I’m trying to implement GradCAM for inception_v3, but after my modifications, it’s taking a long time, much more than what I get without the changes. Am I doing something wrong?
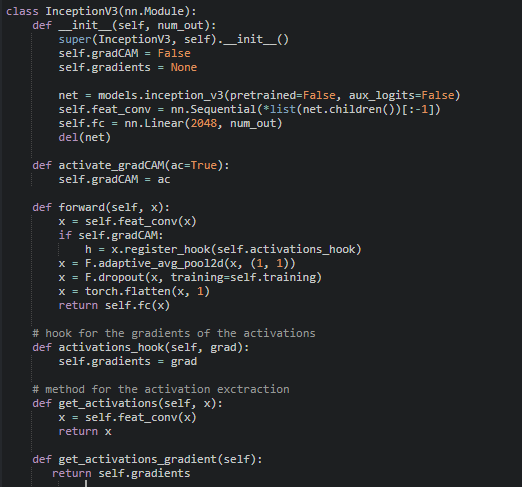
I’m trying to implement GradCAM for inception_v3, but after my modifications, it’s taking a long time, much more than what I get without the changes. Am I doing something wrong?
Your hooks might create sync points similar to this topic, which will slow down your code.
Did you check the GPU utilization before and after using the hooks?
I’m not sure if the problem is the hook, for during training I set “gradCAM = False”. Also, I’m using Google Colab, so I don’t think I can check GPU usage. I did the following modification and it didn’t change the performance, which is much slower than if I just use the model from torchvision:
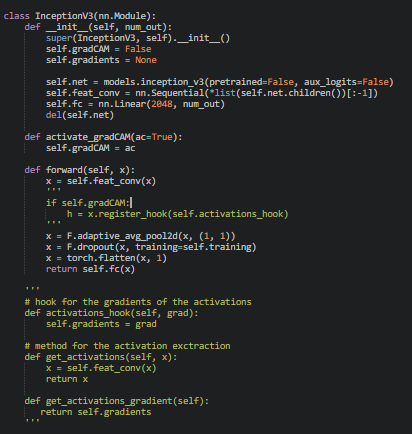
I’m considering discarding this approach and creating a separate module to get my visualization, totally apart from my training.
Thanks for the information.
self.feat_conv won’t contain the same forward pass as the original model, as all functional calls from the forward method will be lost.
E.g. this pooling operation will not be applied (neither the following), if you just wrap the child modules in an nn.Sequential block.
A better approach would be to derive a custom class from the base model and manipulate the forward method as you need.
Thanks, it was indeed a better approach, it is working fine now.
You helped a lot!