I’m trying to implement a model for image-text joint embedding, which is trained by optimizing the pariwise ranking loss. However I noticed a problem about LSTM’s last hidden state (often used as the embedding of the input sequence) – its statistical property is a bit weird.
The input batch is (160 sequences, 18 max sequence length) as shown in the picture:
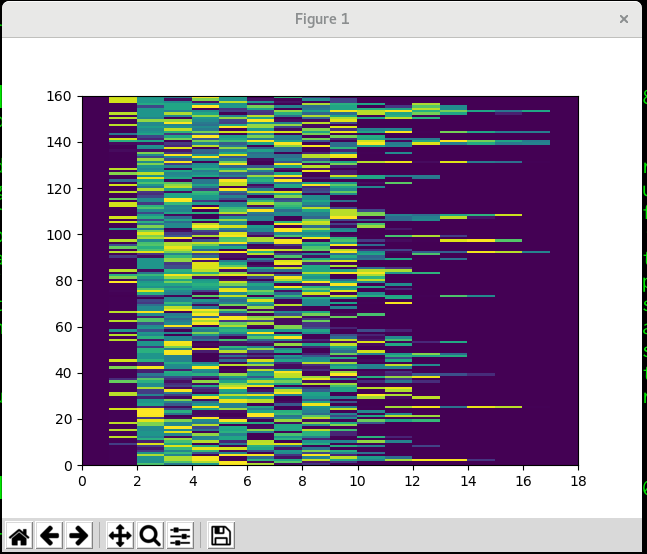
and the last hidden state from a fresh (untrained) LSTM looks like this:
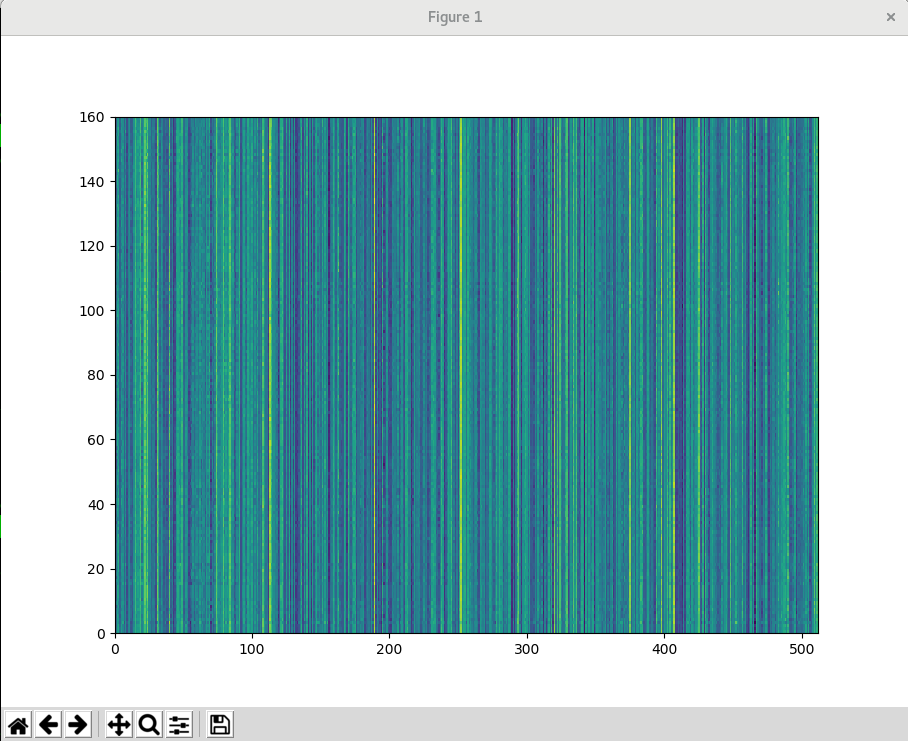
There are obvious vertcial stripes. Word embedding in use is torchtext.vocab.GloVe.
This statistical problem leads to inferior performance and a bad joint embedding space. After some iterations, vertical stipes will also appear in the cnn feature matrix.
Does anyone know how to solve this problem? Thanks in advance.