I would like to test the loss proposed in the Sobolev training paper. For example consider:
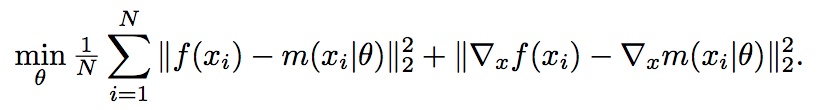
where m(x_i,\theta) is the network evaluated at x_i.
The first part is the usual MSE but I have no idea how to go for the second piece.
I would like to test the loss proposed in the Sobolev training paper. For example consider:
where m(x_i,\theta) is the network evaluated at x_i.
The first part is the usual MSE but I have no idea how to go for the second piece.
In practical examples they use first order derivative which actually is what you get with the framework right now. If you are trying to learn a function f (which in this case is a already trained network) you can compute gradients of the output wrt input. and m(x|O) is the network which is learning to approximate f.
In short, they apply an MSE not only over output but over gradients too.
This is my example that employs the derivative error as well as the MSE.
Thank you. This is what I was looking for.
At line 95 in potfit.py you have:
output0.sum().backward(retain_graph=True, create_graph=True)
why the .sum() is needed?
https://pytorch.org/docs/stable/autograd.html#torch.Tensor
If the sum() is not used, the backward() requires a gradient of the scalar function wrt Self.