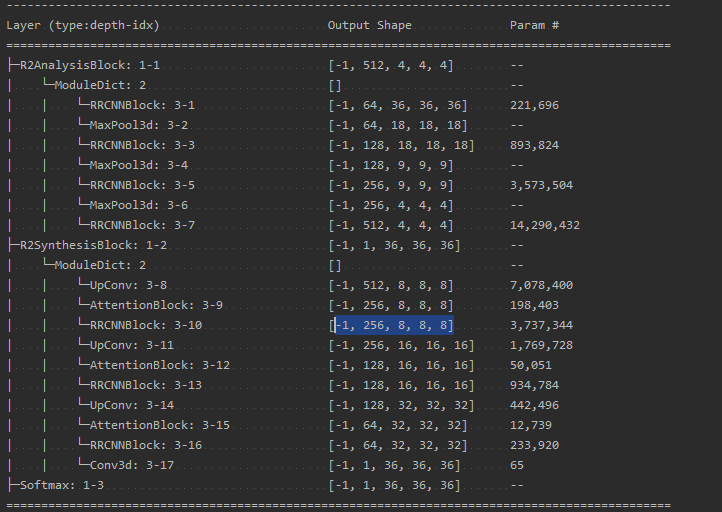
I am trying to run a model but it the predicted output is different than the actual input. I think it has some padding or kernel size problem. The code is attached . Please take a look.
I want to use 3d patch size with binary classification (num_classes=2, in_channels=1)
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
from torchsummary import summary
def init_weights(net, init_type=‘normal’, gain=0.02):
def init_func(m):
classname = m.class.name
if hasattr(m, ‘weight’) and (classname.find(‘Conv’) != -1 or classname.find(‘Linear’) != -1):
if init_type == ‘normal’:
init.normal_(m.weight.data, 0.0, gain)
elif init_type == ‘xavier’:
init.xavier_normal_(m.weight.data, gain=gain)
elif init_type == ‘kaiming’:
init.kaiming_normal_(m.weight.data, a=0, mode=‘fan_in’)
elif init_type == ‘orthogonal’:
init.orthogonal_(m.weight.data, gain=gain)
else:
raise NotImplementedError(‘initialization method [%s] is not implemented’ % init_type)
if hasattr(m, ‘bias’) and m.bias is not None:
init.constant_(m.bias.data, 0.0)
elif classname.find(‘BatchNorm3d’) != -1:
init.normal_(m.weight.data, 1.0, gain)
init.constant_(m.bias.data, 0.0)
print('initialize network with %s' % init_type)
net.apply(init_func)
class Conv(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super().init()
self.conv3d = nn.Conv3d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding)
self.batch_norm = nn.BatchNorm3d(num_features=out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv3d(x)
x = self.batch_norm(x)
x = self.relu(x)
return x
class AnalysisBlock(nn.Module):
def init(self, in_channels, model_depth=4, pooling=2):
super().init()
init_out_channels = 32
num_conv_layers = 2
self.module_dict = nn.ModuleDict()
for depth in range(model_depth):
out_channels = (2 ** depth) * init_out_channels
for layer in range(num_conv_layers):
conv_layer = Conv(in_channels, out_channels)
self.module_dict["conv_{}_{}".format(depth, layer)] = conv_layer
in_channels, out_channels = out_channels, out_channels * 2
if depth != model_depth - 1:
max_pool = nn.MaxPool3d(kernel_size=pooling, stride=2, padding=0)
self.module_dict["max_pool_{}".format(depth)] = max_pool
def forward(self, x):
# TODO: Maybe change to tensor instead of list
synthesis_features = []
for key, layer in self.module_dict.items():
x = layer(x).contiguous()
if key.startswith("conv") and key.endswith("1"):
synthesis_features.append(x)
return x, synthesis_features
class UpConv(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=2, padding=1, output_padding=1):
super().init()
# TODO Up Convolution or Conv Transpose?
self.up_conv = nn.ConvTranspose3d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, output_padding=output_padding)
def forward(self, x):
return self.up_conv(x)
class SynthesisBlock(nn.Module):
def init(self, out_channels, model_depth=4):
super().init()
init_out_channels = 128
num_conv_layers = 2
self.module_dict = nn.ModuleDict()
for depth in range(model_depth - 2, -1, -1):
channels = (2 ** depth) * init_out_channels
up_conv = UpConv(in_channels=channels, out_channels=channels)
self.module_dict["deconv_{}".format(depth)] = up_conv
for layer in range(num_conv_layers):
in_channels, feat_channels = channels // 2, channels // 2
if layer == 0:
in_channels = in_channels + channels
conv_layer = Conv(in_channels=in_channels, out_channels=feat_channels)
self.module_dict["conv_{}_{}".format(depth, layer)] = conv_layer
if depth == 0:
# TODO Figure out kernel size + padding + stride for final
# 1 x 1 x 1 conv
final_conv = nn.Conv3d(in_channels=feat_channels, out_channels=out_channels, kernel_size=1, padding=2)
self.module_dict["final_conv"] = final_conv
def forward(self, x, high_res_features):
for key, layer in self.module_dict.items():
if key.startswith("deconv"):
x = layer(x)
# Enforce same size
features = high_res_features[int(key[-1])][:, :, 0:x.size()[2], 0:x.size()[3],
0:x.size()[4]].contiguous()
x = torch.cat((features, x), dim=1).contiguous()
else:
x = layer(x)
return x
class RecurrentBlock(nn.Module):
def init(self, out_channels, t=2):
super().init()
self.t = t
self.conv = nn.Sequential(
nn.Conv3d(out_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm3d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
for i in range(self.t):
if i == 0:
x1 = self.conv(x)
x1 = self.conv(x + x1)
return x1
class RRCNNBlock(nn.Module):
def init(self, in_channels, out_channels, t=2):
super().init()
self.Conv_1x1 = nn.Conv3d(in_channels, out_channels, kernel_size=1, stride=1)
self.RCNN = nn.Sequential(
RecurrentBlock(out_channels, t=t),
RecurrentBlock(out_channels, t=t)
)
def forward(self, x):
x = self.Conv_1x1(x)
x1 = self.RCNN(x)
return x + x1
class AttentionBlock(nn.Module):
def init(self, f_g, f_l, f_int):
super().init()
self.w_g = nn.Sequential(
nn.Conv3d(f_g, f_int, kernel_size=1, stride=1, padding=0),
nn.BatchNorm3d(f_int)
)
self.w_x = nn.Sequential(
nn.Conv3d(f_l, f_int, kernel_size=1, stride=1, padding=0),
nn.BatchNorm3d(f_int)
)
self.psi = nn.Sequential(
nn.Conv3d(f_int, 1, kernel_size=1, stride=1, padding=0),
nn.BatchNorm3d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
g1 = self.w_g(g)
x1 = self.w_x(x)
psi = self.relu(g1 + x1)
psi = self.psi(psi)
return x * psi
class R2AnalysisBlock(nn.Module):
def init(self, in_channels, model_depth=4, pooling=2):
super().init()
init_out_channels = 64
num_conv_layers = 1
self.module_dict = nn.ModuleDict()
for depth in range(model_depth):
out_channels = (2 ** depth) * init_out_channels
for layer in range(num_conv_layers):
r2_conv_layer = RRCNNBlock(in_channels, out_channels)
self.module_dict["r2_conv_{}".format(depth)] = r2_conv_layer
in_channels, out_channels = out_channels, out_channels * 2
if depth != model_depth - 1:
max_pool = nn.MaxPool3d(kernel_size=pooling, stride=2, padding=0)
self.module_dict["max_pool_{}".format(depth)] = max_pool
def forward(self, x):
# TODO: Maybe change to tensor instead of list
synthesis_features = []
for key, layer in self.module_dict.items():
x = layer(x).contiguous()
if key.startswith("r2_conv"):
synthesis_features.append(x)
return x, synthesis_features
class R2SynthesisBlock(nn.Module):
def init(self, out_channels, model_depth=4):
super().init()
init_out_channels = 128
num_conv_layers = 1
self.module_dict = nn.ModuleDict()
for depth in range(model_depth - 2, -1, -1):
channels = (2 ** depth) * init_out_channels
up_conv = UpConv(in_channels=channels, out_channels=channels)
self.module_dict["deconv_{}".format(depth)] = up_conv
att_gate = AttentionBlock(channels, channels // 2, channels // 2)
self.module_dict["att_gate_{}".format(depth)] = att_gate
for layer in range(num_conv_layers):
in_channels, feat_channels = channels // 2, channels // 2
if layer == 0:
in_channels = in_channels + channels
r2_conv_layer = RRCNNBlock(in_channels=in_channels, out_channels=feat_channels)
self.module_dict["r2_conv_{}".format(depth)] = r2_conv_layer
if depth == 0:
# TODO Figure out kernel size + padding + stride for final
# 1 x 1 x 1 conv
final_conv = nn.Conv3d(in_channels=feat_channels, out_channels=out_channels, kernel_size=1, padding=2)
self.module_dict["final_conv"] = final_conv
def forward(self, x, high_res_features):
for key, layer in self.module_dict.items():
if key.startswith("deconv"):
g = layer(x)
# Enforce same size
elif key.startswith("att_gate"):
features = high_res_features[int(key[-1])][:, :, 0:g.size()[2], 0:g.size()[3],
0:g.size()[4]].contiguous()
features = layer(g=g, x=features)
x = torch.cat((features, g), dim=1).contiguous()
else:
x = layer(x)
return x
class UNet(nn.Module):
def init(self, in_channels, out_channels, model_depth=5, pooling=2, final_activation=“softmax”):
super().init()
self.encoder = AnalysisBlock(in_channels=in_channels, model_depth=model_depth, pooling=pooling)
self.encoder.cuda()
self.decoder = SynthesisBlock(out_channels=out_channels, model_depth=model_depth)
self.decoder.cuda()
if final_activation == "softmax":
self.final = nn.Softmax(dim=1)
self.final.cuda()
elif final_activation == "sigmoid":
self.final = nn.Sigmoid()
self.final.cuda()
else:
self.final = None
# TODO other final layers
def forward(self, x):
x, features = self.encoder(x)
x = self.decoder(x, features)
if self.final:
x = self.final(x)
return x
class R2AttUNet(nn.Module):
def init(self, in_channels, out_channels, model_depth=4, pooling=2, final_activation=“softmax”, t=2):
super().init()
super().__init__()
self.encoder = R2AnalysisBlock(in_channels=in_channels, model_depth=model_depth, pooling=pooling)
self.encoder.cuda()
self.decoder = R2SynthesisBlock(out_channels=out_channels, model_depth=model_depth)
self.decoder.cuda()
if final_activation == "softmax":
self.final = nn.Softmax(dim=1)
self.final.cuda()
elif final_activation == "sigmoid":
self.final = nn.Sigmoid()
self.final.cuda()
else:
self.final = None
# TODO other final layers
def forward(self, x):
x, features = self.encoder(x)
x = self.decoder(x, features)
if self.final:
x = self.final(x)
return x
if name == “main”:
inputs = torch.randn(1, 1, 32, 32, 32)
print("The shape of inputs: ", inputs.shape)
model = R2AttUNet(in_channels=1, out_channels=2 )
inputs = inputs.cuda()
model.cuda()
x = model(inputs)
print(x.shape)
summary(model, x)
for → inputs = torch.randn(1, 1, 32, 32, 32)