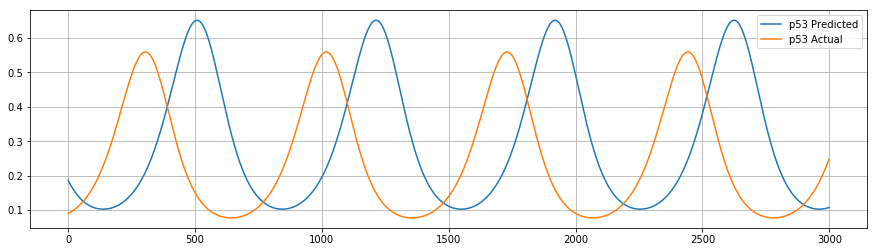
I am trying to develop a model for parameter estimation in which some parameters are allowed to train and some parameters are not allowed to train. e.g. In following matrix w_matrix = np.array([[w1,0.0,0.0,-w2],[w3,-w4,0.0,0.0],[0.0,w5,-w6,0.0]] all 0.0 are fixed weight and all w are allowed to update.
My attempt is as follows:
class NeuralNet(nn.Module):
def __init__(self,param):
super(NeuralNet, self).__init__()
param.append(0.0)
self.gamma = torch.tensor(param[0])
self.gamma = Variable(self.gamma,
requires_grad=True).type(dtype)
self.alpha_xy = torch.tensor(param[1])
self.aplha_xy = Variable(self.alpha_xy,
requires_grad=True).type(dtype)
self.beta_y = torch.tensor(param[2])
self.beta_y = Variable(self.beta_y,
requires_grad=True).type(dtype)
self.alpha0 = torch.tensor(param[3])
self.alpha0 = Variable(self.alpha0,
requires_grad=True).type(dtype)
self.alpha_y = torch.tensor(param[4])
self.alpha_y = Variable(self.alpha_y,
requires_grad=True).type(dtype)
self.alpha1 = torch.tensor(param[5])
self.alpha1 = Variable(self.alpha1,
requires_grad=True).type(dtype)
self.alpha2 = torch.tensor(param[6])
self.alpha2 = Variable(self.alpha2,
requires_grad=True).type(dtype)
self.alpha3 = torch.tensor(param[7])
self.alpha3 = Variable(self.alpha3,
requires_grad=True).type(dtype)
self.zero_fix_wt = torch.tensor(param[8])
self.zero_fix_wt = Variable(self.zero_fix_wt,
requires_grad=False).type(dtype)
# Production Matrix
self.w_production = torch.tensor([[self.gamma, self.zero_fix_wt, self.zero_fix_wt, self.zero_fix_wt],
[self.beta_y, self.zero_fix_wt, self.zero_fix_wt self.zero_fix_wt],
[self.zero_fix_wt, self.alpha0, self.zero_fix_wt, self.zero_fix_wt]])
self.w_production = Variable(self.w_production.to(device)).type(dtype)
self.w_production = nn.Parameter(self.w_production)
# Degradation Matrix
self.w_decay = torch.tensor([[-self.alpha1, self.zero_fix_wt, self.zero_fix_wt, self.zero_fix_wt],
[self.zero_fix_wt, -self.alpha2, self.zero_fix_wt, self.zero_fix_wt],
[self.zero_fix_wt, self.zero_fix_wt, -self.alpha_y, self.zero_fix_wt]])
self.w_decay = Variable(self.w_decay.to(device)).type(dtype)
self.w_decay = nn.Parameter(self.w_decay)
# Cross-Talk Matrix
self.w_cross_talk = torch.tensor([[self.zero_fix_wt, self.zero_fix_wt, self.zero_fix_wt, -self.alpha_xy],
[self.zero_fix_wt, self.zero_fix_wt, self.zero_fix_wt, self.zero_fix_wt],
[self.zero_fix_wt, self.zero_fix_wt, self.zero_fix_wt, -self.alpha3]])
self.w_cross_talk = Variable(self.w_cross_talk.to(device)).type(dtype)
self.w_cross_talk = nn.Parameter(self.w_cross_talk)
def forward(self,input):
xy_term = input[0][0] * input[0][2]
input_new = torch.cat((input,xy_term.view([-1,1])),1)
input_new = input_new.to(device,non_blocking=True)
hidden_state = (self.w_production + self.w_decay + self.w_cross_talk).mm(torch.transpose(input_new,0,1))
out = hidden_state.view([-1,3]) + input
return (out, hidden_state)
# parameter initialization
init_params = [2.0,3.7,1.5,1.1,0.9,0.1,0.9,0.01]
# define model in GPU
model = NeuralNet(init_params)
model = model.to(device)
loss_function = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3,momentum = 0.9)
start = datetime.now()
loss_1 = []
for i in tqdm(range(epochs)):
total_loss = 0
for j in range(x_train.size(0)):
optimizer.zero_grad()
input = x_train[j:(j+1)]
target = y_train[j:(j+1)]
input = input.to(device,non_blocking=True)
target = target.to(device,non_blocking=True)
(pred, _) = model(input)
loss = loss_function(pred,target)
total_loss += loss
loss.backward()
optimizer.step()
print(model.w_production)
# Early Stopping
loss_1.append(total_loss.item())
if len(loss_1) > 1 and np.abs(loss_1[-2] - total_loss.item()) <= 0.10:
print('Early Stopping due to dIfference in error is less than threshold (0.10)')
print('Stopping training at %d epochs with total loss = %d' %(i,total_loss))
break
if i % 50 == 0:
print("Epoch: {} loss {}".format(i, total_loss))
end = datetime.now()
time_taken = end - start
print('Execution Time: ',time_taken)
Here problem I am facing is that loss.backward() and optimizer.step() compute the gradient and adjust it for all weight even I have set requires_grad=False for some weights. This is happening because of requires_grad=False workes either on the complete matrix or not at all.
My question is how to tell model not to touch fixed weight and never compute the gradient for the specifically defined fixed weight for which requires_grad=False is mentioned.