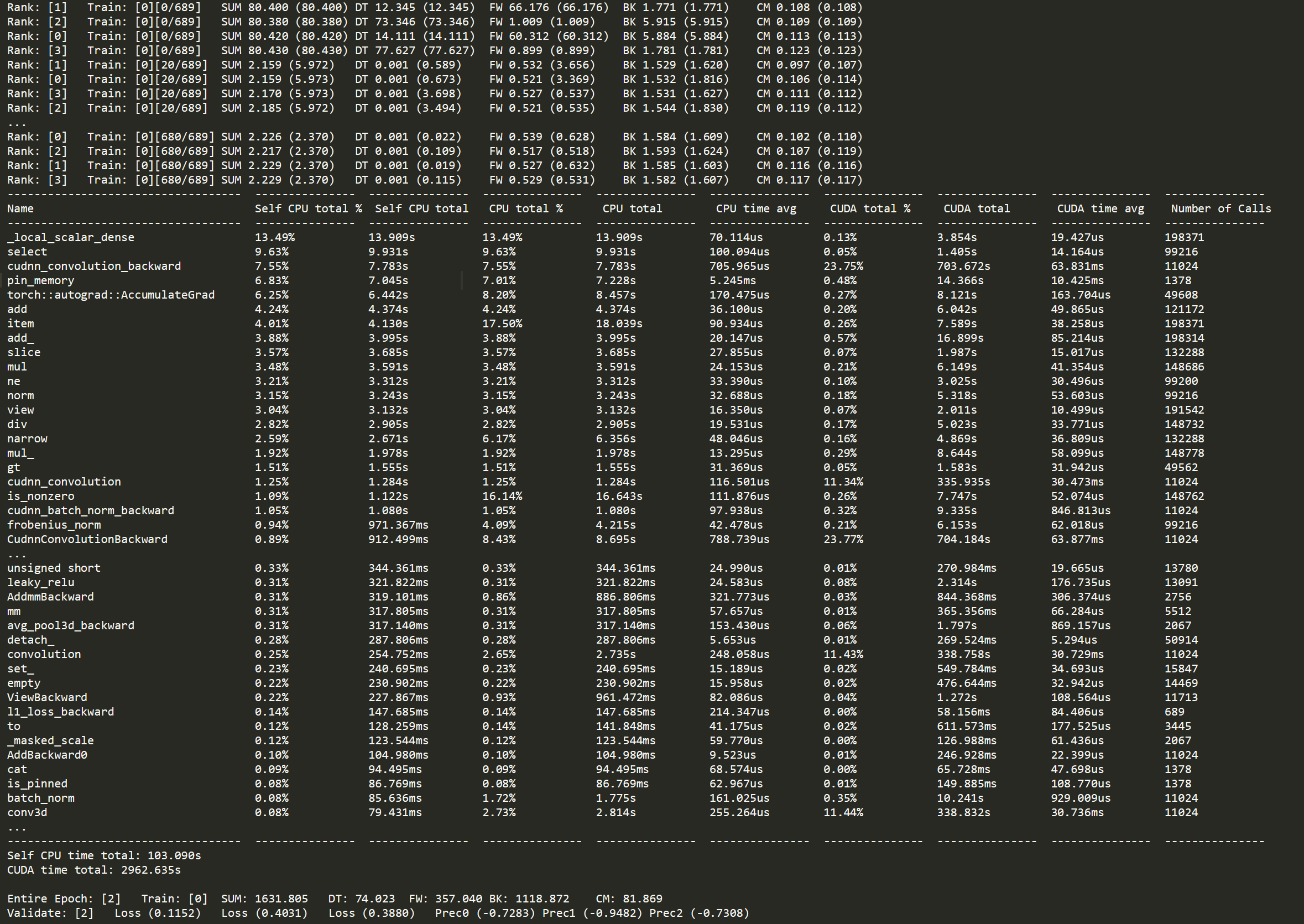
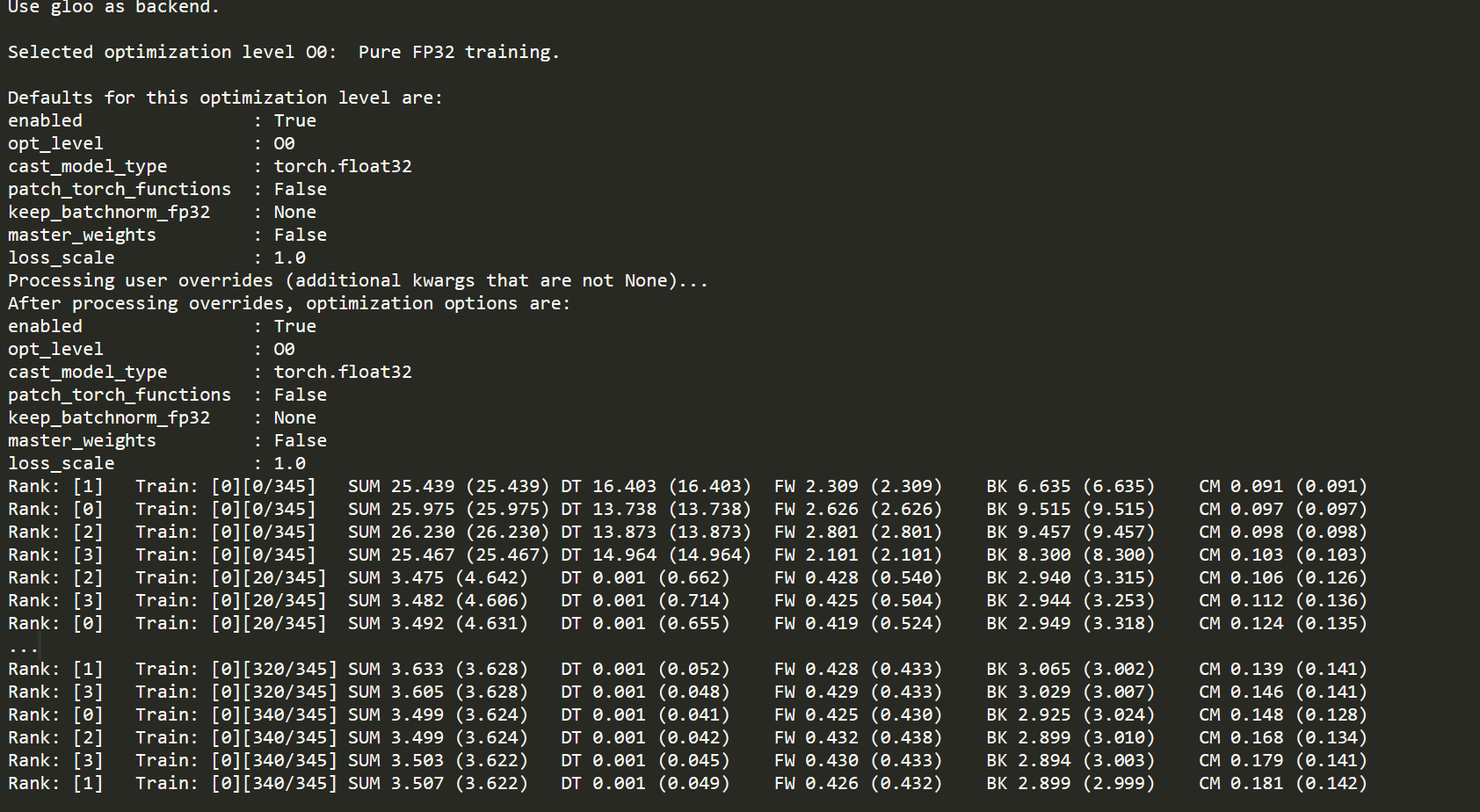
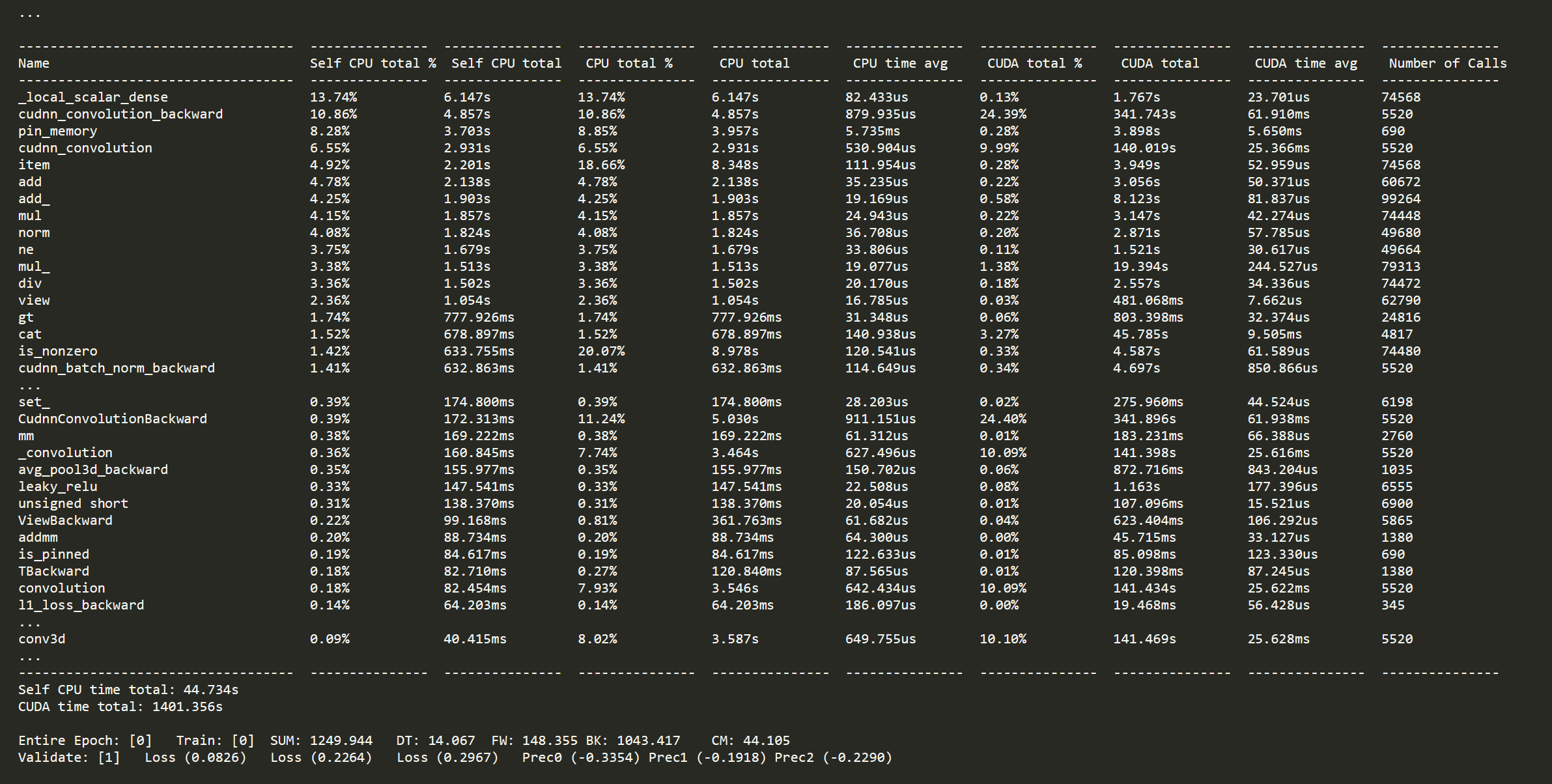
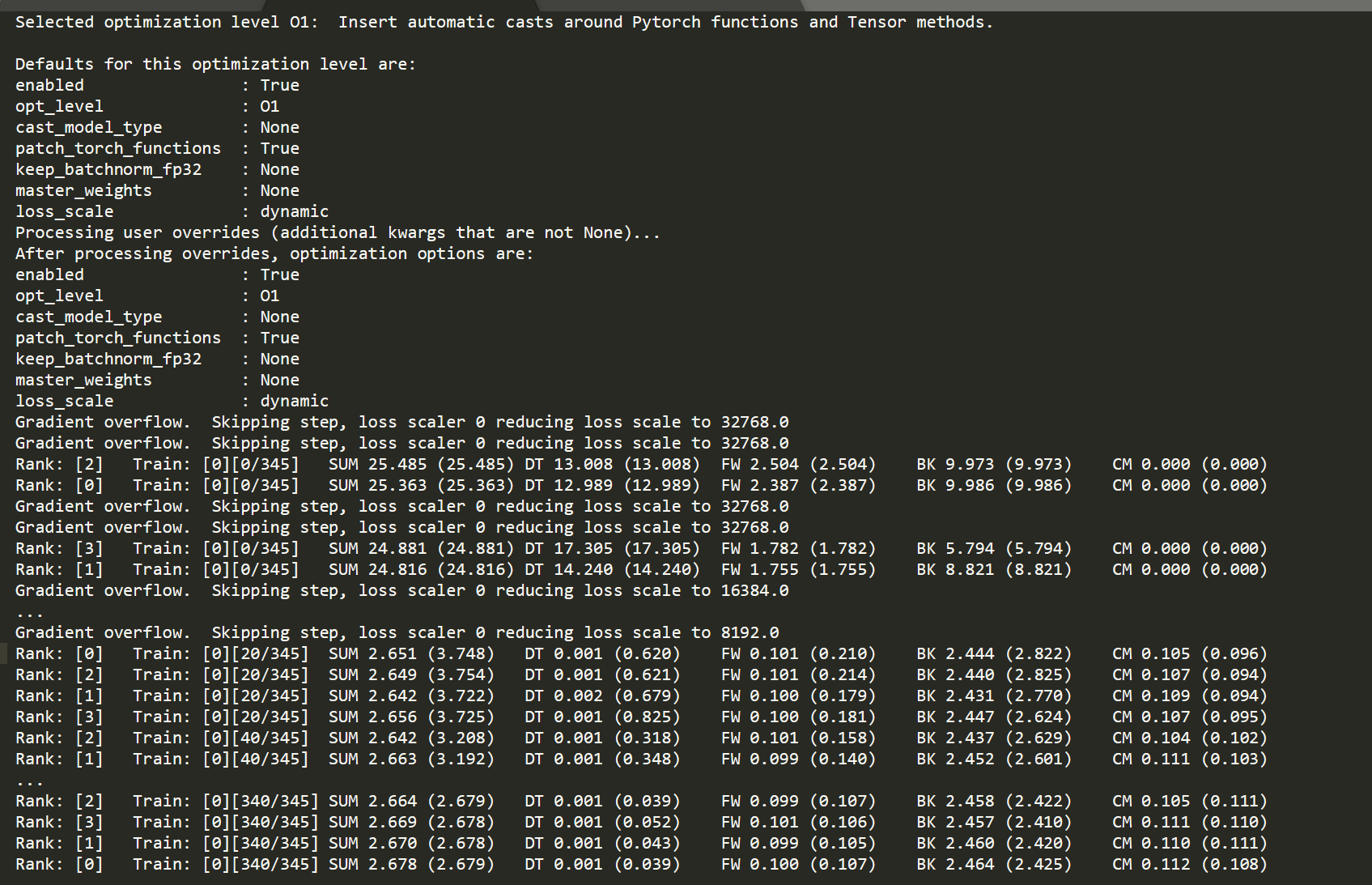
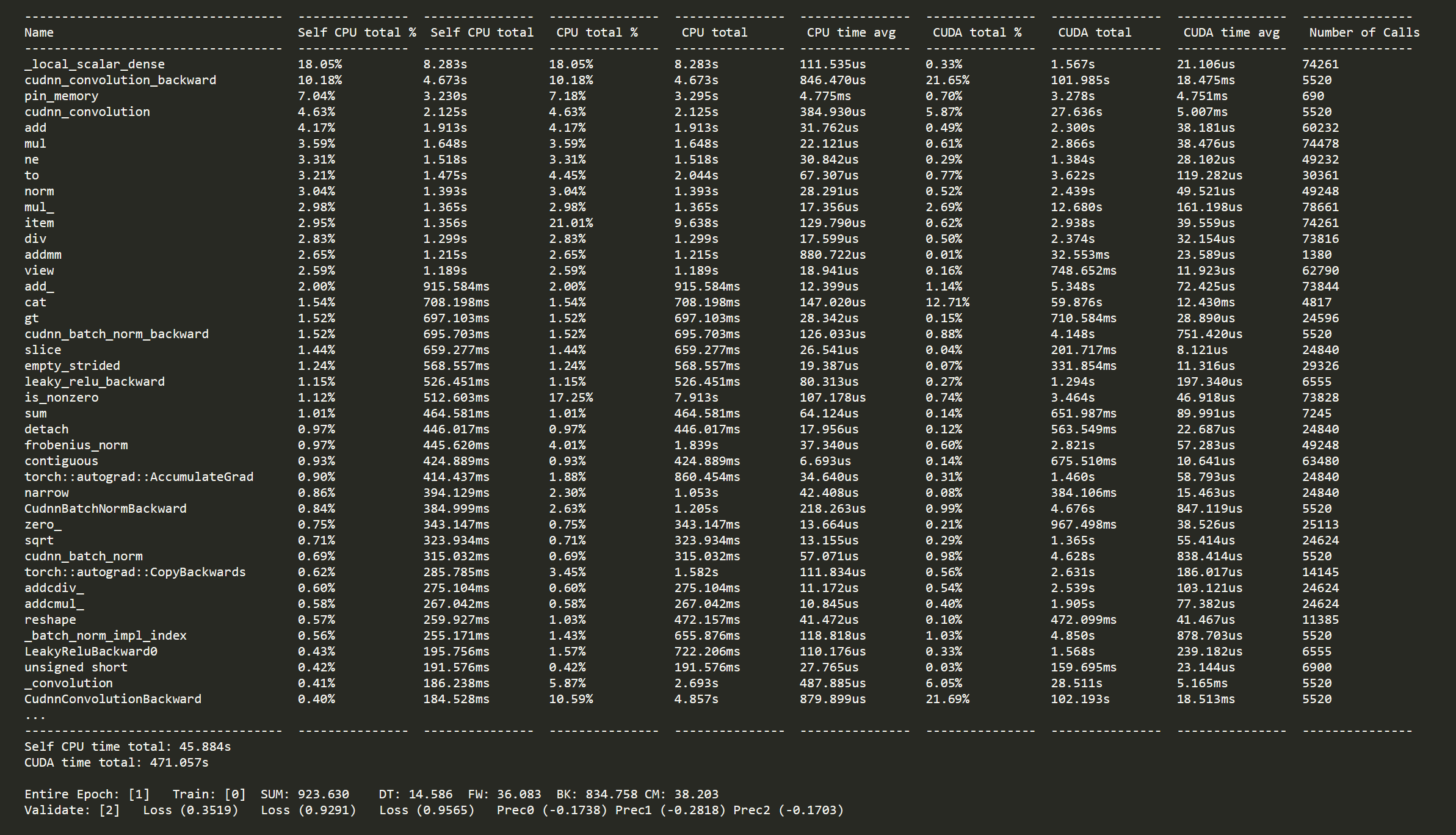
Notably, the problem only exists when batch size is equal to 1 (batch size = 4 is accelerated as predicted) and I tried two scales of the 3D CNN models. (The large model can only be trained with batch size =1 for it is too large.)
Question:
It seems that there exists a large portion of the execution time that is not related to computing.
Do you have any idea about it?
Why the total execution of 3D CNN in mixed precision is slower than the FP32 when batch size =1?
If you are manually timing CUDA operations, you would need to synchronize the code before starting and stopping the timer via torch.cuda.synchronize().
Also, the first CUDA operation will create the CUDA context etc. and will be slower than the following calls, so you should add some warmup iterations.
Thanks.
I have used torch.cuda.synchronize(), and there is about hundreds of iterations in one epoch with the same problem.
I will provide you the detailed results soon.
Both the forward and backward passes seem to see a speedup between O0 and O1.
Are you seeing that the complete training time in O1 is still higher than in O0?