Hello ,
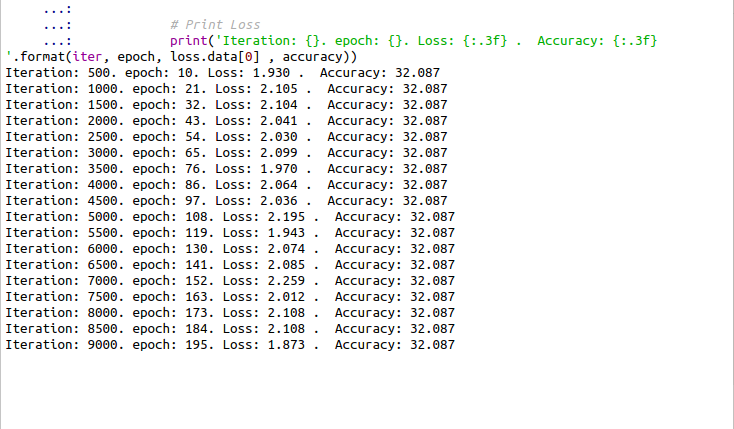
I’m having a stagnate accuracy on my model
model_in = MLPModel(input_dim, args.MLP_in_width[0], args.MLP_in_width[1], args.MLP_in_width[2],args.MLP_in_width[2])
if torch.cuda.is_available():
model_in.cuda()
# RNN--------------------------------------------------------------------------
model_RNN = LSTMModel(args.MLP_in_width[2], args.hidden_dim, args.layer_dim, args.output_dim_rnn)
if torch.cuda.is_available():
model_RNN.cuda()
# MLP_OUT-----------------------------------------------------------------------
model_out = MLPModel(args.output_dim_rnn, args.MLP_out_width[0], args.MLP_out_width[1], args.MLP_out_width[2], output_dim)
if torch.cuda.is_available():
model_out.cuda()
#features_train_MLP = np.zeros((features_train.shape[0],features_train.shape[1],features_train.shape[2]))
if torch.cuda.is_available():
features_train_MLP=torch.zeros([batch_size,features_train.shape[1],features_train.shape[2]]).cuda()
#STEP 5: INSTANTIATE LOSS CLASS------------------------------------------------
unique, counts = np.unique(labels_train, return_counts=True)
#dict(zip(unique, counts))
#counts = np.power(counts.astype(float), -1/2)
#counts = counts / counts.sum()
#counts_t = torch.from_numpy(counts).type(torch.FloatTensor).cuda()
criterion = nn.CrossEntropyLoss()
#STEP 6: INSTANTIATE OPTIMIZER CLASS-------------------------------------------
learning_rate = args.learning_rate
parameters = list(model_in.parameters()) + list(model_RNN.parameters()) + list(model_out.parameters())
optimizer = torch.optim.SGD(parameters, lr=learning_rate)
#STEP 7: TRAIN THE MODEL-------------------------------------------------------
iter = 0
first_pass = False
for epoch in range(num_epochs):
for i, (features, labels) in enumerate(train_loader):
features=features.type(torch.FloatTensor)
labels = labels.type(torch.LongTensor)
features_mlp_in = torch.zeros([batch_size , seq_dim , args.MLP_in_width[2]])
features_mlp_in = features_mlp_in.type(torch.FloatTensor)
if torch.cuda.is_available():
features = Variable(features.cuda())
labels = Variable(labels.cuda())
features_mlp_in = Variable(features_mlp_in.cuda())
else:
features = Variable(features)
labels = Variable(labels)
features_mlp_in = Variable(torch.zeros([batch_size , seq_dim , args.MLP_in_width[2]]))
# Clear gradients w.r.t. parameters
optimizer.zero_grad()
# Forward pass to get output from MLP_in
for j in range (seq_dim):
outputs_mlp_1 = model_in(features[:,j,:])
features_mlp_in[:,j,:] = outputs_mlp_1.data
# Forward pass to get output from rnn
outputs_rnn = model_RNN(features_mlp_in)
# Forward pass to get output from MLP_out
outputs = model_out(outputs_rnn)
# Calculate Loss: softmax --> cross entropy loss
loss = criterion(outputs, labels)
# Getting gradients w.r.t. parameters
loss.backward()
# Updating parameters
#if epoch == args.lr_steps and ( first_pass == False ) :
# learning_rate = learning_rate * args.learning_rate
# optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# first_pass = True
optimizer.step()
iter += 1
if iter % 500 == 0 :
# Calculate Accuracy
correct = 0
total = 0
# Iterate through test dataset
for features, labels in test_loader:
features = features.type(torch.FloatTensor)
features_mlp_in_t = torch.zeros([batch_size , seq_dim , args.MLP_in_width[2]])
features_mlp_in_t = features_mlp_in_t.type(torch.FloatTensor)
if torch.cuda.is_available():
features = Variable(features.cuda())
features_mlp_in_t = Variable(features_mlp_in_t.cuda())
# Forward pass to get output from MLP_in
for j in range (seq_dim):
outputs_mlp_1 = model_in(features[:,j,:])
features_mlp_in_t[:,j,:] = outputs_mlp_1.data
# Forward pass to get output from rnn
outputs_rnn = model_RNN(features_mlp_in_t)
# Forward pass only to get output
outputs = model_out(outputs_rnn)
# Get predictions from the maximum value
_, predicted = torch.max(outputs.data, 1)
# Total number of labels
total += labels.size(0)
# Total correct predictions
correct += (predicted.type(torch.DoubleTensor).cpu() == labels.cpu()).sum()
accuracy = 100 * correct / total
# Print Loss
print('Iteration: {}. epoch: {}. Loss: {:.3f} . Accuracy: {:.3f} '.format(iter, epoch, loss.data[0] , accuracy))