I’m studiying pytorch coming from a background with tensorflow. I’m trying to replicate a simple convnet, that I’ve developed with success in tensorflow, to classify cat vs dogs images.
In pytorch I see some strange behaviors:
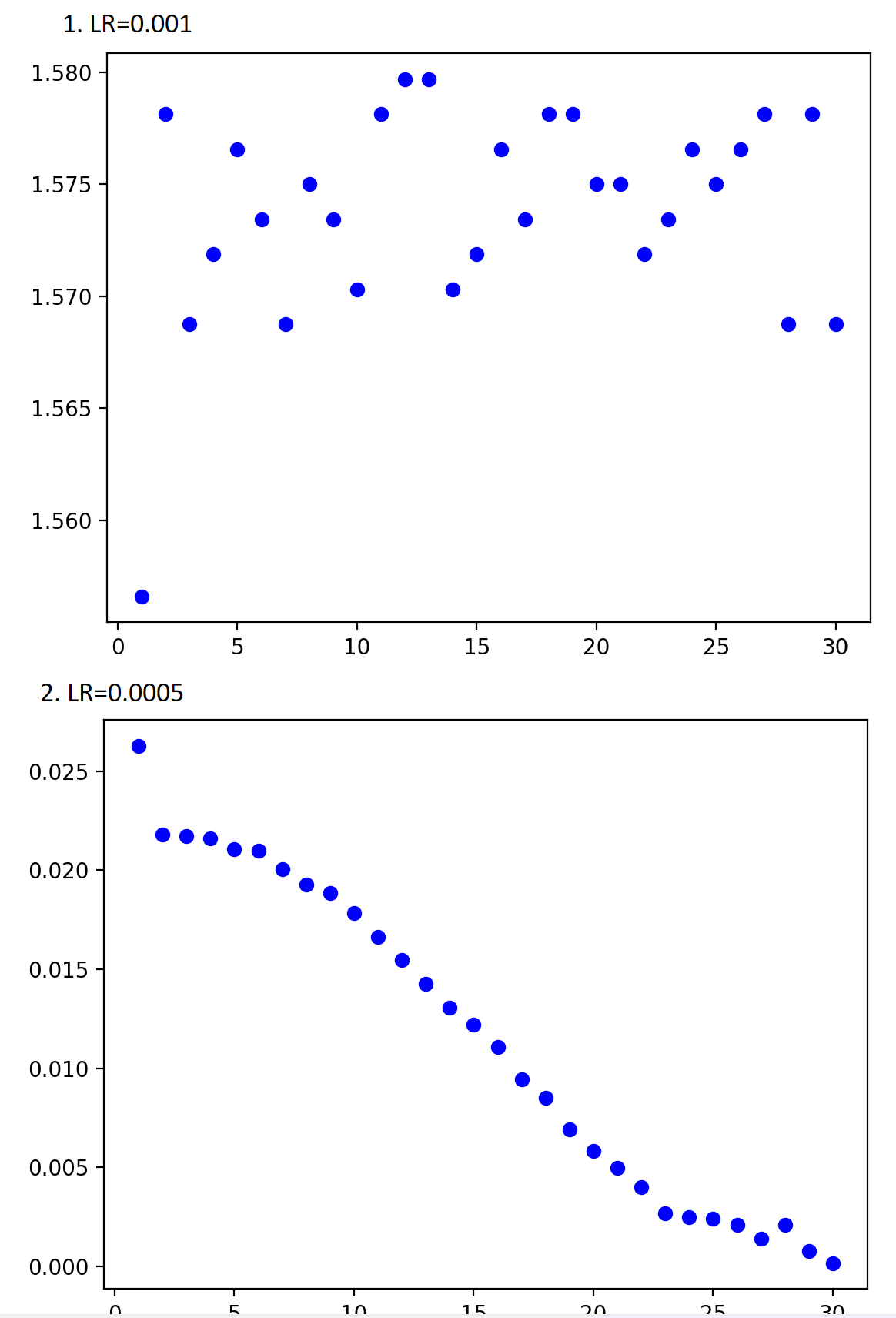
- Using a Learning Rate of 0.001 make the CNet predicting only 0 after the first batch (might be exploding gradients?)
- Using a Learning Rate of 0.0005 gives a smooth learning curve and the CNet converge
Can anyone help me to understand what I’m doing wrong? that the code:
import pathlib
import torch
import torch.nn.functional as F
import torchvision
from torch.utils.data.dataloader import DataLoader
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class CNet(torch.nn.Module):
def __init__(self):
super(CNet, self).__init__() #input is 180x180 image
self.conv1 = torch.nn.Conv2d(3, 32, 3) # out -> 178x178x32
self.conv2 = torch.nn.Conv2d(32, 64, 3)
self.conv3 = torch.nn.Conv2d(64, 128, 3)
self.conv4 = torch.nn.Conv2d(128, 256, 3)
self.conv5 = torch.nn.Conv2d(256, 256, 3)
self.flatten = torch.nn.Flatten()
#self.fc = torch.nn.LazyLinear(1)
self.fc = torch.nn.Linear(7*7*256, 1)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv3(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv4(x)), (2, 2))
x = F.relu(self.conv5(x))
x = self.flatten(x)
o = torch.sigmoid(self.fc(x))
return o
def train(model : CNet, train_data : DataLoader, criterion, optimizer : torch.optim.Optimizer, epochs = 10, validation_data : DataLoader = None):
losses = []
for epoch in range(epochs):
epoch_loss = 0.0
running_loss = 0.0
for i, data in enumerate(train_data, 0):
imgs, labels = data
imgs, labels = imgs.to(device), labels.to(device, dtype=torch.float)
labels = labels.unsqueeze(-1)
# run
output = net(imgs)
# zero out accumulated grads
loss = criterion(output, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
epoch_loss += loss.item()
#if i % 50 == 49:
# print(f'[{epoch+1}, {i:5d}] loss: {running_loss / 50.0:.3f}')
# running_loss = 0.0
losses.append(epoch_loss / len(train_data.dataset))
print(f'[{epoch+1}, {epochs:5d}] loss: {losses[-1]:.3f}')
return losses
if __name__=="__main__":
transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize((180, 180)),
torchvision.transforms.ToTensor(),
])
dataset_dir = pathlib.Path("E:\Datasets\\torch\Cat_Dog\cats_vs_dogs_small")
train_data = torchvision.datasets.ImageFolder(dataset_dir / "train", transform=transforms)
validation_data = torchvision.datasets.ImageFolder(dataset_dir / "validation", transform=transforms)
test_data = torchvision.datasets.ImageFolder(dataset_dir / "test", transform=transforms)
train_data_loader = DataLoader(train_data, batch_size=32, shuffle=True, num_workers=2, persistent_workers=True, pin_memory=True)
validation_data_loader = DataLoader(validation_data, batch_size=32, num_workers=2, shuffle=True, pin_memory=True)
test_data_loader = DataLoader(test_data, batch_size=32, shuffle=True, pin_memory=True, num_workers=2)
import matplotlib.pyplot as plt
#plt.figure()
#for i in range(1, 10):
# plt.subplot(3, 3, i)
# plt.axis('off')
# rand_idx = np.random.random_integers(0, len(train_data))
# plt.imshow(np.moveaxis(test_data[rand_idx][0].numpy(), 0, 2))
#plt.show()
net = CNet()
net = net.to(device)
criterion = torch.nn.BCELoss()
optimizer = torch.optim.RMSprop(net.parameters(), 0.001)
net.train()
# TODO save best model
losses = train(net, train_data_loader, criterion, optimizer, epochs=30)
epochs = range(1, len(losses) + 1)
plt.plot(epochs, losses, 'bo', label='Training Loss')
plt.show()
print('Training Finished')
correct_count, all_count = 0, 0
for images,labels in test_data_loader:
images,labels = images.to(device), labels.to(device, dtype=torch.float)
with torch.no_grad():
ps = net(images)
pred_label = (ps > 0.5).to(torch.float)
true_label = labels.unsqueeze(1)
correct_count += (pred_label == true_label).sum().item()
all_count += len(labels)
print("Number Of Images Tested =", all_count)
print("\nModel Accuracy =", (correct_count/all_count))
and here some screenshot of the loss for each point:
-
LR=0.001 (not convering on pytorch, converging on tensorflow)
-
LR=0.0005 (converging in 30 epochs) [I know that the validation loss is not 0, accuracy is ~70% but is expected]
What could cause this issue? I’ve been able to train a similar net on tensorflow without problems using lr=0.001. Any tips? What am I missing?