Hello, all.
I meet a problem that speed of function tensor.sum() is strange when calculate the same kind of Tensor.
I want to calculate the confusion matrix of a foreground/background segmentation model, and below is my testing code:
import time
import torch
def func(pr, gt):
dump = 0.0
for gt_i in range(2):
for pr_i in range(2):
num = (gt == gt_i) * (pr == pr_i)
start = time.time()
dump += num.sum()
print("Finding Time: {} {} {t:.4f}(s)".format(gt_i, pr_i, t=(time.time() - start)))
if __name__ == '__main__':
gt = torch.rand(1, 400, 400) > 0.5
gt = gt.int().cuda()
print(">>>>>>>>>>>>>>> Test One >>>>>>>>>>>>>>>")
prob1 = torch.rand(1, 2, 400, 400)
_, pr1 = prob1.topk(1, 1, True, True)
pr1 = torch.squeeze(pr1, 1)
pr1 = pr1.int().cuda()
print(type(pr1), pr1.size())
func(gt, pr1)
print(">>>>>>>>>>>>>>> Test Two >>>>>>>>>>>>>>>")
prob2 = torch.rand(1, 2, 400, 400)
prob2 = prob2.cuda()
_, pr2 = prob2.topk(1, 1, True, True)
pr2 = torch.squeeze(pr2, 1)
pr2 = pr2.int()
print(type(pr2), pr2.size())
func(gt, pr2)
And the result is
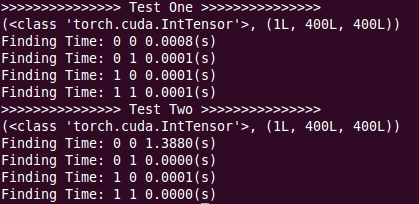
The speed of tensor.sum() of (gt == 0) * (pr == 0) in Test Two is very strange. However input tensor type of Test One and Test Two is the same.
I can not find the reason… Is there some hidden property of Tensor that i missed? Anyone can give some help?
Thanks