Hello,
I have a strange issue when loading checkpoints from a long running training process. Before I create an issue on Github about this I wanted to know if anyone has encountered something like this, or that it maybe is a known issue?
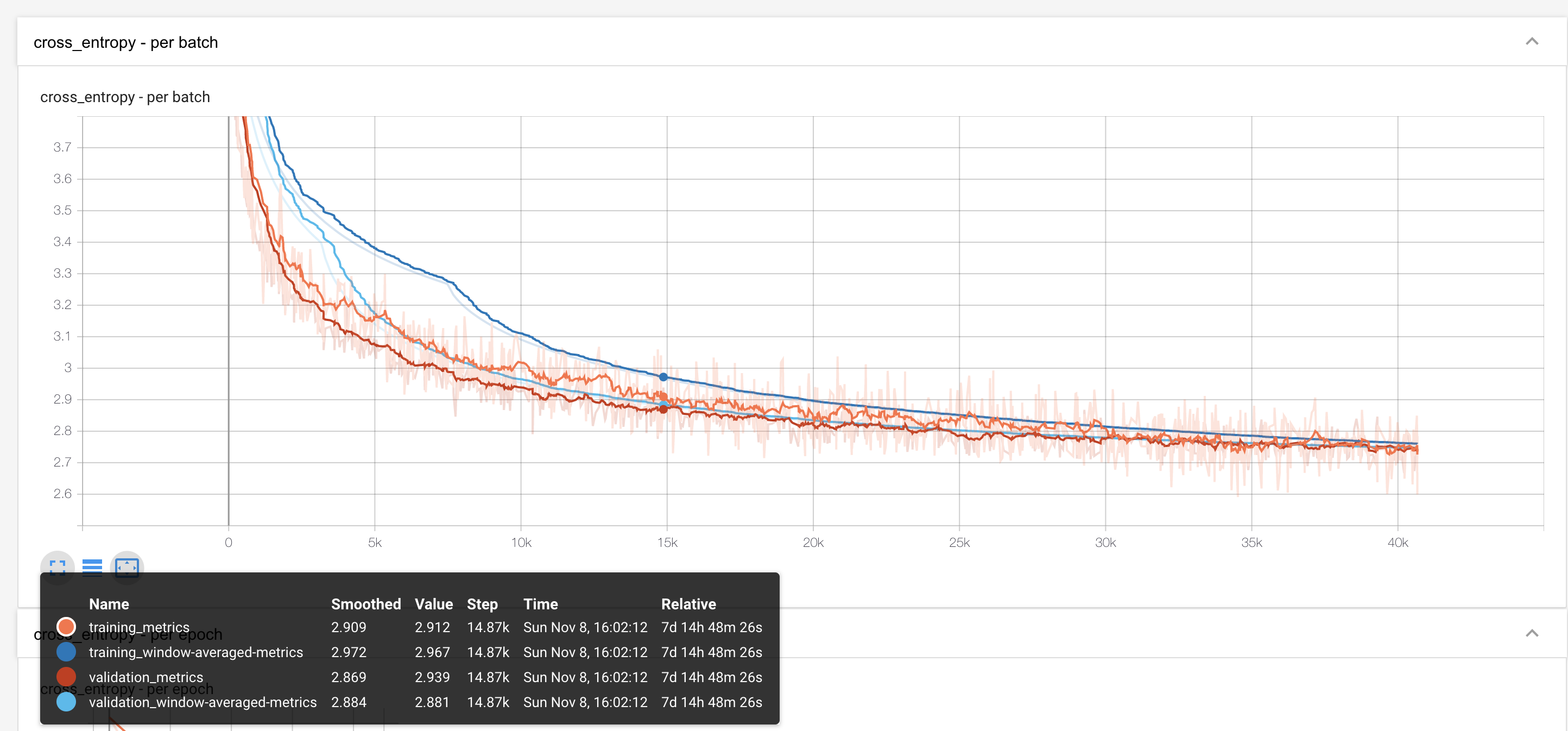
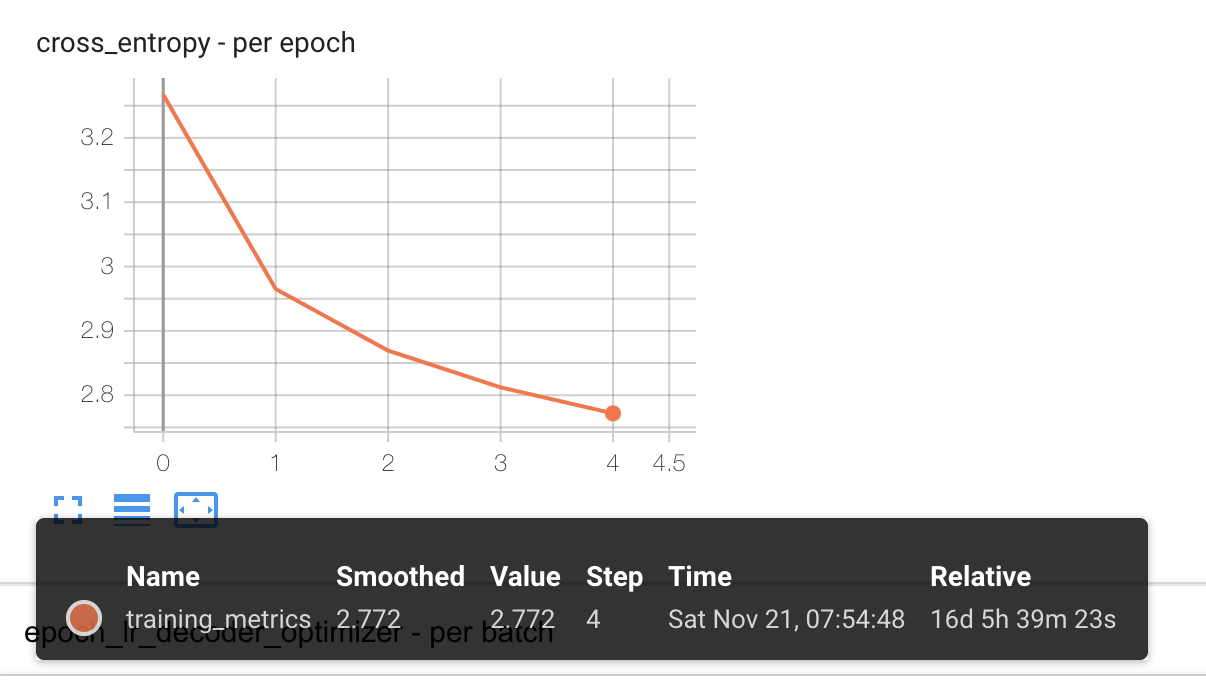
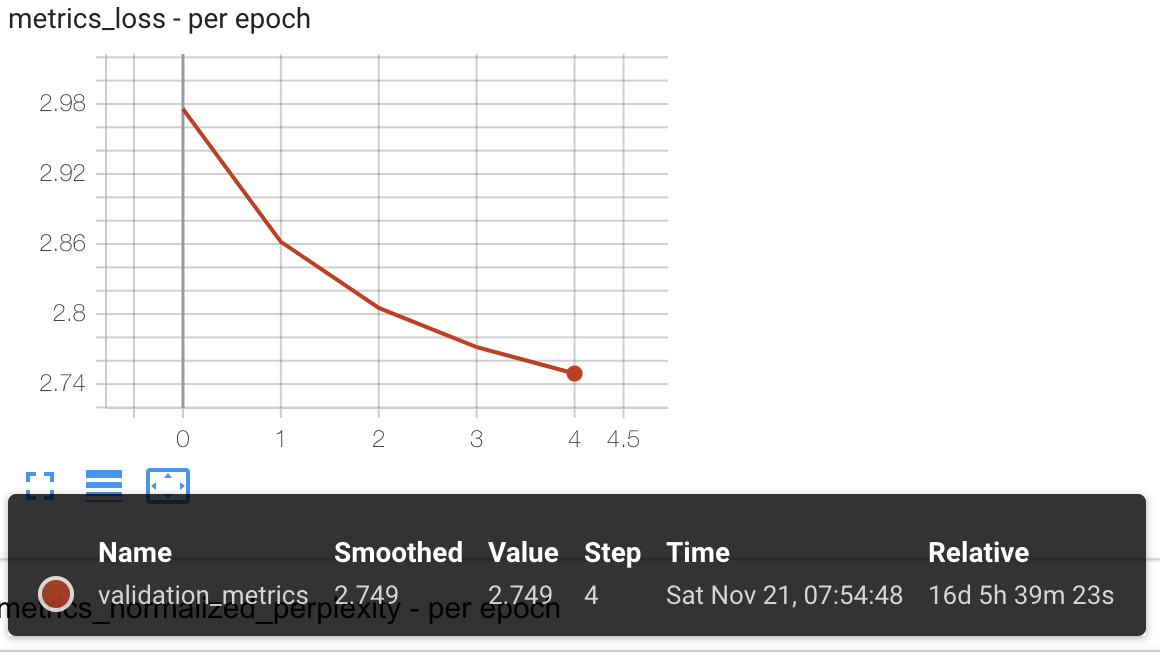
I have a training process that has been running for about 22 days now (Pytorch 1.6, DistributedDataParallel using 4 GPUs, Pytorch native mixed precision training). I checked a saved checkpoint after about 8 days and after loading it, it worked well (inference results made sense). Now after 22 days, I loaded the most recent checkpoint and got inference results that made no sense.
So I started comparing the parameters in both checkpoints. What I found was that in the ‘faulty’ checkpoint the first two values of each parameter tensor are close to zero, while this is not the case in the good checkpoint. Please see the attached images.
Is any issue like this known to you?
Good checkpoint:
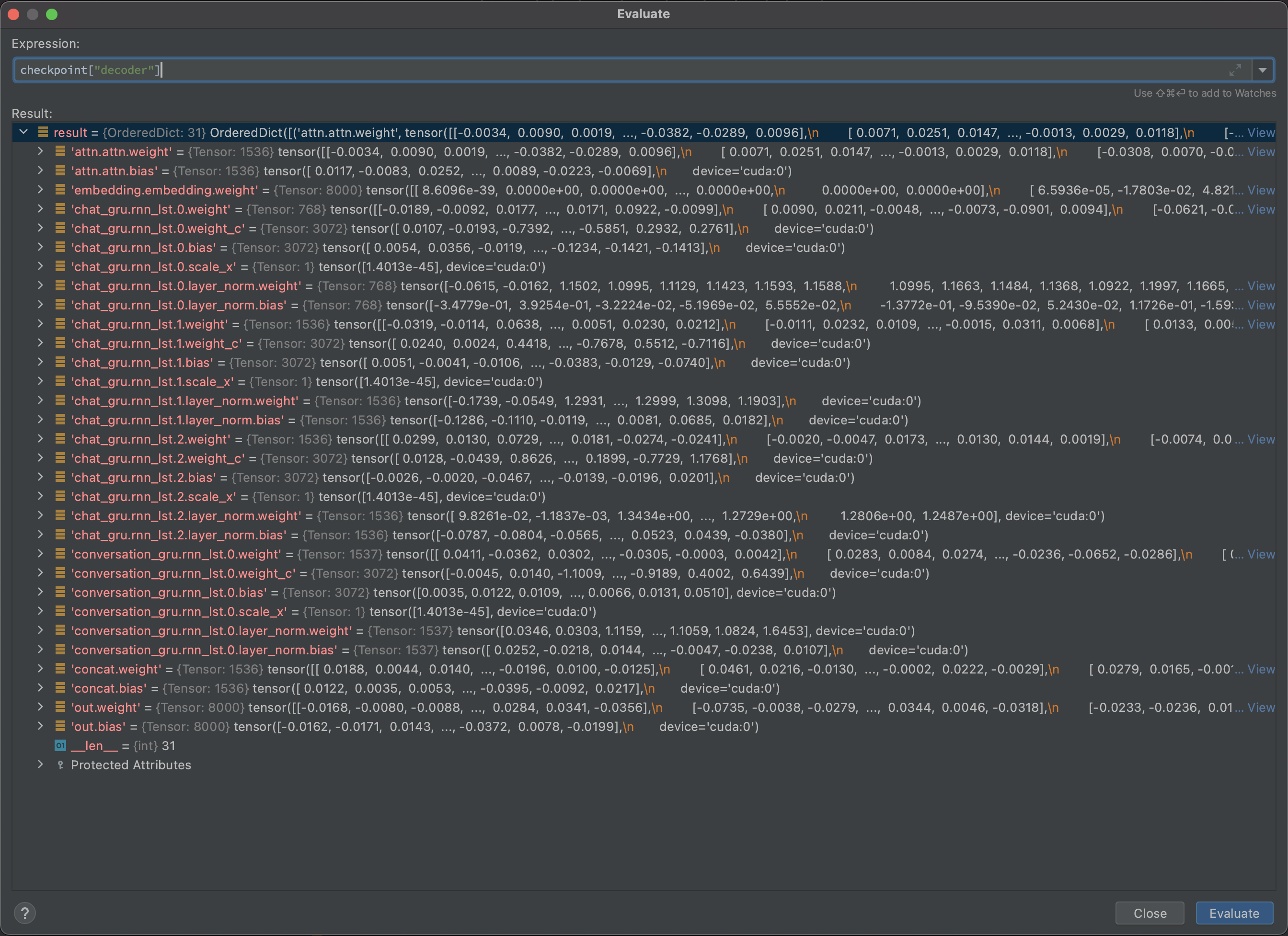
Faulty checkpoint:

Note: just to be clear, the faulty checkpoint was from much later in the training process and should have a much lower loss (as was calculated during training).