I was going through the pytorch official example - “word_language_model” and found the following line of code in the train() function.
# Starting each batch, we detach the hidden state from how it was previously produced.
# If we didn't, the model would try backpropagating all the way to start of the dataset.
hidden = repackage_hidden(hidden)
I am not understanding why we need to detach hidden variable from the hidden variable associated with the previous batch of input? When gradients are computed and loss is backpropagated, weight matrices are usually affected by the chain of computation.
Why the hidden variables which represents hidden states of a recurrent neural network is at a risk to get affected during backpropagation and should be detached from previous value?
When the hidden variable should be detached from previous value? At the beginning of each batch? or beginning of each training epoch?
If we did not truncate the history of hidden states (c, h), the back-propagated gradients would flow from the loss towards the beginning, which may result in gradient vanishing or exploding. Detailed explanation can be found here.
Why the hidden variables which represents hidden states of a recurrent neural network is at a risk to get affected during backpropagation and should be detached from previous value?
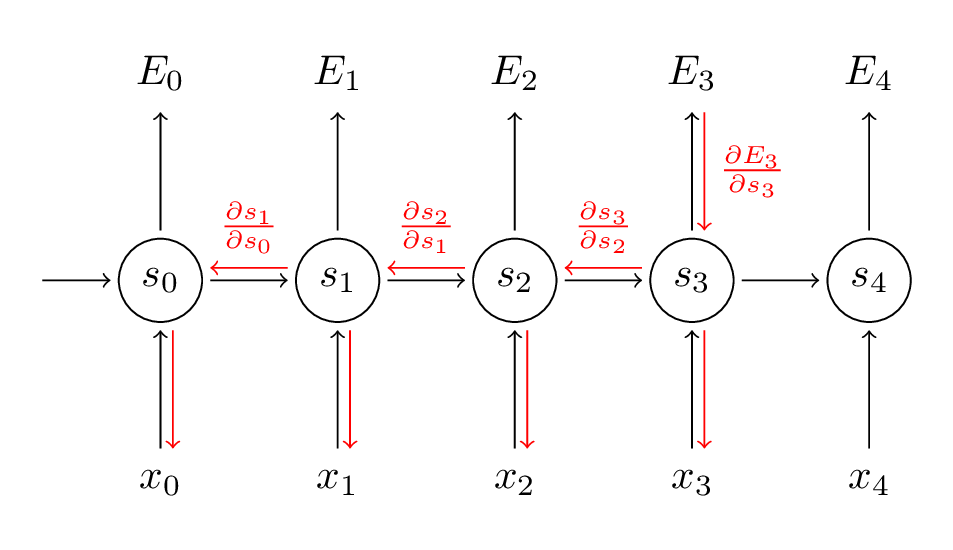
As in the diagram below, the error E3 depends on hidden state s3, which depends on s2, which depends on s1 and so on. At timestep t=100, to compute the gradients we will have to consider last 100 states.
We don’t want that: we want to assume that for some k, the hidden state s[t-k] is constant and does not depend on anything.
To achieve this we take a batch of k words and simply assume that the initial hidden state for this batch is constant and doesn’t depend on anything.
But for pytorch, if you call hidden = model(batch, hidden), all of those hidden states are connected. So at the start of each batch you have to manually tell pytorch: “here’s the hidden state from previous batch, but consider it constant”.
I believe you could simply call hidden.detach_() though, no need to create new Variable. (@smth ?)
Hello, thanks for the nice answer, it explains a lot! But I still have a question:
Although in the example given by @wasiahmad the hidden states are detached in train() (using repackeage_hidden() ), in some examples of nn.lstm(), it’s just simply used as:
, where input is tensor of sequences (or a packed sequence), and the initial hidden states h_0, c_0 are initialized automatically.
In the example above, the hidden states are not detached manually. I am wondering if the attachment is done automatically here, or BPTT is computed based on all previous hidden states without doing any detachments? Thanks.
In your examples new zero-initialized hidden states are initialized at every call to the lstm, and therefore are not connected to the previous sequence in any way. The language modeling example needs to detach them, beacuse it retains the values of hidden states between training states (but doesn’t want to backprop very far back).
Hello, I come up with a specific question about the detachment op we discuss here.
For example, we have a seq2seq model with an attention layer between the encoder and the decoder. According to the common implementations of attention models, the last hidden state of the encoder (say, ‘hn’) is used as the first hidden state of the decoder.
My question is: is it necessary to detach hn from the encoder network?
how do we detach the states from the output of GRU layer:
def detach_states(self, states):
if states is None:
return states
return [state.detach() for state in states]
are output from the GRU layer. When I pass them to
self.gru(X, initial_states)
It gives me following error: …
File “/Users/user_name/anaconda/lib/python3.5/site-packages/torch/nn/modules/rnn.py”, line 162, in check_forward_args
check_hidden_size(hidden, expected_hidden_size)
File “/Users/user_name/anaconda/lib/python3.5/site-packages/torch/nn/modules/rnn.py”, line 153, in check_hidden_size
if tuple(hx.size()) != expected_hidden_size:
AttributeError: ‘list’ object has no attribute ‘size’
What I am doing wrong. I can put the entire code if this is not clear.
I honestly feel a bit disappointed by such ducktaping. Why does a user need to know OR even keep repackage_hidden(h) in his code? This recurrency implementation is specific to pytorch and is just confusing considering that both Tensorflow and even older Torch never expose it.
Hi there! I would like to know if the first case in your comment is at all possible in PyTorch? I’ve just created a thread on a very similar use case: How to backpropagate a loss through time-series RNN?, and I was wondering whether one can actually perform online training with RNNs where the hidden states are never detached (i.e. backpropagating through all seen data) without stumbling upon autograd errors. Thank you!