Greetings! I think currently DDP is assuming all the processes share a same dataset no matter copying them on each node or stored in a NFS? Do we have any support for the case like the following picture?
If so, how to ensure the global shuffling?
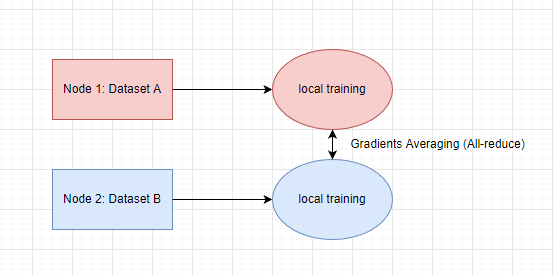
Greetings! I think currently DDP is assuming all the processes share a same dataset no matter copying them on each node or stored in a NFS? Do we have any support for the case like the following picture?
If so, how to ensure the global shuffling?