I solve the problem by deleting the “inplace=True” for Torch 1.7
please , could you give me more details?
where did you put ‘inplace=True’?
Hey, has this issue been solved? I am having the same issue in exactly a similar scenario. If it is solved, could you please suggest the solution?
Thanks Jeff. It worked for me.
1 Like
I’m getting this error at loss.backward(). I don’t know what is this error. I’m using pytorch 1.10.1.
Exception has occurred: RuntimeError
one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [48, 2048]], which is output 0 of ReluBackward0, is at version 1; expected version 0 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
File "/home/ma/Downloads/Thesis/main_top_down_baseline.py", line 45, in train
loss.backward().clone()
File "/home/ma/Downloads/Thesis/main_top_down_baseline.py", line 253, in main
train(model, train_loader, dev_loader, optimizer, scheduler, n_epoch, args.output_dir, encoder, args.gpuid, clip_norm, model_name, args.model_saving_name,
File "/home/ma/Downloads/Thesis/main_top_down_baseline.py", line 262, in <module>
main()
This is model which I’m using
'''
This is the baseline model.
We directly use top-down VQA like mechanism for SR
Modified bottom-up top-down code from https://github.com/hengyuan-hu/bottom-up-attention-vqa and
added normalization from https://github.com/yuzcccc/vqa-mfb
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
import sys
torch.autograd.set_detect_anomaly(True)
sys.path.append('/home/ma/Downloads/Thesis')
from lib.attention import Attention
from lib.classifier import SimpleClassifier
from lib.fc import FCNet
import torchvision as tv
class vgg16_modified(nn.Module):
def __init__(self):
super(vgg16_modified, self).__init__()
vgg = tv.models.vgg16_bn(pretrained=True)
self.vgg_features = vgg.features
def forward(self,x):
features = self.vgg_features(x)
return features
class Top_Down_Baseline(nn.Module):
def __init__(self, convnet, role_emb, verb_emb, query_composer, v_att, q_net, v_net, classifier, encoder, Dropout_C):
super(Top_Down_Baseline, self).__init__()
self.convnet = convnet
self.role_emb = role_emb
self.verb_emb = verb_emb
self.query_composer = query_composer
self.v_att = v_att
self.q_net = q_net
self.v_net = v_net
self.classifier = classifier
self.encoder = encoder
self.Dropout_C = Dropout_C
def forward(self, v_org, gt_verb):
'''
:param v_org: original image
:param gt_verb: ground truth verb id
:return: predicted role label logits
'''
img_features = self.convnet(v_org)
batch_size, n_channel, conv_h, conv_w = img_features.size()
img_org = img_features.view(batch_size, -1, conv_h* conv_w)
v = img_org.permute(0, 2, 1)
batch_size = v.size(0)
role_idx = self.encoder.get_role_ids_batch(gt_verb)
if torch.cuda.is_available():
role_idx = role_idx.to(torch.device('cuda'))
img = v
img = img.expand(self.encoder.max_role_count, img.size(0), img.size(1), img.size(2))
img = img.transpose(0,1)
img = img.contiguous().view(batch_size * self.encoder.max_role_count, -1, v.size(2))
verb_embd = self.verb_emb(gt_verb)
role_embd = self.role_emb(role_idx)
verb_embed_expand = verb_embd.expand(self.encoder.max_role_count, verb_embd.size(0), verb_embd.size(1))
verb_embed_expand = verb_embed_expand.transpose(0,1)
#query for image reasoning
concat_query = torch.cat([ verb_embed_expand, role_embd], -1)
role_verb_embd = concat_query.contiguous().view(-1, role_embd.size(-1)*2)
q_emb = self.query_composer(role_verb_embd)
att = self.v_att(img, q_emb)
v_emb = (att * img).sum(1)
v_repr = self.v_net(v_emb)
q_repr = self.q_net(q_emb)
mfb_iq_eltwise = torch.mul(q_repr, v_repr)
mfb_iq_drop = self.Dropout_C(mfb_iq_eltwise)
#normalization to avoid model convergence to unsatisfactory local minima
mfb_iq_resh = mfb_iq_drop.view(batch_size* self.encoder.max_role_count, 1, -1, 1)
# sum pooling can be more useful if there are multiple heads like original MFB.
# we kept out head count to 1 for final implementation, but experimented with multiple without considerable improvement.
mfb_iq_sumpool = torch.sum(mfb_iq_resh, 3, keepdim=True)
mfb_out = torch.squeeze(mfb_iq_sumpool)
mfb_sign_sqrt = torch.sqrt(F.relu(mfb_out)) - torch.sqrt(F.relu(-mfb_out))
mfb_l2 = F.normalize(mfb_sign_sqrt)
out = mfb_l2
logits = self.classifier(out)
role_label_pred = logits.contiguous().view(v.size(0), self.encoder.max_role_count, -1)
return role_label_pred
def forward_hiddenrep(self, v_org, gt_verb):
'''
:param v_org: original image
:param gt_verb: ground truth verb id
:return: hidden representation which is the input to the classifier
'''
img_features = self.convnet(v_org)
batch_size, n_channel, conv_h, conv_w = img_features.size()
img_org = img_features.view(batch_size, -1, conv_h* conv_w)
v = img_org.permute(0, 2, 1)
batch_size = v.size(0)
role_idx = self.encoder.get_role_ids_batch(gt_verb)
if torch.cuda.is_available():
role_idx = role_idx.to(torch.device('cuda'))
img = v
img = img.expand(self.encoder.max_role_count, img.size(0), img.size(1), img.size(2))
img = img.transpose(0,1)
img = img.contiguous().view(batch_size * self.encoder.max_role_count, -1, v.size(2))
verb_embd = self.verb_emb(gt_verb)
role_embd = self.role_emb(role_idx)
verb_embed_expand = verb_embd.expand(self.encoder.max_role_count, verb_embd.size(0), verb_embd.size(1))
verb_embed_expand = verb_embed_expand.transpose(0,1)
concat_query = torch.cat([ verb_embed_expand, role_embd], -1)
role_verb_embd = concat_query.contiguous().view(-1, role_embd.size(-1)*2)
q_emb = self.query_composer(role_verb_embd)
att = self.v_att(img, q_emb)
v_emb = (att * img).sum(1)
v_repr = self.v_net(v_emb)
q_repr = self.q_net(q_emb)
mfb_iq_eltwise = torch.mul(q_repr, v_repr)
mfb_iq_drop = self.Dropout_C(mfb_iq_eltwise)
mfb_iq_resh = mfb_iq_drop.view(batch_size* self.encoder.max_role_count, 1, -1, 1) # N x 1 x 1000 x 5
mfb_iq_sumpool = torch.sum(mfb_iq_resh, 3, keepdim=True) # N x 1 x 1000 x 1
mfb_out = torch.squeeze(mfb_iq_sumpool) # N x 1000
mfb_sign_sqrt = torch.sqrt(F.relu(mfb_out)) - torch.sqrt(F.relu(-mfb_out))
mfb_l2 = F.normalize(mfb_sign_sqrt)
out = mfb_l2
return out
def forward_agentplace_noverb(self, v_org, pred_verb):
max_role_count = 2
img_features = self.convnet(v_org)
batch_size, n_channel, conv_h, conv_w = img_features.size()
img_org = img_features.view(batch_size, -1, conv_h* conv_w)
v = img_org.permute(0, 2, 1)
batch_size = v.size(0)
role_idx = self.encoder.get_agent_place_ids_batch(batch_size)
if torch.cuda.is_available():
role_idx = role_idx.to(torch.device('cuda'))
img = v
img = img.expand(max_role_count, img.size(0), img.size(1), img.size(2))
img = img.transpose(0,1)
img = img.contiguous().view(batch_size * max_role_count, -1, v.size(2))
#verb_embd = torch.sum(self.verb_emb.weight, 0)
#verb_embd = verb_embd.expand(batch_size, verb_embd.size(-1))
#verb_embd = torch.zeros(batch_size, 300).cuda()
verb_embd = self.verb_emb(pred_verb)
role_embd = self.role_emb(role_idx)
verb_embed_expand = verb_embd.expand(max_role_count, verb_embd.size(0), verb_embd.size(1))
verb_embed_expand = verb_embed_expand.transpose(0,1)
concat_query = torch.cat([ verb_embed_expand, role_embd], -1)
role_verb_embd = concat_query.contiguous().view(-1, role_embd.size(-1)*2)
q_emb = self.query_composer(role_verb_embd)
att = self.v_att(img, q_emb)
v_emb = (att * img).sum(1)
v_repr = self.v_net(v_emb)
q_repr = self.q_net(q_emb)
mfb_iq_eltwise = torch.mul(q_repr, v_repr)
mfb_iq_drop = self.Dropout_C(mfb_iq_eltwise)
mfb_iq_resh = mfb_iq_drop.view(batch_size* max_role_count, 1, -1, 1) # N x 1 x 1000 x 5
mfb_iq_sumpool = torch.sum(mfb_iq_resh, 3, keepdim=True) # N x 1 x 1000 x 1
mfb_out = torch.squeeze(mfb_iq_sumpool) # N x 1000
mfb_sign_sqrt = torch.sqrt(F.relu(mfb_out)) - torch.sqrt(F.relu(-mfb_out))
mfb_l2 = F.normalize(mfb_sign_sqrt)
out = mfb_l2
logits = self.classifier(out)
role_label_pred = logits.contiguous().view(v.size(0), max_role_count, -1)
role_label_rep = v_repr.contiguous().view(v.size(0), max_role_count, -1)
return role_label_pred, role_label_rep
def calculate_loss(self, gt_verbs, role_label_pred, gt_labels):
batch_size = role_label_pred.size()[0]
criterion = nn.CrossEntropyLoss(ignore_index=self.encoder.get_num_labels())
gt_label_turned = gt_labels.transpose(1,2).contiguous().view(batch_size* self.encoder.max_role_count*3, -1)
role_label_pred = role_label_pred.contiguous().view(batch_size* self.encoder.max_role_count, -1)
role_label_pred = role_label_pred.expand(3, role_label_pred.size(0), role_label_pred.size(1))
role_label_pred = role_label_pred.transpose(0,1)
role_label_pred = role_label_pred.contiguous().view(-1, role_label_pred.size(-1))
loss = criterion(role_label_pred, gt_label_turned.squeeze(1)) * 3
return loss
def build_top_down_baseline(n_roles, n_verbs, num_ans_classes, encoder):
hidden_size = 1024
word_embedding_size = 300
img_embedding_size = 512
covnet = vgg16_modified()
role_emb = nn.Embedding(n_roles+1, word_embedding_size, padding_idx=n_roles)
verb_emb = nn.Embedding(n_verbs, word_embedding_size)
query_composer = FCNet([word_embedding_size * 2, hidden_size])
v_att = Attention(img_embedding_size, hidden_size, hidden_size)
q_net = FCNet([hidden_size, hidden_size ])
v_net = FCNet([img_embedding_size, hidden_size])
classifier = SimpleClassifier(
hidden_size, 2 * hidden_size, num_ans_classes, 0.5)
Dropout_C = nn.Dropout(0.1)
return Top_Down_Baseline(covnet, role_emb, verb_emb, query_composer, v_att, q_net,
v_net, classifier, encoder, Dropout_C)
This is training loop.
import torch
import json
import os
from utils import utils, imsitu_scorer, imsitu_loader, imsitu_encoder
from models import top_down_baseline
def train(model, train_loader, dev_loader, optimizer, scheduler, max_epoch, model_dir, encoder, gpu_mode, clip_norm, model_name, model_saving_name, eval_frequency=4000):
model.train()
train_loss = 0
total_steps = 0
print_freq = 400
dev_score_list = []
if gpu_mode > 0 :
ngpus = 2
device_array = [i for i in range(0,ngpus)]
pmodel = torch.nn.DataParallel(model, device_ids=device_array)
else:
pmodel = model
top1 = imsitu_scorer.imsitu_scorer(encoder, 1, 3)
top5 = imsitu_scorer.imsitu_scorer(encoder, 5, 3)
for epoch in range(max_epoch):
for i, (_, img, verb, labels) in enumerate(train_loader):
total_steps += 1
if gpu_mode >= 0:
img = torch.autograd.Variable(img.cuda())
verb = torch.autograd.Variable(verb.cuda())
labels = torch.autograd.Variable(labels.cuda())
else:
img = torch.autograd.Variable(img)
verb = torch.autograd.Variable(verb)
labels = torch.autograd.Variable(labels)
role_predict = pmodel(img, verb)
loss = model.calculate_loss(verb, role_predict, labels)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip_norm)
optimizer.step()
optimizer.zero_grad()
train_loss += loss.item()
top1.add_point_noun(verb, role_predict, labels)
top5.add_point_noun(verb, role_predict, labels)
if total_steps % print_freq == 0:
top1_a = top1.get_average_results_nouns()
top5_a = top5.get_average_results_nouns()
print ("{},{},{}, {} , {}, loss = {:.2f}, avg loss = {:.2f}"
.format(total_steps-1,epoch,i, utils.format_dict(top1_a, "{:.2f}", "1-"),
utils.format_dict(top5_a,"{:.2f}","5-"), loss.item(),
train_loss / ((total_steps-1)%eval_frequency) ))
if total_steps % eval_frequency == 0:
top1, top5, val_loss = eval(model, dev_loader, encoder, gpu_mode)
model.train()
top1_avg = top1.get_average_results_nouns()
top5_avg = top5.get_average_results_nouns()
avg_score = top1_avg["verb"] + top1_avg["value"] + top1_avg["value-all"] + top5_avg["verb"] + \
top5_avg["value"] + top5_avg["value-all"] + top5_avg["value*"] + top5_avg["value-all*"]
avg_score /= 8
print ('Dev {} average :{:.2f} {} {}'.format(total_steps-1, avg_score*100,
utils.format_dict(top1_avg,'{:.2f}', '1-'),
utils.format_dict(top5_avg, '{:.2f}', '5-')))
dev_score_list.append(avg_score)
max_score = max(dev_score_list)
if max_score == dev_score_list[-1]:
torch.save(model.state_dict(), model_dir + "/{}_{}.model".format( model_name, model_saving_name))
print ('New best model saved! {0}'.format(max_score))
print('current train loss', train_loss)
train_loss = 0
top1 = imsitu_scorer.imsitu_scorer(encoder, 1, 3)
top5 = imsitu_scorer.imsitu_scorer(encoder, 5, 3)
del role_predict, loss, img, verb, labels
print('Epoch ', epoch, ' completed!')
scheduler.step()
def eval(model, dev_loader, encoder, gpu_mode, write_to_file = False):
model.eval()
print ('evaluating model...')
top1 = imsitu_scorer.imsitu_scorer(encoder, 1, 3, write_to_file)
top5 = imsitu_scorer.imsitu_scorer(encoder, 5, 3)
with torch.no_grad():
for i, (img_id, img, verb, labels) in enumerate(dev_loader):
print(img_id[0], encoder.verb2_role_dict[encoder.verb_list[verb[0]]])
if gpu_mode >= 0:
img = torch.autograd.Variable(img.cuda())
verb = torch.autograd.Variable(verb.cuda())
labels = torch.autograd.Variable(labels.cuda())
labels = torch.autograd.Variable(labels.cuda())
else:
img = torch.autograd.Variable(img)
verb = torch.autograd.Variable(verb)
labels = torch.autograd.Variable(labels)
role_predict = model(img, verb)
top1.add_point_noun(verb, role_predict, labels)
top5.add_point_noun(verb, role_predict, labels)
del role_predict, img, verb, labels
return top1, top5, 0
def main():
import argparse
parser = argparse.ArgumentParser(description="imsitu VSRL. Training, evaluation and prediction.")
parser.add_argument("--gpuid", default=0, help="put GPU id > -1 in GPU mode", type=int)
parser.add_argument('--output_dir', type=str, default='./main-TDA', help='Location to output the model')
parser.add_argument('--resume_training', action='store_true', help='Resume training from the model [resume_model]')
parser.add_argument('--resume_model', type=str, default='', help='The model we resume')
parser.add_argument('--evaluate', action='store_true', help='Only use the testing mode')
parser.add_argument('--evaluate_visualize', action='store_true', help='Only use the testing mode to visualize ')
parser.add_argument('--evaluate_rare', action='store_true', help='Only use the testing mode')
parser.add_argument('--test', action='store_true', help='Only use the testing mode')
parser.add_argument('--dataset_folder', type=str, default='./imSitu', help='Location of annotations')
parser.add_argument('--imgset_dir', type=str, default='./resized_256', help='Location of original images')
parser.add_argument('--train_file', default="train_freq2000.json", type=str, help='trainfile name')
parser.add_argument('--dev_file', default="dev_freq2000.json", type=str, help='dev file name')
parser.add_argument('--test_file', default="test_freq2000.json", type=str, help='test file name')
parser.add_argument('--model_saving_name', type=str, help='saving name of the outpul model')
parser.add_argument('--epochs', type=int, default=200)
parser.add_argument('--model', type=str, default='top_down_baseline')
parser.add_argument('--batch_size', type=int, default=8)
parser.add_argument('--seed', type=int, default=1111, help='random seed')
parser.add_argument('--clip_norm', type=float, default=0.25)
parser.add_argument('--num_workers', type=int, default=3)
args = parser.parse_args()
n_epoch = args.epochs
batch_size = args.batch_size
clip_norm = args.clip_norm
n_worker = args.num_workers
dataset_folder = args.dataset_folder
imgset_folder = args.imgset_dir
train_set = json.load(open(dataset_folder + '/' + args.train_file))
encoder = imsitu_encoder.imsitu_encoder(train_set)
train_set = imsitu_loader.imsitu_loader(imgset_folder, train_set, encoder,'train', encoder.train_transform)
constructor = 'build_%s' % args.model
model = getattr(top_down_baseline, constructor)(encoder.get_num_roles(),encoder.get_num_verbs(), encoder.get_num_labels(), encoder)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=n_worker)
dev_set = json.load(open(dataset_folder + '/' + args.dev_file))
dev_set = imsitu_loader.imsitu_loader(imgset_folder, dev_set, encoder, 'val', encoder.dev_transform)
dev_loader = torch.utils.data.DataLoader(dev_set, batch_size=batch_size, shuffle=True, num_workers=n_worker)
test_set = json.load(open(dataset_folder + '/' + args.test_file))
test_set = imsitu_loader.imsitu_loader(imgset_folder, test_set, encoder, 'test', encoder.dev_transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=True, num_workers=n_worker)
if not os.path.exists(args.output_dir):
os.mkdir(args.output_dir)
torch.manual_seed(args.seed)
if args.gpuid >= 0:
model.cuda()
torch.cuda.manual_seed(args.seed)
torch.backends.cudnn.benchmark = True
if args.resume_training:
print('Resume training from: {}'.format(args.resume_model))
args.train_all = True
if len(args.resume_model) == 0:
raise Exception('[pretrained module] not specified')
utils.load_net(args.resume_model, [model])
optimizer = torch.optim.Adamax(model.parameters(), lr=1e-3)
model_name = 'resume_all'
else:
print('Training from the scratch.')
model_name = 'train_full'
utils.set_trainable(model, True)
optimizer = torch.optim.Adamax([
{'params': model.convnet.parameters(), 'lr': 5e-5},
{'params': model.role_emb.parameters()},
{'params': model.verb_emb.parameters()},
{'params': model.query_composer.parameters()},
{'params': model.v_att.parameters()},
{'params': model.q_net.parameters()},
{'params': model.v_net.parameters()},
{'params': model.classifier.parameters()}
], lr=1e-3)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
if args.evaluate:
top1, top5, val_loss = eval(model, dev_loader, encoder, args.gpuid)
top1_avg = top1.get_average_results_nouns()
top5_avg = top5.get_average_results_nouns()
avg_score = top1_avg["verb"] + top1_avg["value"] + top1_avg["value-all"] + top5_avg["verb"] + \
top5_avg["value"] + top5_avg["value-all"] + top5_avg["value*"] + top5_avg["value-all*"]
avg_score /= 8
print ('Dev average :{:.2f} {} {}'.format( avg_score*100,
utils.format_dict(top1_avg,'{:.2f}', '1-'),
utils.format_dict(top5_avg, '{:.2f}', '5-')))
elif args.test:
top1, top5, val_loss = eval(model, test_loader, encoder, args.gpuid)
top1_avg = top1.get_average_results_nouns()
top5_avg = top5.get_average_results_nouns()
avg_score = top1_avg["verb"] + top1_avg["value"] + top1_avg["value-all"] + top5_avg["verb"] + \
top5_avg["value"] + top5_avg["value-all"] + top5_avg["value*"] + top5_avg["value-all*"]
avg_score /= 8
print ('Test average :{:.2f} {} {}'.format( avg_score*100,
utils.format_dict(top1_avg,'{:.2f}', '1-'),
utils.format_dict(top5_avg, '{:.2f}', '5-')))
else:
print('Model training started!')
train(model, train_loader, dev_loader, optimizer, scheduler, n_epoch, args.output_dir, encoder, args.gpuid, clip_norm, model_name, args.model_saving_name,
)
if __name__ == "__main__":
main()
The solution provided by jeff is not working for me. @ptrblck @albanD can you help me?
Could you reduce the code by removing unnecessary parts and post an executable code snippet to reproduce the issue, please?
Hi, I’m facing a similar issue but I don’t know what causes this error to rise.
This is my model
class ResidualBlock(nn.Module):
def __init__(self, in_channels, kernel_size=1, stride=1, padding=0, num_res = 2):
if num_res%2 !=0:
raise ValueError(f'num_res={num_res} which is not even, num_res must be even')
super(ResidualBlock, self).__init__()
layers = []
for _ in range(num_res):
layers.append(nn.Conv2d(in_channels = in_channels,
out_channels = in_channels, kernel_size=kernel_size, stride=stride, padding=padding))
layers.append(nn.ReLU())
self.seq = nn.Sequential(*layers)
def forward(self, x):
res = torch.clone(x)
for i in range(len(self.seq)):
x = self.seq[i].forward(x)
# print(self.seq[i])
if (i+1)%4==0:
# print('res')
x+=res
res = torch.clone(x)
return x
class Resnet16(nn.Module):
def __init__(self, in_channels=3):
super(Resnet16, self).__init__()
self.convnet = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
ResidualBlock(in_channels=64,kernel_size=3, stride=1, padding=1,num_res=4),
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
ResidualBlock(in_channels=256, kernel_size=3, stride=1, padding=1, num_res=4),
nn.BatchNorm2d(256),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
ResidualBlock(in_channels=512, kernel_size=3, stride=1, padding=1, num_res=4),
nn.AvgPool2d(kernel_size=3),
)
self.fcnet = nn.Sequential(
nn.Linear(2048,512),
nn.ReLU(),
nn.Linear(512,256),
nn.ReLU(),
nn.Linear(256,10)
)
def forward(self,x):
x = self.convnet(x)
bs = x.shape[0]
x = x.view(bs,-1)
x = self.fcnet(x)
return x
And this is the part of the optimizer that optimizes my model
from torch.optim import Adam
# model = VGG()
model = Resnet16(3)
optimizer_params = {
'params': model.parameters(),
'lr':1e-3
}
optimizer = Adam(optimizer_params['params'],optimizer_params['lr'])
trainer_params = {
'model': model,
'train_loader': trainloader,
'valid_loader': testloader,
'criterion': nn.CrossEntropyLoss(),
'optimizer': optimizer,
'epochs': 10,
'print_every':2,
'pth_filename': 'model.pth',
'trainset_sz': len(trainset),
'validset_sz': len(testset)
}
.
.
.
.
for data, labels in train_loader:
# putting data in working device
data = data.to(device)
labels = labels.to(device)
# forward propagation
output = model(data)
loss = criterion(output, labels)
# backward propagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
# logging training loop results
training_loss += loss.item()
Try to remove all inplace operations such as x += res and see, if this would help.
5 Likes
It worked, thanks so much!!
hi guys, I’m facing the similar issue when I want to do backward() too. really need your help. Big thanks for your help here. ![]()
@ptrblck @albanD
code in training process:
def train(rho_data, size, train_size, mine_net, optimizer, iteration, input_size, tau):
criterion = nn.BCEWithLogitsLoss()
diff_et = torch.tensor(0.0)
data, test_p0, test_q0, label, train_index, marg_index = recons_data(rho_data, size,
train_size)
for i in range(iteration):
batch_size = int(len(data)/4)
if input_size == 2:
test_p = torch.FloatTensor(test_p0[:,[0,2]])
test_q = torch.FloatTensor(test_q0[:,[0,2]])
else:
test_p = torch.FloatTensor(test_p0)
test_q = torch.FloatTensor(test_q0)
train_batch, index1, index2 = sample_batch(data, input_size,
batch_size = batch_size,
sample_mode = 'joint')
label_batch = label[index1]
train_batch = torch.autograd.Variable(torch.FloatTensor(train_batch), requires_grad=True)
label_batch = torch.FloatTensor(label_batch)
logit = mine_net(train_batch)[0]
loss = criterion(logit.reshape(-1), label_batch)
if i < iteration-1:
optimizer.zero_grad()
loss.backward()
optimizer.step()
else:
optimizer.zero_grad()
loss.backward(retain_graph = True)
optimizer.step()
train_batch.grad.zero_()
loss.backward()
grads = train_batch.grad
if i >= iteration-101:
prob_p = mine_net(test_p)[1]
rn_est_p = prob_p/(1-prob_p)
finp_p = torch.log(torch.abs(rn_est_p))
prob_q = mine_net(test_q)[1]
rn_est_q = prob_q/(1-prob_q)
a = torch.abs(rn_est_q)
clip = torch.max(torch.min(a,torch.exp(tau)), torch.exp(-tau))
diff_et = diff_et+torch.max(torch.mean(finp_p)-torch.log(torch.mean(clip)), torch.tensor(0.0))
return (diff_et/100).detach().cpu().numpy(), grads, index1, train_index, marg_index
problem from system:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [130, 1]], which is output 0 of AsStridedBackward0, is at version 1002; expected version 1001 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
Could you explain your use case and in particular why you are using retain_graph=True as this ususally yields these kind of errors (and is often used as a workaround for another error)?
Hi ptrblck, many thanks for your help here. I have solved this bug here.
else: optimizer.zero_grad() loss.backward(retain_graph = True) optimizer.step() train_batch.grad.zero_() loss.backward() grads = train_batch.grad
Hi guys . I met the problem with loss.backward() as you can see here
File “train.py”, line 360, in train
loss_adv.backward(retain_graph=True)
File “/usr/local/lib/python3.7/dist-packages/torch/_tensor.py”, line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File “/usr/local/lib/python3.7/dist-packages/torch/autograd/init.py”, line 175, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [512, 7]], which is output 0 of AsStridedBackward0, is at version 2; expected version 1 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
My code is
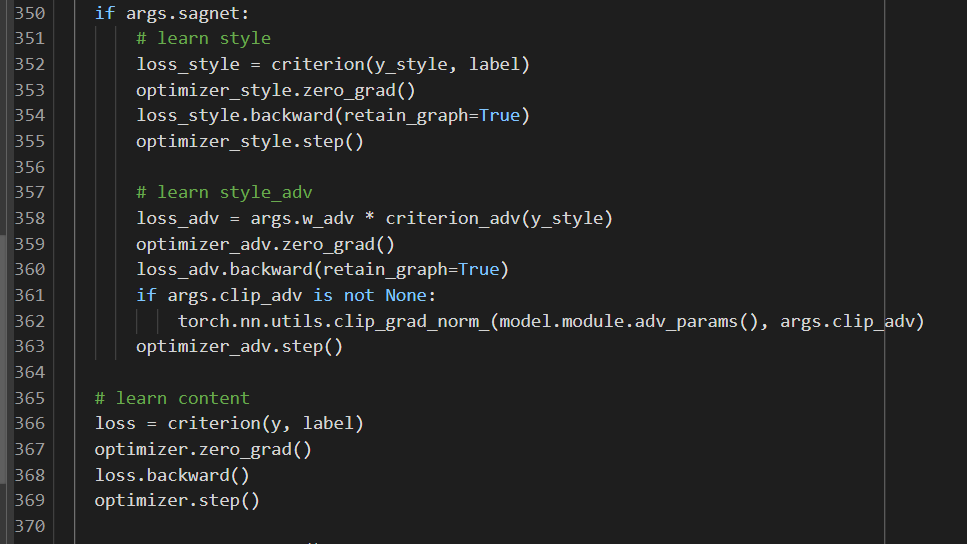
I use pytorch 1.12.1 in google colab
Can anyone help me to solve this problem .Thank you very much
@ptrblck @albanD can you help me
Could you also check why retain_graph is used in your code?
When I don’t use retain_graph=True I meet this problem
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
In that case try to fix this issue as it seems your computation graph is growing in each iteration such that the backward pass would try to compute the gradient for multiple iterations.
This could happen e.g. if the input to your model depends somehow on the output from the previous iteration.
Try moving all the optimizer steps to the very end after all the backwards have completed
See these two similar issues:
- MobileFSGAN - One of the variables needed for gradient computation has been modified by an inplace operation
- RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [1]] is at version 2; expected version 1 instead - #14 by soulitzer
2 Likes
Now , it work well .Thank you for your suggestion
Now , it work well when I move all the optimizer step after all backwards .Thanks for yours suggestion
Hi raharth,
In case you or anyone else are still struggling in this problem, I would like to post the solution I just figure out to disable version checking intentionally by adding saved_tensors_hooks. This could work because according to the source of the version checking, the version checking is implemented as an unpack hook and would be skipped if there are any other hooks defined.
A minimal demo would be
import torch
from torch.autograd import Variable
a = Variable(torch.randn([3,4]), requires_grad=True)
b = torch.randn([3, 1])
def pack_hook(x):
print("Packing")
return x
def unpack_hook(x):
print("Unpacking")
return x
# if True:
with torch.autograd.graph.saved_tensors_hooks(pack_hook, unpack_hook):
c = a * b
d = c.sum()
b[0][0] = 1.
d.backward()
print(a.grad)
In my case, I have one thread that is using the model being trained by another thread. I want to avoid copying the model between threads since it’s time consuming for my task and only one thread needs to be accurate.