I’m a new starter of pytorch. When I create my RNN model, I meet some problems as following:
import torch
import torch.nn.functional as F
from torch import nn, optim
from torch.autograd import Variable
from numpy import *
from torch.utils.data import DataLoader
from mydataset import MyDataset
CONTEXT_SIZE = 1
EMBEDDING_DIM = 10
HIDDEN_UNITS = 50
test_sentence = """When forty winters shall besiege thy brow,
And dig deep trenches in thy beauty's field,
Thy youth's proud livery so gazed on now,
Will be a totter'd weed of small worth held:
Then being asked, where all thy beauty lies,
Where all the treasure of thy lusty days;
To say, within thine own deep sunken eyes,
Were an all-eating shame, and thriftless praise.
How much more praise deserv'd thy beauty's use,
If thou couldst answer 'This fair child of mine
Shall sum my count, and make my old excuse,'
Proving his beauty by succession thine!
This were to be new made when thou art old,
And see thy blood warm when thou feel'st it cold.""".split()
trigram = [(test_sentence[i], test_sentence[i + 1])
for i in range(len(test_sentence) - 1)]
x_set = [test_sentence[i] for i in range(len(test_sentence)-1)]
y_set = [test_sentence[i+1] for i in range(len(test_sentence)-1)]
vocb = set(test_sentence)
word_to_idx = {word: i for i, word in enumerate(vocb)}
idx_to_word = {word_to_idx[word]: word for word in word_to_idx}
dataset = MyDataset(x_set,y_set)
train_loader = DataLoader(dataset,batch_size=5)
class RNNModel(nn.Module):
def __init__(self, vocb_size,embdding_size,hidden_size):
super(RNNModel, self).__init__()
self.n_word = vocb_size
self.embedding = nn.Embedding(self.n_word, embdding_size)
#self.embedding = OneHot(vocb)
self.rnn = nn.RNN(embdding_size, hidden_size,num_layers=2,nonlinearity='relu')
self.linear = nn.Linear(hidden_size, embdding_size)
def forward(self, x, hidden):
x = self.embedding(x)
input = torch.cat((x.view(1,-1),hidden.view(1,-1)),dim=1)
output1, h_n = self.rnn(input)
output2 = self.linear2(output1)
log_prob = F.log_softmax(output2)
return log_prob, h_n
rnnmodel = RNNModel(len(word_to_idx), EMBEDDING_DIM, HIDDEN_UNITS)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(rnnmodel.parameters(), lr=1e-3)
for epoch in range(3):
print('epoch: {}'.format(epoch + 1))
print('*' * 10)
running_loss = 0
input_hidden = torch.autograd.Variable(torch.randn(1, HIDDEN_UNITS))
for data in trigram:
word, label = data
word = Variable(torch.LongTensor([word_to_idx[word]]))
label = Variable(torch.LongTensor([word_to_idx[label]]))
# forward
out,input_hidden = rnnmodel(word,input_hidden)
loss = criterion(out, label)
running_loss += loss.data[0]
# backward
#optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
print('Loss: {:.6f}'.format(running_loss / len(word_to_idx)))
The class mydataset is really simple:
class MyDataset(data.Dataset):
def __init__(self, words, labels):
self.words = words
self.labels = labels
def __getitem__(self, index):
input, target = self.words[index], self.labels[index]
return input, target
def __len__(self):
return len(self.words)
But I receive some error on my console as following:
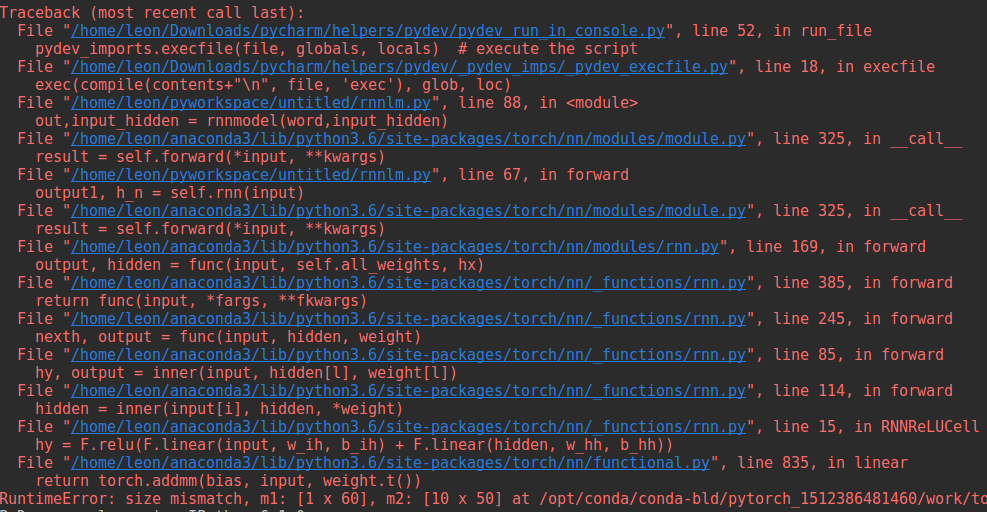
Thanks for your answers.
And if you have some example for RNN and using minibatch in training, plz tell me.Thank you again.