Hey all! Say I’ve got a network like the following
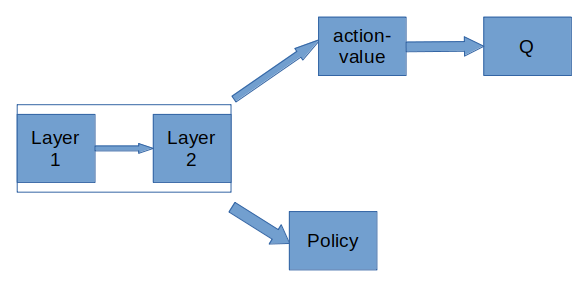
Training the RL algorithm, DDPG, comprises 2 steps:
{kind=link}
I see a number of implementations online, but most do not have a shared layer so I don’t have a baseline to compare against.
Line 12 and 13
This portion describes how to compute the loss and gradient update through the first head (Q->action-value)
Line 14
This portion describes how to compute the loss and gradient update through the second head, Policy. I’ve coded it such that on every pass of the actor-critic I receive 2 outputs, the policy and the Q-value.
I’ve separated this into 2 optimization steps:
Step 1
self.actor_critic.critic_optimizer.zero_grad()
_, y_hat_critic = self.actor_critic(s_batch, a_batch)
critic_loss = F.mse_loss(y_hat_critic, y_critic)
critic_loss.backward()
self.custom_gradient_scaling_for_shared(self.actor_critic.parameters())
self.actor_critic.critic_optimizer.step()
Step 2
self.actor_critic.actor_optimizer.zero_grad()
_, y_hat_policy = self.actor_critic(s_batch)
policy_loss = T.mean(-y_hat_policy)
policy_loss.backward()
self.custom_gradient_scaling_for_shared(self.actor_critic.parameters())
self.actor_critic.actor_optimizer.step()
P.s I’ve verified that in the first case, the policy head’s gradient update is zero, and in the second, although a gradient is generated for the Q-value head, it is not applied.
However, I am facing an issue in terms of determining if the 2 pass update would cause the shared layer to run into stability issues. I’ve got self.custom_gradient_scaling_for_shared(self.actor_critic.parameters()) which determines if the update is for the shared layer, and if it is, it just scales the gradient.
Does anyone have insights into this?