ms")
Since you are using a custom stream now, you would need to take care of the needed synchronization before consuming this data. Take a look at the CUDA streams docs for more information.