I don’t know why the prediction result is so bad,
My model wants to predict the 4 target values at the same time
but the prediction results are almost the same. it looks that their shape are the same but with different magnitude.
the following figure shows the prediction results. the top 4 lines are the target values and the bottom 4 lines are the predicted ones.
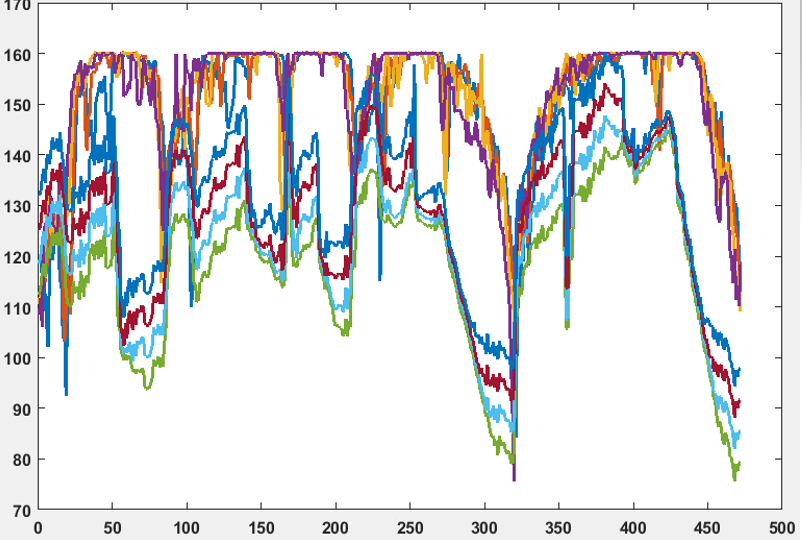
Here I add the main model and the training codes.
I worry if I make any mistake.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv_stem = nn.Conv2d(1, 8, 5, 2)
self.bn_stem = nn.BatchNorm2d(8)
self.relu = nn.ReLU(inplace=True)
self.conv_1 = nn.Conv2d(2, 6, 3, 2)
self.conv_2 = nn.Conv2d(24, 3, 3, 1)
self.conv_3 = nn.Conv2d(12, 3, 3, 2)
self.bn1 = nn.BatchNorm2d(6)
self.bn2 = nn.BatchNorm2d(3)
self.fc1 = nn.Linear(3 * 3 * 3 + 2, fc_num)
self.fc2 = nn.Linear(fc_num, 1)
self.dropout = nn.Dropout(p=0.5, inplace=False)
def forward(self, x_image, x_continuous):
x_image = self.conv_stem(x_image)
if with_attention:
x_image, att_stem = self.attn_stem(x_image) # attention
x_image = self.bn_stem(x_image)
x_image = self.relu(x_image)
x1 = x_image[:, 0:2, :, :]
x2 = x_image[:, 2:4, :, :]
x3 = x_image[:, 4:6, :, :]
x4 = x_image[:, 6:8, :, :]
x1 = self.conv_1(x1)
x1 = self.bn1(x1)
x1 = self.relu(x1)
x2 = self.conv_1(x2)
x2 = self.bn1(x2)
x2 = self.relu(x2)
x3 = self.conv_1(x3)
x3 = self.bn1(x3)
x3 = self.relu(x3)
x4 = self.conv_1(x4)
x4 = self.bn1(x4)
x4 = self.relu(x4)
merge_actv1 = torch.cat((x1, x2, x3, x4), 1)
x1 = self.conv_2(merge_actv1)
x1 = self.bn2(x1)
x1 = self.relu(x1)
x2 = self.conv_2(merge_actv1)
x2 = self.bn2(x2)
x2 = self.relu(x2)
x3 = self.conv_2(merge_actv1)
x3 = self.bn2(x3)
x3 = self.relu(x3)
x4 = self.conv_2(merge_actv1)
x4 = self.bn2(x4)
x4 = self.relu(x4)
merge_actv2 = torch.cat((x1, x2, x3, x4), 1)
x1 = self.conv_3(merge_actv2)
x1 = self.bn2(x1)
x1 = self.relu(x1)
x2 = self.conv_3(merge_actv2)
x2 = self.bn2(x2)
x2 = self.relu(x2)
x3 = self.conv_3(merge_actv2)
x3 = self.bn2(x3)
x3 = self.relu(x3)
x4 = self.conv_3(merge_actv2)
x4 = self.bn2(x4)
x4 = self.relu(x4)
x1_shape0, x1_shape1, x1_shape2, x1_shape3 = x1.shape
flatten_length = x1_shape1 * x1_shape2 * x1_shape3
# print('after_conv_layer3', x1.shape) # (batch_size,3,3,3)
x1 = x1.view(-1, flatten_length)
x2 = x2.view(-1, flatten_length)
x3 = x3.view(-1, flatten_length)
x4 = x4.view(-1, flatten_length)
# print('after_flatten', x1.shape) # (batch_size,27)
# print(x_continuous.shape) # (batch_size,5)
x_distance = x_continuous[:, 0]
angle1 = x_continuous[:, 1]
angle2 = x_continuous[:, 2]
angle3 = x_continuous[:, 3]
angle4 = x_continuous[:, 4]
# print('distance shape', angle1.shape) # (batch_size,)
x_distance = x_distance.view(-1, 1)
angle1 = angle1.view(-1, 1)
angle2 = angle2.view(-1, 1)
angle3 = angle3.view(-1, 1)
angle4 = angle4.view(-1, 1)
# print('distance shape', angle1.shape) # (batch_size,1)
x1 = torch.cat((x1, x_distance, angle1), 1)
x2 = torch.cat((x2, x_distance, angle2), 1)
x3 = torch.cat((x3, x_distance, angle3), 1)
x4 = torch.cat((x4, x_distance, angle4), 1)
# print('after_concat', x1.shape) # (batch_size,29)
x1 = self.fc1(x1)
x1 = self.relu(x1)
# x1 = x1.view(x1.size(0), -1)
x1 = self.dropout(x1)
x1 = self.fc2(x1)
x2 = self.fc1(x2)
x2 = self.relu(x2)
# x2 = x2.view(x2.size(0), -1)
x2 = self.dropout(x2)
x2 = self.fc2(x2)
x3 = self.fc1(x3)
x3 = self.relu(x3)
# x3 = x3.view(x3.size(0), -1)
x3 = self.dropout(x3)
x3 = self.fc2(x3)
x4 = self.fc1(x4)
x4 = self.relu(x4)
# x4 = x4.view(x4.size(0), -1)
x4 = self.dropout(x4)
x4 = self.fc2(x4)
# print('final_predited PL', x1.shape) # (batch_size,1)
out = torch.cat((x1, x2, x3, x4), 1)
# print('after_concat', x1.shape) # (batch_size,4)
return out
net = Net()
net = net.to(device)
# print(net)
if isSGD:
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
else:
optimizer = optim.Adam(net.parameters(), lr=0.001)
def RMSELoss(yhat, y):
# print(torch.sqrt(torch.mean((yhat-y)**2),0))
# print(torch.sqrt(torch.mean((yhat-y)**2),1))
return torch.sqrt(torch.mean((yhat - y) ** 2))
criterion = RMSELoss
# criterion = nn.MSELoss() # nn.CrossEntropyLoss()
# optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
losses = []
val_losses = []
running_loss = 0.0
print_time = 0
accmulated_amount_sample = 0
for epoch in range(num_epoch):
training_dataloader_batch_size = training_dataloader.batch_size
for i, data in enumerate(training_dataloader, 0):
inputs, labels, tr_angles, positions = data['image'], data['pls'], data['tr_angles'], data['positions']
inputs, labels, tr_angles, positions = inputs.to(device, dtype=torch.float), \
labels.to(device, dtype=torch.float), \
tr_angles.to(device, dtype=torch.float), \
positions.to(device, dtype=torch.float)
optimizer.zero_grad()
outputs = net(inputs, tr_angles)
# loss = torch.sqrt(criterion(outputs, labels))
loss = criterion(outputs, labels)
# print(loss) # tensor(107.8965, device='cuda:0', grad_fn=<SqrtBackward>)
loss.backward()
optimizer.step()
loss_value = loss.item()
# print('val_loss_value: ', loss_value)
running_loss += loss_value
losses.append(loss_value)
# break
epoch_loss_value = running_loss / (i + 1) # len_training = accmulated_amount_sample
print('[training epoch %d] loss= %7.6f' %
(epoch + 1, epoch_loss_value))
writer.add_scalar('Loss/Training', epoch_loss_value, epoch)
running_loss = 0.0
accmulated_amount_sample = 0
print_time += 1
if val_print_show_time == print_time:
print_time = 0
# val_running_loss = 0.0
with torch.no_grad():
for i, data in enumerate(validation_dataloader, 0):
val_inputs, val_labels, \
val_tr_angles, val_positions = data['image'], data['pls'], \
data['tr_angles'], data['positions']
val_inputs, val_labels, \
val_tr_angles, val_positions = val_inputs.to(device, dtype=torch.float), \
val_labels.to(device, dtype=torch.float), \
val_tr_angles.to(device, dtype=torch.float), \
val_positions.to(device, dtype=torch.float)
net.eval()
val_outputs = net(val_inputs, val_tr_angles)
val_loss = criterion(val_outputs, val_labels)
val_loss_value = val_loss.item()
writer.add_scalar('Loss/Validation', val_loss_value, epoch)
writer.add_scalars('Loss/Training&Validation',
{'Training': epoch_loss_value, 'Validation': val_loss_value}, epoch)
# val_running_loss += val_loss_value
# print('val_loss_value: ', val_loss_value)
val_losses.append(val_loss_value)
# print(validation_dataloader.batch_size)
print('[test epoch %d] val loss: %7.6f' %
(epoch + 1, val_loss_value)) # / validation_dataloader.batch_size
# val_running_loss = 0
parameters = net.named_parameters()
for name, param in parameters:
if 'bn' not in name and 'attn' not in name:
writer.add_histogram(name, param, epoch)
print('Finished Training')