Hello,
This is my first time posting. I wrote a super basic feed forward network in an attempt to optimize a function. However, I noticed that it was not learning. So I decided to simplify the function as much as possible, while using the same essential architecture, and it’s still not learning.
Here is the network class:
class NeuralNet(nn.Module):
def __init__(self, alpha, in_dims,
fc1_dims, fc2_dims,out_dims):
super(NeuralNet, self).__init__()
self.in_dims = in_dims
self.fc1_dims = fc1_dims
self.fc2_dims = fc2_dims
self.out_dims = out_dims
self.fc1 = nn.Linear(self.in_dims, self.fc1_dims)
self.fc2 = nn.Linear(self.fc1_dims, self.fc2_dims)
self.fc3 = nn.Linear(self.fc2_dims, self.out_dims)
self.optimizer = optim.Adam(self.parameters(), lr=alpha)
# self.optimizer = optim.SGD(self.parameters(),lr=alpha,momentum=0.8)
self.device = T.device('cuda:0' if T.cuda.is_available() else 'cpu')
self.to(self.device)
def forward(self, state):
x = T.relu(self.fc1(state))
x = T.relu(self.fc2(x))
x = self.fc3(x)
return x
def choose_action(self, obs):
obs = T.tensor([obs],dtype=T.float,requires_grad=True).to(self.device)
action = T.relu(self.forward(obs))
return action.tolist()
def learn(self, loss):
self.optimizer.zero_grad()
loss = T.tensor([loss], dtype=T.float,requires_grad=True).to(self.device)
loss.backward()
self.optimizer.step()
def loss_func(self,target,arrow):
target = np.sum(target)
arrow = np.sum(arrow)**2
diff = (arrow-target)**2
loss = diff
return loss
and here is the driver code:
if __name__ == '__main__':
n_inputs = 1
n_outputs = 1
layer1 = 32
layer2 = 32
agent = NeuralNet(alpha=1e-5,in_dims=n_inputs,
fc1_dims=layer1,fc2_dims=layer2,
out_dims=n_outputs)
n_games = int(100)
done = False
n_epochs = 50
learn_iters = 0
n_steps = 0
score_history = []
avg_score = 0
best_score = 0
avg_score = 0
best_score = 0
for i in range(n_games):
score = 0
done = False
loss = 0
learn_iters = 0
while not done:
input_val = np.random.randint(0,500,size=1)*.1
act = agent.choose_action(input_val)
loss = agent.loss_func(input_val,act)
score += loss
agent.learn(loss)
learn_iters+=1
if learn_iters > 1e4:
done = True
print(i)
score_history.append(score)
avg_score = np.mean(score_history[-100:])
if score > best_score:
best_score = score
print('episode', i, 'score %.1f' % score,
'avg score %.1f' % avg_score,
'best score %.1f' % best_score)
x = [i+1 for i in range(len(score_history))]
print('learned:',learn_iters,' times')
plt.figure()
plt.plot(x,score_history)
plt.show()
As you can see, the NN is attempting to approximate y = x^2. “input_val” is a random number from 0 to 50, with 1 decimal point. The network outputs
act = agent.choose_action(input_val)
then the loss is calculated as the squared difference between input_val^2 and act. I am attempting to minimize this difference.
However, no matter how many training steps, no matter the learning rate, no matter the layer sizes, optimizer selection, activation functions, no matter what I do, I can’t get the average score to go down. The model is just not learning.
Here is a graph of the score history for 100 ‘games’
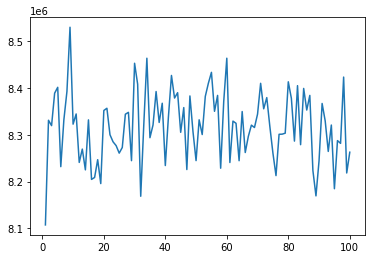
For this particular run, I called agent.learn() a total of 10001 times! and there’s barely any movement. Heck the score went up!
I’m convinced there’s something basic I’m missing, but I’ve scoured a ton of torch-based RL implementations and I can’t seem to find why my particular network isn’t training for such a basic function as y=x^2.
Any help is appreciated. Thank you!