Why there is an embedding layer before LSTMs. I see various reasons but every source tells something different. Some say to ignore padded zerous or create word vectors for LSTM’s input.
You need to give a bit more information to get useful response. What is your learning task? What’s your input, text?
An embedding layer is specific requirement for a LSTM. The requirement stems from the input. Basically all models using textual content to encode words or characters.
1 Like
Hi Chris, thanks for reply
I have built a image captioning model based on Tanti’s paper
I used 2 inputs for image and text data and concatenated them before the last dense layer. I do not use a softmax, i take the maximum logit from dense layer’s output to get the next word predicted
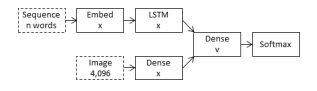
I had several experiments by changing embedding layer’s output dimension to 128, 256 and 512
As I have observed from my captions, As the dimension is increased, generated captions became more complex. But i am trying to understand the logic behind it