
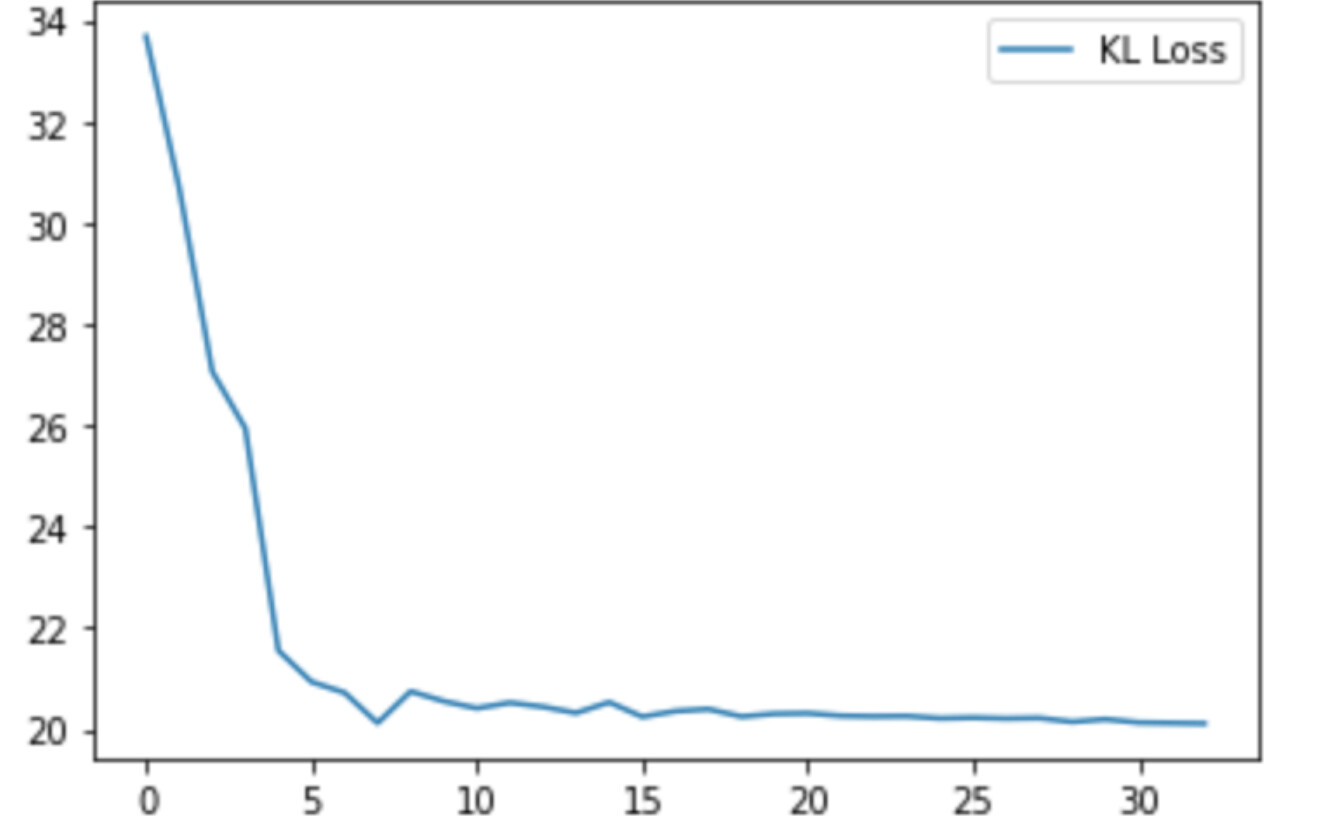
It seems like KL is not doing a good job at approximating this toy example or am I missing something?
Just to answer this, I’ve come to the conclusion that there’s sth wrong with the KL, here’s why.
Verbatim from KLDivLoss:
As with NLLLoss, the input given is expected to contain log-probabilities
and is not restricted to a 2D Tensor. The targets are interpreted as probabilities by default,
but could be considered as log-probabilities with log_target set to True.
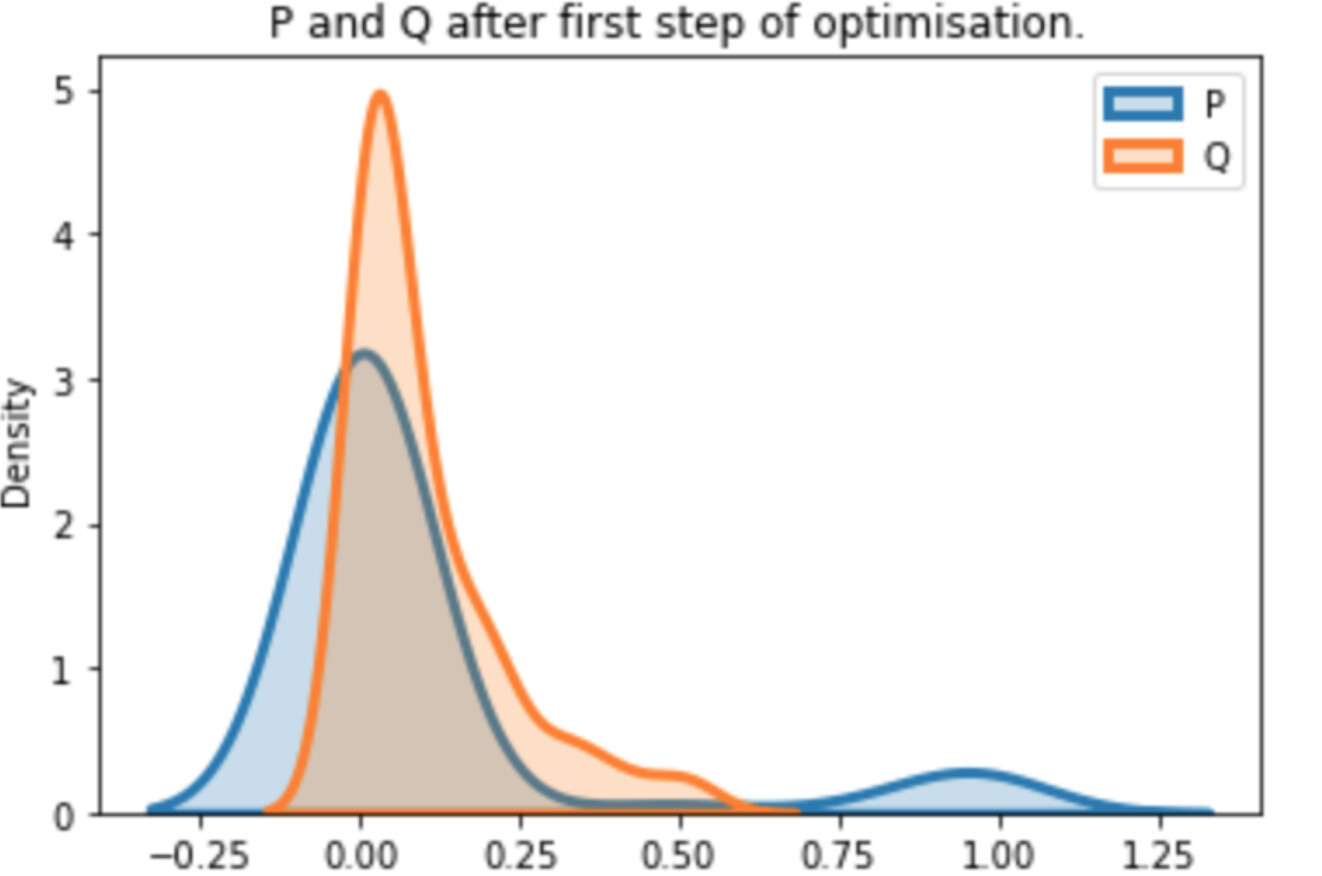
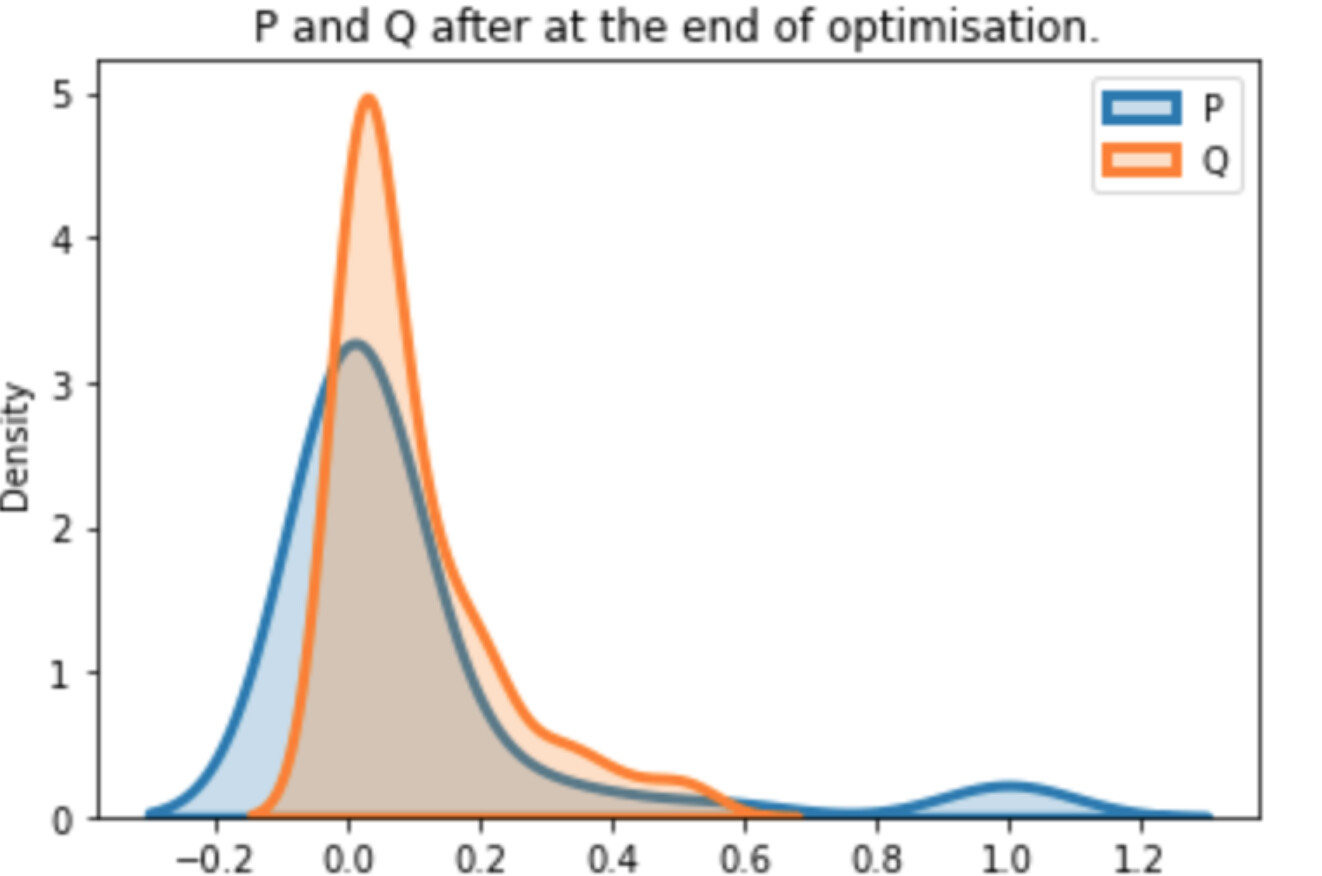
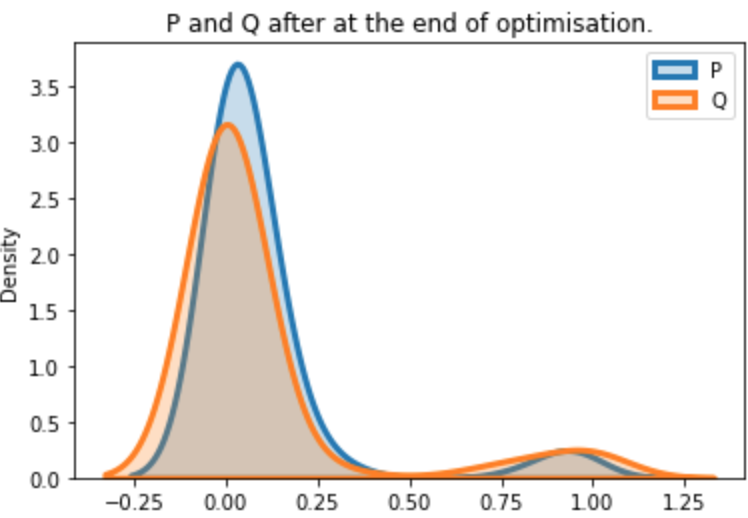
The above plots where generated when P = F.log_softmax(*) and Q = F.softmax(*). To this point KL is formed as F.kl_div(P, Q, reduction='batchmean') according to the exact definition of the docs.
The problem is the P = F.log_softmax(*) which basically destroys the approximation of Q and KL cannot recover.
The same problem is persistent even with the flag log_target=True where both P and Q are transformed via F.log_softmax(*).
And here’s the correct result when both P and Q are just outputs from F.softmax(*).
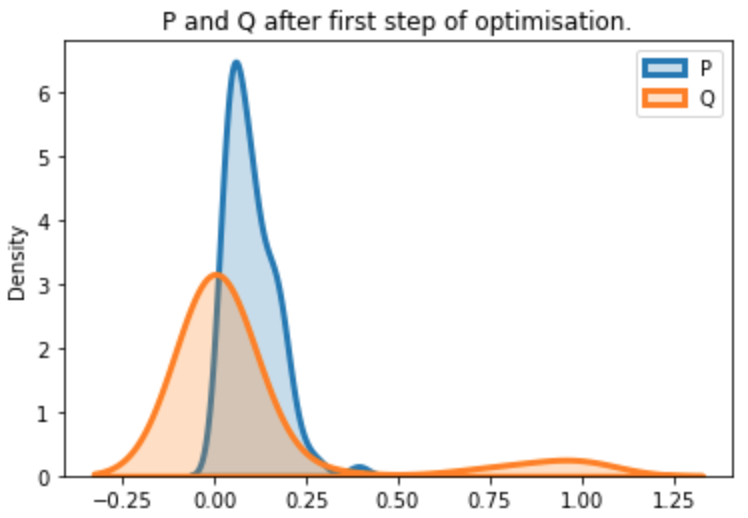
Can someone from the pytorch devs verify and correct this if that’s the case?