I’ve followed the few posts here about splitting networks and autograd, but if I plot my weights/parameters it suggests split layers are not learning properly.
My setup:
input = Variable(torch.FloatTensor(data_batch))
target = Variable(torch.FloatTensor(target_batch))
x = input[:,:-1] # last column of input needed at end
y = input[:, -1].reshape(batch, -1)
z = x.clone()
z = f(z) # common layer
z1 = z.clone() # branch 1
z1 = f(z1)
z2 = z.clone() # branch 2
z2 = f(z2)
output = z1 + y*z2 # output
Gradients (red) and weights for ten epochs, shared layer:
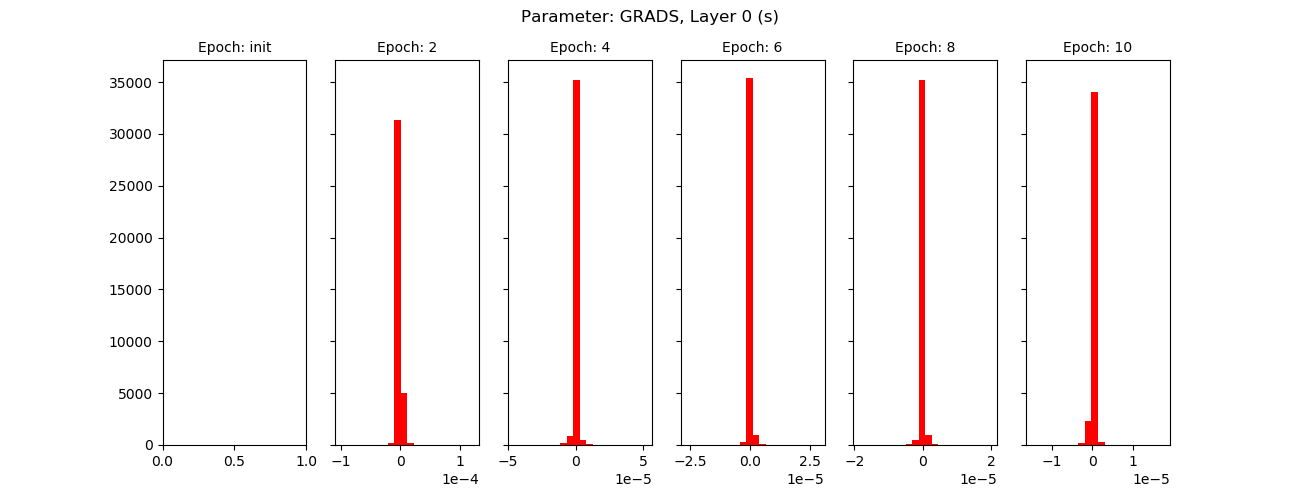
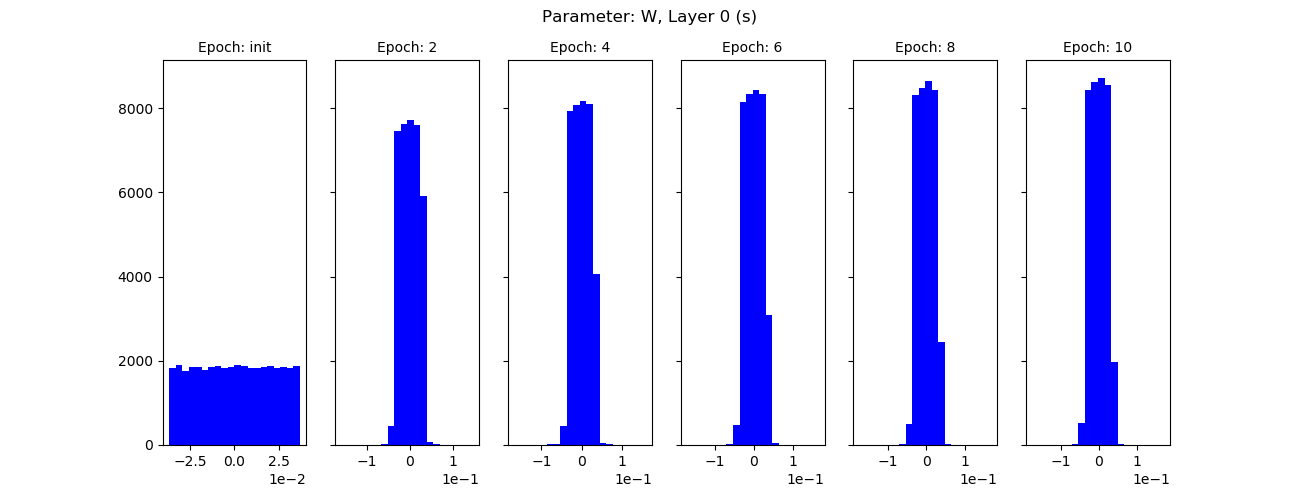
For branch 1:
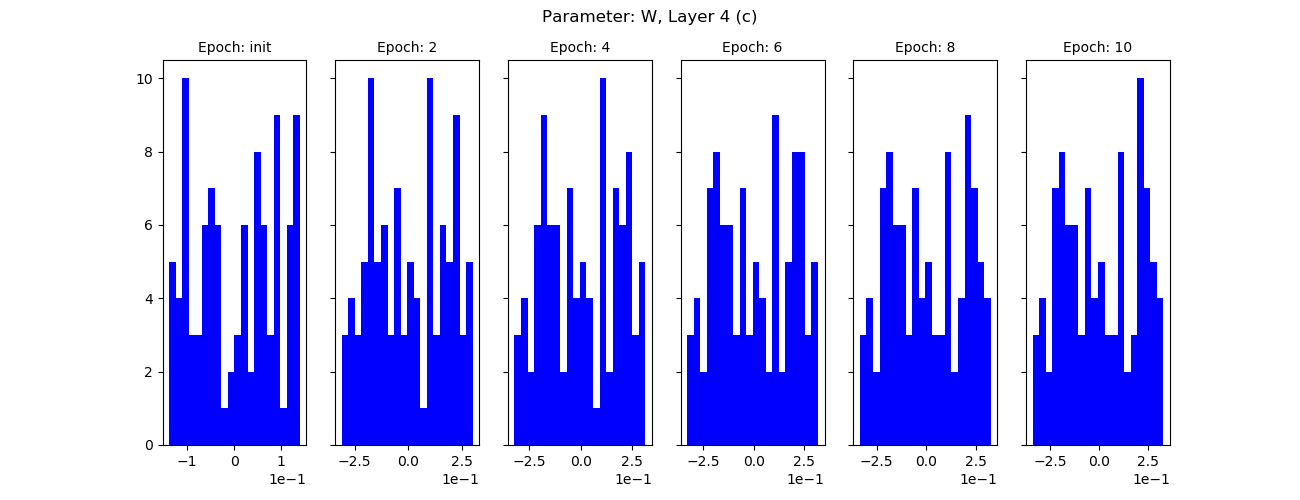
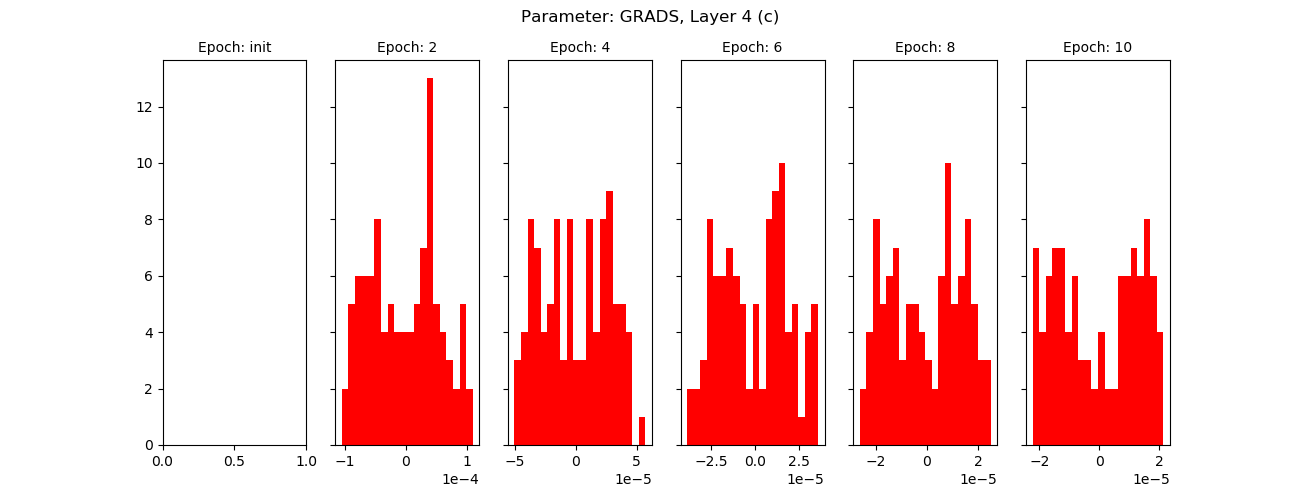
For branch 2:
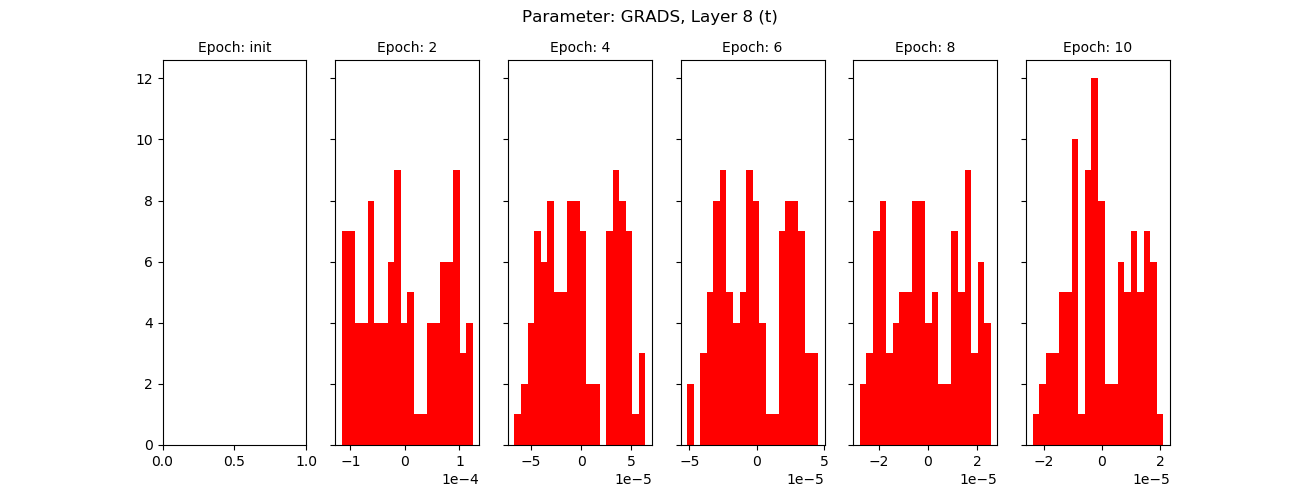
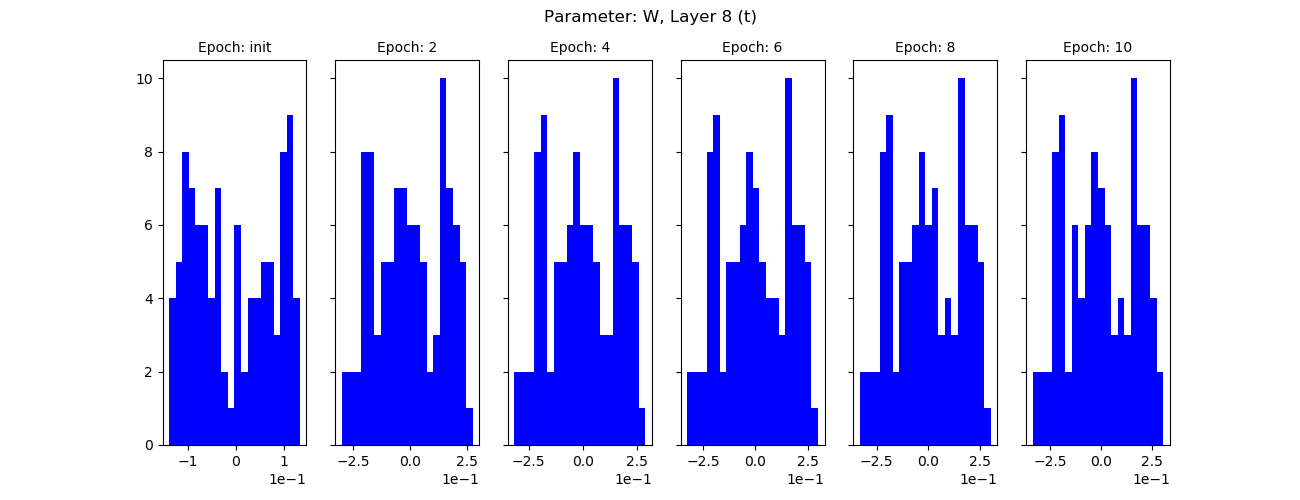
I suspect I’m not splitting properly, looks to me like the split layers are simply not learning. I have validated that cloning creates a new variable object in memory, but I’m missing something here.
Any insight appreciated.