Hi ,
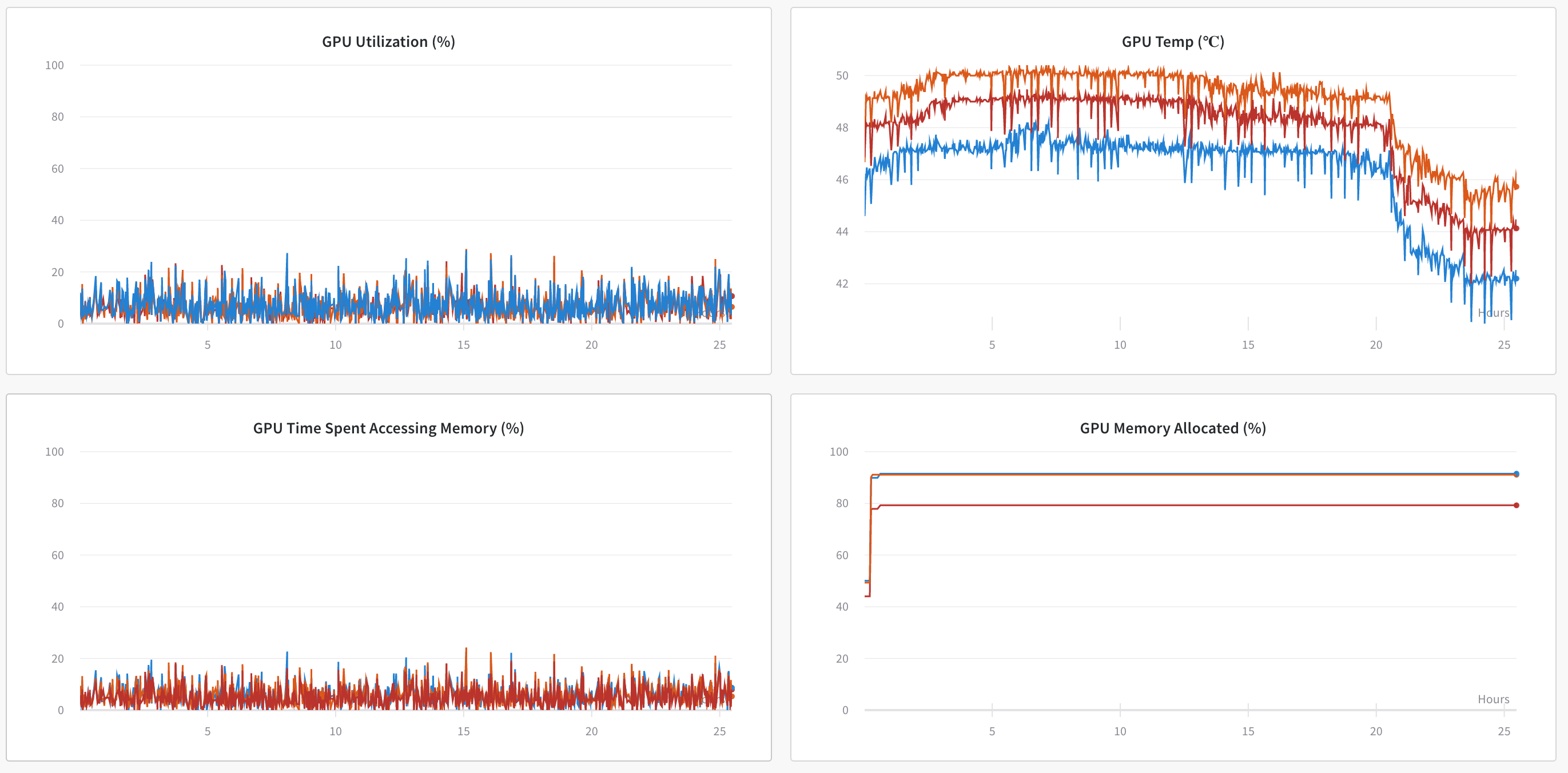
I am trying to speed up the training process and use the resources optimally. My GPU utilization is low but my GPU memory is full, I am really not able to understand, where is the bottleneck and how to approach it.
Below are my system results -
I am training the 10k images which are resized from size 2048,2048 to size 512,512.
I want to train it further on larger resolution too but it is maxing out at 1024,1024. But, my GPU utilisation is really low.
Batch size is 20.
Is there any way to allocate less memory and maximise GPU utilisation.
Also, any other suggestions to optimise it is hugely appreciated.
If GPU memory is getting full, then one reason might be, you are accumulating history somewhere. Like you do when you do total_loss += loss rather than doing total_loss += float(loss).
Oh, I never knew about it. Yes, I am doing it - train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data - train_loss))
and valid loss valid_loss += valid_loss + ((1 / (batch_idx + 1)) * (loss.data - valid_loss)).
I’ll change it , are there any more such issues which results in accumulating history.
Thanks.