I am currently using a hybrid model using pytorch by hybrid I mean Autoencoder and CNN and here is my model :
convnet(
(fc_encoder): Sequential(
(0): Linear(in_features=9950, out_features=200, bias=True)
)
(decoder): Sequential(
(0): Linear(in_features=200, out_features=9950, bias=True)
)
(con1): Conv1d(1, 2, kernel_size=(5,), stride=(1,))
(max1): MaxPool1d(kernel_size=4, stride=4, padding=0, dilation=1, ceil_mode=False)
(con2): Conv1d(2, 4, kernel_size=(5,), stride=(1,))
(max2): MaxPool1d(kernel_size=4, stride=4, padding=0, dilation=1, ceil_mode=False)
(l1): Linear(in_features=2480, out_features=1024, bias=True)
(drop): Dropout(p=0.5, inplace=False)
(l2): Linear(in_features=1024, out_features=512, bias=True)
(l3): Linear(in_features=512, out_features=128, bias=True)
(l4): Linear(in_features=128, out_features=32, bias=True)
(l5): Linear(in_features=32, out_features=1, bias=True)
)
I have some doubts regarding:
-
I am using one loss function to evaluate my model which is BCELoss. I want to know if hybrid model is implemented do I need to use 2 loss functions? What will happen if I evaluate my model just on one loss function?
-
The second question is if I am changing my learning rate I have a big difference in the ROC curve why this is happening?
Any clarification needed for the shape of the input I can provide.
Thanks in advance 
This is my class to define the model:
class convnet(nn.Module):
def init(self,num_inputs=9950):
super(convnet,self).init()
self.num_inputs=num_inputs
self.fc_encoder= nn.Sequential(
nn.Linear(num_inputs,200)
)
self.decoder = nn.Sequential(
nn.Linear(200,num_inputs)
)
self.con1=nn.Conv1d(1, 2, 5)
self.max1=nn.MaxPool1d(4)
self.con2=nn.Conv1d(2, 4, 5)
self.max2=nn.MaxPool1d(4)
self.l1=nn.Linear(2480,1024)
self.drop=nn.Dropout(p= 0.5)
self.l2=nn.Linear(1024,512)
self.l3=nn.Linear(512,128)
self.l4=nn.Linear(128,32)
self.l5=nn.Linear(32,1)
def forward(self, x):
x = self.fc_encoder(x)
x = self.decoder(x)
x=x.unsqueeze(1)
x=self.con1(x)
x=self.max1(x)
x=self.con2(x)
x=self.max2(x)
x = x.view(x.size(0), -1)
x=self.l1(x)
x=self.drop(x)
x=self.l2(x)
x=self.l3(x)
x=self.l4(x)
x=self.l5(x)
return torch.sigmoid(x)
m = convnet()
m.to(device)
If I’m not mistaken, you are passing the inputs first to the Autoencoder and pass this output to the CNN.
The code for this looks generally alright and you wouldn’t need to use two losses, if your complete model only returns a single output.
Note that the last linear layers are used without any non-linearly, which could be reduced to a single linear transformation, so you might want to add some activation function between them.
-
As described, it depends on your use case, but the current model definition would not need two separate loss functions. You could of course use the Autoencoder output to calculate an auxiliary loss, but that’s up to you.
-
The learning rate is a hyperparameter and it is expected that your model performance suffers from a bad learning rate value. E.g. if you set it to an unreasonably high values such as 1000 your model would most likely not converge.
PS: you can post code snippets by wrapping them into three backticks ```, which makes debugging easier. 
1 Like
Thank you so much for your reply. Reading your answer has really helped me to understand the concepts. I really appreciate your help 
Yes you are correct first I am passing it to auto encoder and then to CNN. I will add a activation function to my model thank you for the suggestion 
The reason I got confused in the loss function is because I am getting very high accuracy which seems too good to be true. I am getting accuracy of 0.99% by using learning rate 0.0003 and the ROC as attached below with your experience is it normal to get such high accuracy? Or I am doing something wrong?
I have data set of size 1035 split is 90/10 for training and testing respectively.
Thanks in advance
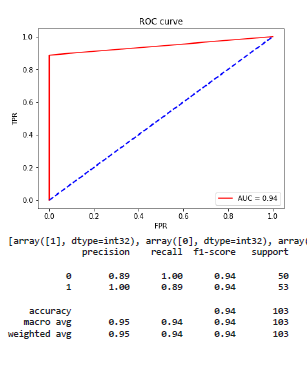
You could get such high accuracy values and it of course depends on the data set and used model.
Usually you would split the dataset into three parts:
- training data, which is only used during the training to update the parameters
- validation data, which is often used after each full training epoch, to apply early stopping and for general hyperparameter tuning
- test data, which is never touched during training/validation, but one single time, if you end the training and would like to test the final model.
In the most careful approach, you should not modify the model or any hyperparameter anymore, as you would be leaking the test error information into the training, after calculating the test error.
1 Like
Thank you so much for sharing your knowledge really helped me a lot.
@ptrblck Is it normal to have the ROC curve like the image attached above? Usually, whenever I read papers or see over the GitHub they are moreover curvy.
Can you please give your thoughts on that?
I really appreciate your response
Often these curves have more points in the plane and are thus “curvier”.
I guess that your predictions might have very specific clusters, such that changing the threshold for the positive/negative predictions doesn’t create a lot of different FPR/TPR points.
1 Like
Okay thank you so much for the clarification