I built a simple convolutional neural network model using Keras framework and PyTorch framework respectively. But there are some questions between Keras and Pytorch.
The data used is an open source - PHM 2010 Tool wear data set
I choose C1 set as my data set which contains 315 samples, each sample has 7 signal inputs, and one sample returns a wear value.
The structure of CNN in Keras framework and Pytorch framework is same, but the output results are different. The loss function is the mean square error function.
criterion = torch.nn.MSELoss(reduction=‘mean’)
I do not understand where the problem is.
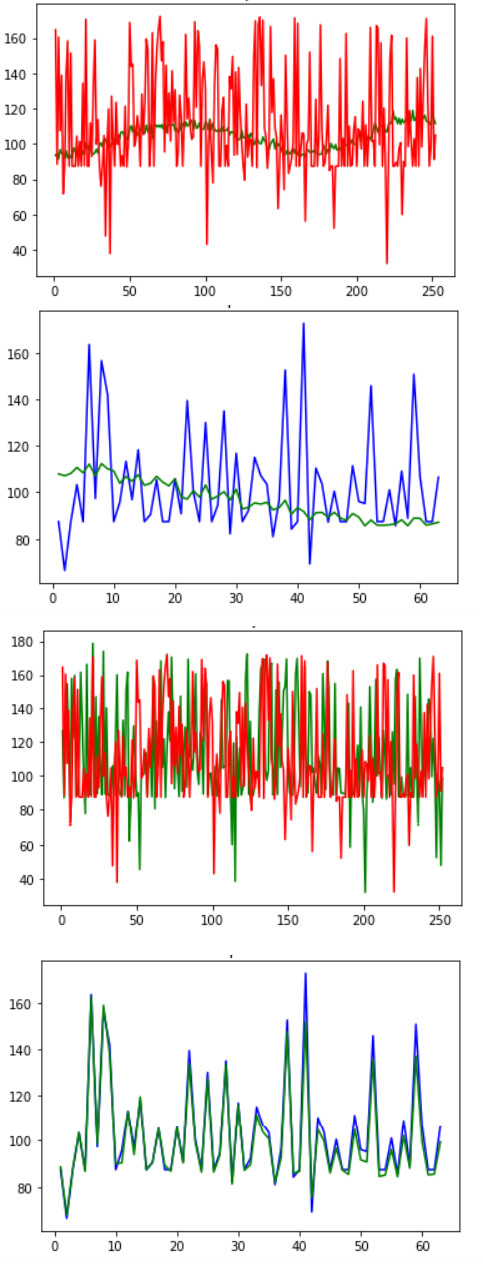
Curves fit well under the Keras framework, but only a straight line can be trained under the PyTorch framework.The details are shown in Figures 1 and 2.
The training code under the PyTorch framework is shown below.
criterion = torch.nn.MSELoss(reduction=‘mean’)
#criterion = nn.SmoothL1Loss(reduction=‘mean’)
optimizer = optim.Adam(model.parameters(),lr=0.001)
iterations = 40
loss_tend =
y_predict_store =
for i in range(iterations):
print(‘*’*60)
print(‘the epoch :’,i+1)
y_pred_store =
tmd =
loss_sum = 0
start = time.time()
loss_list =
model.train()
for k,(X_train1,Y_train1) in enumerate(loader_train):
y_pred = model(X_train1)
loss = criterion(y_pred,Y_train1)
print('the result of y_pred and Y_train1: ',y_pred,Y_train1)
for p in range(len(y_pred)):
temp = y_pred[p].item()
y_pred_store.append(temp)
loss1 = loss.item()
loss_list.append(loss1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
end = time.time()
tmd = np.array(loss_list)
print(np.size(tmd))
loss_mean = np.sum(tmd)/252
loss_tend.append(loss_mean)
print('loss_sum:',loss_mean)
print('the time of this epoch :',end-start)
print('print y_pred_store: ',y_pred_store)
print(‘print loss_tend:’,loss_tend)
“”"
test set
“”"
for i,(X_test1,Y_test1) in enumerate(loader_test):
model.eval()
predict = model(X_test1)
loss = criterion(predict,Y_test1)
for w in range(len(predict)):
temp_test = predict[w].item()
y_predict_store.append(temp_test)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(y_predict_store)
After experiments, I found that if I change the MSE loss function to the MSE of one of samples in this batch as the loss function, and the output is well.
The specific code is shown below.Figure3 and Figure 4 .
def sunshi(X,Y):
loss = criterion(X[0],Y[0])
return loss
model = CNN()
import torch.optim as optim
criterion = torch.nn.MSELoss(reduction=‘mean’)
#criterion = nn.SmoothL1Loss(reduction=‘mean’)
#criterion = torch.nn.L1Loss(reduction=‘mean’)
optimizer = optim.Adam(model.parameters(),lr=0.001)
iterations = 2000
loss_tend =
y_predict_store =
for i in range(iterations):
print(‘*’*60)
print(‘the epoch :’,i+1)
y_pred_store =
tmd =
loss_sum = 0
start = time.time()
loss_list =
model.train()
for k,(X_train1,Y_train1) in enumerate(loader_train):
y_pred =
y_pred = model(X_train1)
loss = sunshi(y_pred,Y_train1)
print('the result of y_pred and Y_train1: ',y_pred,Y_train1)
for p in range(len(y_pred)):
temp = y_pred[p].item()
y_pred_store.append(temp)
loss1 = loss.item()
loss_list.append(loss1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
end = time.time()
tmd = np.array(loss_list)
print(np.size(tmd))
loss_mean = np.sum(tmd)/252
loss_tend.append(loss_mean)
print('loss_sum:',loss_mean)
print('the time of this epoch :',end-start)
print('print y_pred_store: ',y_pred_store)
print(‘print loss_tend:’,loss_tend)
“”"
重新编写测试集
“”"
for i,(X_test1,Y_test1) in enumerate(loader_test):
model.eval()
predict = model(X_test1)
loss = criterion(predict,Y_test1)
for w in range(len(predict)):
temp_test = predict[w].item()
y_predict_store.append(temp_test)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(y_predict_store)
From what has been discussed above.
- Why does the same structure have different results under Keras and PyTorch
2.Why does the model work when I change the loss function from the MSE of the whole batch to the MSE of a sample
3.Under the PyTorch framework, the training effect of the training set is poor, but the test set is better.
Link to complete code:https://github.com/charmerphil/Try-to-explore-the-difference-between-Keras-and-PyTorch.git
Figure: